“那么,深度学习究竟如何应用在游戏上呢?”——在2017 GDC的一个深度学习小讲座上,一位戴黑框眼镜的听众待主讲人话音刚落便迫不及待地问道。如此没逼格、直白得近乎在钓鱼的问题自然是引得众人一阵狂笑。可惜演讲者显然对此准备不足,只能笼统地打了两圈太极。视角再度转回台下观众,他们的脸上大多都写着各国语言的失望……没错,其实即便嘴上不说,大家也都差不多是带着同样的问题来参会的。
2017年初,当VR(低端硬件)市场骤然降温时,众投资人和分析师们便试图说服大家:既然“VR元年”已过,那么今年的关注点就应该自然而然地转移到人工智能技术上。这种热点切换理论究竟有没有道理?人工智能对游戏产业是否存在立竿见影的决定性作用?通过本届游戏开发者大会(Game Developers Conference, GDC),很多人已经找到了自己的答案。
1. GDC,集大成
1.1 目标,旧金山!
太平洋时间2月27日清晨,一年一度的GDC展会如期在美国旧金山的Moscone 会展中心召开。在这场云集了全球游戏产业开发商的盛会上,人们带着成就心得,带着疑虑遐想,于三个会场、数十个礼堂以及上百个展台内热切地握手、交流、磋商、签协议……

图 1 Moscone会展中心的西区。
不过GDC并不同于普通的展会,其最重要的议程并不是厂商摆摊子让人买票进来逛,而是数百场专业的峰会讲座。在官方网站、参展手册上和大堂内,都能找到这些令人眼花缭乱的开课信息。它们时间相互冲突,领域五花八门——或讨论编程、引擎,或关注音频、策划,或研究手游、端游,或点拨社区、营销,授课者亦无不是有丰富经验的资深从业人员。要说人们参加GDC最大的遗憾,大抵都是分身乏术,无法同时兼顾多门感兴趣的课程了吧。

图 2 GDC的周一“课程表”。注意每个时间段(紫色标题分割)均提供了大量互斥的课程。
1.2. AI在哪里?
本届GDC的峰会照旧提供了“AI Summit”。不过,这可和当今炙手可热(贬义词无误)的AI,即以深度学习为代表的机器学习技术不是一回事。我们不妨来看几个演讲的题目:
l AI Arborist: Proper Cultivation and Care forYour Behavior Trees(AI树艺家:给予你亲爱的行为树以恰当的栽培和关爱)
l Beyond Framerate: Taming Your Timeslice ThroughAsynchrony(帧率之外的故事:如何用异步方式调教时间片)
l Behavior is Brittle: Testing Game AI(行为无法承受之轻:游戏AI测试)
l Bring Hell to Life: AI and Full Body Animationin DOOM(人间炼狱:《毁灭战士》中的AI和全身动画)
看起来,这里所谈论的“AI”更倾向于传统游戏设计和开发流程中所涉及的自动行为与刺激反馈系统。在认真听了数个AI峰会讲座后,我最终还是未能从中嗅到一丝机器学习的气息……
尽管顶着“AI”名号的讲座却没当今语境中的人工智能,但GDC官方所筹办的课程也并非完全没照顾前沿内容。有一堂名为“Math for GameProgrammers”的系列讲座,在一个会厅里从早上到晚,并涵盖了这么一些议题:
l Noise-Based RNG(基于噪声的随机数生成器)
l Dark Secrets of the RNG(随机数生成器暗藏玄机)
l Predicting Projectiles(预测抛体)
l Ranking Systems: Elo, TrueSkill and Your Own(三套排名匹配算法:Elo、TrueSkill以及YourOwn)
l The Math of Deep Learning(深度学习之数学)
l Harmonic Functions and Mean-Value(谐波函数与均值)
注意到没,在这堆让不少人看名字就不太想去的讲座中,堂而皇之地安排了一门深度学习之数学基础三十分钟速成班。不愧是游戏业集大成的顶级盛会!而那堂课也毫无悬念地提前二十分钟就排起了大长队:队列延伸出走廊,在大堂里摆出不知哪种写法的“回”字来。络绎不绝加入队尾的人们也交头接耳不断:
-“这是深度学习那堂课的队列吗?”
-“Holy shit!”
-“大家为啥都来听这个啊?”
