经常写文章的小白们会遇到这样的问题,知道想表达的意思,想出了大概描述的词汇,但就是缺乏完整漂亮的句子,也许曾经在某个地方看到过,但是找不到了。另外一种情况,阅读了大量的报告,用的时候想到了其中的某个结论或者数据,想要追根溯源却有点难。可惜word软件不提供在一堆文件里查找的功能,也没有类似于正则表达式的检索方法,只好自力更生来实现了。
python大法好。
依赖的包:python-docx
安装:pip install python-docx
引用:import docx
.docx文件的结构比较复杂,分为三层,1、Docment对象表示整个文档;2、Docment包含了Paragraph对象的列表,Paragraph对象用来表示文档中的段落;3、一个Paragraph对象包含Run对象的列表,用下面这个图说明Run到底是神马东西。
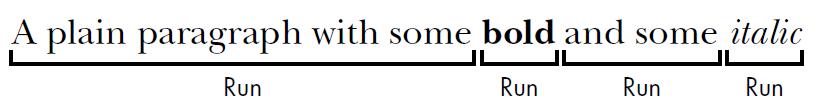
Word里面的文本不只是包含了字符串,还有字号、字体、颜色等等属性,都包含在style中。一个Run对象就是style相同的一段文本,新建一个Run就有新的style。
下面是一些简单的演示:
1 >>> import docx 2 >>> doc = docx.Document('D:projectpythonsearchdocxdemo.docx') 3 >>> doc 4 <docx.document.Document object at 0x0000000003277B40> 5 >>> len(doc.paragraphs) 6 7 7 >>> doc.paragraphs[0].text 8 u'Document Title' 9 >>> doc.paragraphs[1].text 10 u'A plain paragraph with some bold and some italic' 11 >>> len(doc.paragraphs[1].runs) 12 5 13 >>> doc.paragraphs[1].runs[0] 14 <docx.text.run.Run object at 0x00000000032C8710> 15 >>> doc.paragraphs[1].runs[0].text 16 'A plain paragraph with' 17 >>> doc.paragraphs[2].runs[0].text 18 'Heading, level 1' 19 >>> doc.paragraphs[1].runs[1].text 20 ' some ' 21 >>>
当然,也可以写一个简单的方法,读取文档中的所有文字,不管格式。
1 import docx 2 3 def readDocx(docName): 4 fullText = [] 5 doc = docx.Document(docName) 6 paras = doc.paragraphs 7 for p in paras: 8 fullText.append(p.text) 9 return ' '.join(fullText)