-“这么多人排队,姑且进去瞧瞧吧……”
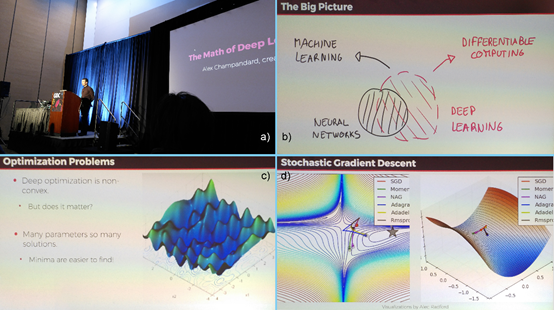
图 3 “The Math of Deep Learning”小讲座。
a)主讲人Alex Champandard;b) 深度学习与神经网络之关系图;
c) 深度网络中的局部极值依然具有效力;d) 不同优化算法的收敛速度比较。
30分钟的小讲座在攒动的人头和高举着拍照的手机中一晃而过。一言以蔽之,我可能上了一堂假的数学课。这门定位模糊的讲座全程没呈现出一个公式,也不涉及任何逻辑推导,但却直接抬出了不少凸优化的结论。试图速成的初心者难以跟上其节奏,懂模式识别的听众又找不到痛点。诚然,用短短半小时来介绍“深度学习之数学”这样的命题完全不切实际,但蜂拥而至的GDC听众与本文导语所描绘的答疑环节,又毫无疑问地展示出了组织者的良苦用心:既然大家都对大红大紫的深度学习技术充满了殷切的期盼,那么2017年不开设个相关的官方议程的确有些说不过去——哪怕,稍有常识的人都会看出,将深度学习嫁接至游戏设计和开发的流程中还真是块有待开垦的疆域。
不过,用功的幸运掘金者总是有的。
2. 绿色帝国之嬗变
2.1. 核武野心家
GDC的金字招牌在吸引全世界玩家和游戏开发者的同时,也无形中为硬件厂商们打造了一套价廉物美的宣传平台。不过,真正有野心的公司是决不会满足于在GDC的规划展区里扔个几平米的小隔间的。财大气粗的NVIDIA,此次不仅赞助了16个议程,还将战线推向了毗邻Moscone会展中心的马奎斯万豪酒店,在二楼包场开课。
就游戏显卡而言,尽管本人从RIVA128一直用到了现在的GeForce 1070,但却从来都不是个N粉。然而不得不承认,NVIDIA的确是一个非常会捕捉市场机会的硬件公司。Tegra移动片上系统(SoC)也好,基于Intel Atom处理器的离子平台也好,每次出手哪怕不能引领未来潮流,也至少都会将市场格局狠狠搅合一番——基于显卡大规模并行运算的统一计算架构(Compute Unified Device Architecture,CUDA)当然也不例外。

图 4 以C语言为例,CUDA引入了新的并行编程理念。
游戏显卡的流处理单元数以千计,浮点运算能力又是强项,故在上面动点“歪脑筋”并不奇怪。于是早在2007年,NVIDIA就提出了CUDA的概念,以期能将这种功耗和发热都非同小可的“核弹”硬件推向科学计算领域。而回过头看,NVIDIA之所以能贯彻这份壮志,除了自身的奋斗,也和历史的行程不无干系。
2011年前后,由比特币引领的区块链技术曾掀起过一番借助显卡运算获取数字货币牟利(挖矿)的狂潮。这也是基于显卡的并行运算首次从学术领域走向商品化、市场化。而至于这第二波机遇,则正是本文主要探讨的深度学习技术。
事实上,深度学习就是上世纪70年代所提出的人工神经网络的延续和推广。这种包含大量隐藏层的分类器胃口极大,需要百万以上量级的训练样本数,才能获得甚高的预测精度和泛化能力(详见第三节)。而类似卷积神经网络(Convolutional Neural Network,CNN)所涉及的卷积和矩阵运算,简直就是为GPU量身打造的;使用GPU来训练深度网络,其运算效率能达到CPU的数十倍。换言之,如果显卡运算的潜能从未被发掘,则无法实现这一量变到质变的过程,深度学习的这波浪潮大概还得再等十年。嗅觉敏锐的NVIDIA,为此也特别成立了深度学习研究院(Deep LearningInstitute,DLI),以便在促进技术进步的同时,巩固、扩张市场,多多推销自家坐地起价的专业运算显卡。

图 5 NVIDIA Tesla P100运算专用显卡($5000~$9000/片)的性能介绍。
2.2. 深度课堂
一方面是倡导显卡加速运算、推动深度学习发展的急先锋,另一方面又是在游戏技术领域耕耘了二十余载的顶级硬件公司,这两份资质重叠在一起,便成就了当前NVIDIA在游戏领域不遗余力推广深度学习技术的勤奋姿态。本次旧金山之行,我有幸参加了DLI组织的深度学习讲习班(DLI Workshop)。授课的环境很轻松,难度也不大。前半部分为门外汉讲解深度学习的来龙去脉和基本概念,后半部分则是上机实验:利用即见即所得的深度学习GPU训练系统(Deep Learning GPU Training System,DIGITS,https://developer.nvidia.com/digits),以交互式、即见即所得的界面操作MNIST手写体数字的样本分类,并顺带灌输数据预处理和网络参数调节的概念。

图 6 DLI组织的深度学习讲习班现场。
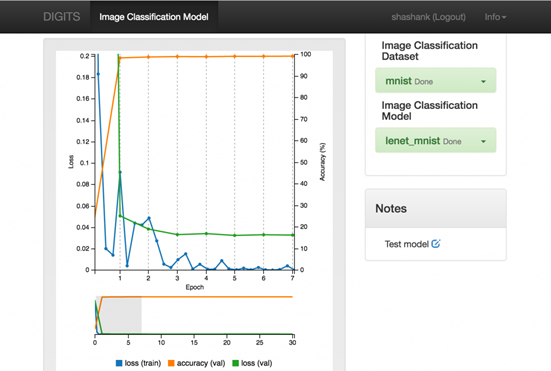
图 7 纯网页交互界面的NVIDIADIGITS(图为MNIST数据集的训练结果)。
在四小时左右的研习课上,NVIDIA的老师还提及了多项在游戏设计上普及深度学习工具的可能思路:
l 预测。推断对手的下一步行为。
l 操控。指挥载具的运动。
l 进攻/逃逸选择。在RPG游戏中用正向和负向行为训练神经网络,以实现自动决策。
l 威胁评估。根据当前信息预测威胁状况,并采取适当的行动。
l 反作弊。鉴别行为和事件是否构成作弊或滥用。
l 用户画像。根据多元的用户数据甄别不同类型的玩家。
l 信息审查。判断玩家是否出言不当。
此外,课上也穿插介绍了一些深度学习之于游戏应用的具体案例,其中有数年前的旧闻,也有近期的新资讯:
l 将八个移动方向和按键作为输入,用深度强化学习训练玩Atari和FC游戏的AI,并最终成为远胜人类玩家的绝顶高手。
l 利用生成对抗网络(Generative Adversarial Network)设计背景资源和游戏地图。
l 《闪电战3》(Blitzkrieg 3)的AI玩家“Boris”。是为全球首个基于神经网络开发的即时战略游戏AI。
可见,NVIDIA的确是带着一颗游戏之心来经营的这堂研习课,即便没有森罗万象,也算是从理论到实践面面俱到了。而推广DIGITS傻瓜式系统的目的,自然亦是为了最大限度降低深度学习的上手门槛,以便让缺乏模式识别理论基础的开发者能将其作为一个能信手拈来的工具使用,从而把更多精力投入到系统设计上。
当NVIDIA逐渐从与ATi/AMD的对标绞肉竞争中抽身出来之后,行业嗅觉敏锐的“战术核显卡”厂商便很快将触手伸向了深度学习、自动驾驶等领域,以前沿技术积极倡导者的姿态完成了自身进化。然而,对于普通游戏从业者而言,这些几经包装的新技术真的就是那么触手可及吗?
或许应该换个问法:所谓的“人工智能”技术,现阶段对游戏产业的影响力究竟能延伸到哪个层面?
3. 智能的本愿
3.1. 新瓶装旧酒
其实对于很多人而言,“人工智能”、“机器学习”和“深度学习”这三个词,都是从AlphaGo击败李世乭之后才开始高频接触的。由于新闻媒体的知识结构和水平有限,在传播时又刻意夸大内容的冲击力,最终便导致了报道上的偏差,以致概念误用混用。
实际上,人工智能是个很大的概念,可不严格地划分为强人工智能(General AI)和弱人工智能(Narrow AI):
l 强人工智能:可自主推理和解决问题、拥有类似或超越人类智慧的机器(如终结者,目前尚不存在)。
l 弱人工智能:能模仿或超越人类执行特定任务的技术(如人脸识别、自然语言处理等)。
而机器学习,是一种实现人工智能的方法,且当前还只隶属于弱人工智能的范畴。至于深度学习、强化学习、迁移学习等,则仅仅是机器学习中的技术子集。

图 8 人工智能等概念的关系图(从外到内依次是人工智能、机器学习、表征学习、深度学习)。
于是在咬文嚼字三百字之后,便可理解为什么在GDC的AI峰会上没有跟风设立深度学习的相关议程,而有所涉及的内容也只谈“Deep Learning”了。而在继续讨论深度学习对游戏产业的作用域之前,我们最好再花点时间来梳理一下深度学习的技术细节和长短板。
如前所述,深度学习实质上为人工神经网络的延续和推广。得益于高度非线性的特质,神经网络被誉为万能拟合器;只要给予了足够的训练样本,神经网络通常都能达到很高的预测精度。而隐藏层越多,模型的非线性程度就越高,所能处理的特征维度和问题复杂程度也相应获得提升。
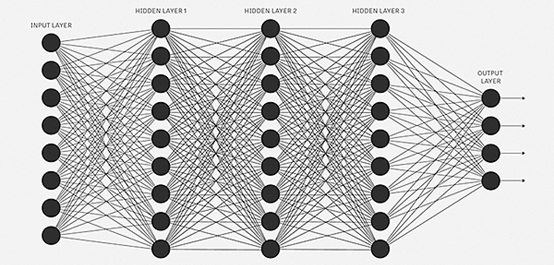
图 9 典型的人工神经网络结构。其中,输入和输出层之间的三层均为隐藏层,全网共包含23328个参数。
不过,在相当长的一段时间内,囿于算法与硬件算力的限制,神经网络的潜力无法彻底释放。彼时,人们更青睐奥卡姆剃刀法则,主动降维,以模型解释优雅的分类器(如支持向量机)处理各类模式识别问题。
人总是实际的。如果暴力真的能解决好问题,甚至获得令人称奇的结果,那么高傲的自尊迟早会被舍弃掉。2010年后逐渐兴起的深度学习说白了就是这么一回事。借助廉价而算力暴涨的计算机硬件,以巨量样本训练几十、几百层的神经网络,调节数以亿计的权值参数值,最终获得出色的预测精度与泛化性能。
图 10 该不等式由Blumer等人于1989年提出,它揭示了模型复杂度(VC维)与样本量(m)和错误率(ε)之间的关系。过于复杂的模型在有限的样本下会出现维数灾(Curse of Dimensionality),但足够大的样本量将允许甚高复杂度的模型。
这也就意味着,在机器学习的方法学上,短短十年间就出现了重大的思考范式转移:
|
|
过去 |
现在 |
|
特征维度 |
主张降维 |
提倡升维 |
|
分类模型 |
易解释、低复杂度 |
难解释、高复杂度 |
|
样本需求 |
小样本即可 |
极度倚重大样本大数据 |
|
计算资源 |
要求不高 |
相当依赖 |
当然,比起以前针对不同场景慎重选择、比较分类算法的“奇技淫巧”,如今相对通用的深度学习工具,其总体指导思路从某种意义上来说的确足够简单清晰:多就是好,大就是美,亿万的节点,亿万的光辉。反正无论如何都在深度学习框架下实现,于是预测精度不够高大概率是模型设计不够复杂的错,而且更可能是样本量不足的锅。现各大厂商都视自家的大数据样本为至高机密,便是一佐证。
但机器学习中也有一个颇具哲理性的论断,即没有免费午餐定理(No Free Lunch Theorem)。其正规解释是,不存在某种算法,对所有问题都最适合;若一算法对某些问题能解决得非常出色,那么必存在另一些问题,使该算法甚至不如随机猜测。
深度学习自然不会例外。当它被戴上“人工智能”的宝冠大受追捧时,肯定会有具体应用拔下皇帝的新衣。同理,假以“人工智能”盲目地在游戏产业的方方面面尝试深度学习算法,也注定会被用户讥讽道——
3.2. 甚矣,汝之不惠
深度学习,或者说神经网络最为人诟病的一点,便是其极端的非线性性所导致的黑箱效应。使用者只能把它当作一个魔盒来对样本变戏法,获取高分类精度,而无法反推样本中是何种因素导致了这样的预测效能。简而言之,知果不知因,知其然而不知其所以然。例如,基于深度网络去处理游戏中的用户消费数据,并得到了分析结果,我们却很难从中获知究竟是哪些维度的知识对结果产生了如此至关重要的影响,因而也无法促进游戏的营收(这里只讲因果分析,不谈推荐算法)。
然而,目前整个业界似乎都被“人工智能”铺天盖地的宣传所冲昏了头脑,以至于对这种不求甚解都报以得过且过的态度。诚然,对于特定类型的任务(如生物特征识别),给定输入后能提供精确的分类输出就足够了,但这并不能让我们自己变得更聪明。AlphaGO在战胜顶级围棋大师后,人们也很难从其落子规律中找到提升自身棋力的方法。
讽刺的是,当每个神经网络的科普讲座都试图从神经元细胞的生理结构来自证这种类脑计算的合理性时,可曾想到过有上千年历史的神经科学一刻都未停止过对人脑智慧根源的孜孜探求。要知道,即便当前最复杂的深度网络节点数已达百万量级,而人脑可是有千亿量级的神经元总数啊。

图 11 一张简单描述左脑外侧皮层部分功能分区的示意图
当我们清醒地审视当前的计算机系统时,就会发现这一切其实并没那么特别。纵使深度学习的解决方案乃至专用运算芯片的效率再高,它们依然是运行在电子元器件上的人类编写好的程序。它们或许在特定认知任务上执行得比人类更好,但归根结底还停留在单一目标的层面上。它们没有情感、缺乏自我意识,充斥着人类和机器的双重缺陷。至少,在可预见的很长一段时间内都还将是如此。
所以,我们不妨先省省力气,少谈点人工智能。游戏从业者如果需要执行极高精度的分类任务,或自动化地构建高质量的图形资源,那么尽可以采用成熟的卷积神经网络、生成对抗网络等技术。而倘若只需要对行业数据、用户数据等进行定量分析,并同时关注输入变量的重要诱因维度,那么也完全可以使用传统、易解释的模型——说不定一个线性分类器就够格了。总之,按需选择最称手的工具即可。对深度学习的未来大可畅想,但毋神话。
言已至此,我们不妨再回过头重新审视一下GDC 2017。在总共五天的“课程表”上,前两天都是去年广受好评的虚拟现实开发者大会(VirtualReality Developers Conference,VRDC)。相对于国内甚嚣尘上的“VR寒冬论”(对低端硬件而言),从硅谷到GDC会场内都感受不到任何萧条衰败。人们积极地总结、讨论、交流VR的开发细节和新兴玩法,对未来充满了热切的期盼。今年的GDC游戏颁奖典礼,甚至还新设了“最佳VR游戏奖”。事实上,VR更多的是一套完整的体验型商品,和现阶段仅仅作为工具存在的深度学习完全不是一个层面的内容;比较其热度,在概念上就没有意义。VR产品自然会涉及到语音识别、手势识别等深度学习的运用场所,但两者之间很难说存在相互促进依存、或相互对立不调的并列关系。VR在硬件、标准和协议上还大有文章可做,而其内容生产更是一片蓝海。因此,诸如2016年器重VR、2017年关注深度学习、2018年又是AR之流的非此即彼的热点切换理论且不说在全球范围内没有严格的数据支撑,从技术投资的角度来讲也难站住脚。
图 12 VRDC期间专用于探讨VR/AR游戏相关议题的Moscone会展中心北区135号厅。
在科幻作品中,虚构的人工智能总是表现出人类一般的思维模式和谈吐,它们或与人和谐共处,或致力于清算旧世界。但此等光鲜形象的背后,实际上却也是人类劳动的代替践行者——无论是正向还是负向的工具。是的,工具,这便是人工智能的本愿。当人们在2017年就迫不及待地将科幻作品中尚属小儿科的深度学习进行图腾化膜拜时,憧憬的列车迟早会在技术铺就的铁道上脱轨。而智者对智能的探索,肯定是贯彻始终的理性思考与稳步前行。
至于关注深度学习的游戏从业者,还有一个更现实也更有趣的目标等着他们。瞄准旧金山,我们2018年的GDC展会再见。
(本文来自VR 新观察)