Description
In a certain course, you take n tests. If you get ai out of bi questions correct on test i, your cumulative average is defined to be
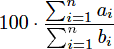
.
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop any k of your test scores. Suppose you take 3 tests with scores of 5/5, 0/1, and 2/6. Without dropping any tests, your cumulative average is . However, if you drop the third test, your cumulative average becomes
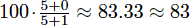
.
Input
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, 1 ≤ n ≤ 1000 and 0 ≤ k < n. The second line contains nintegers indicating ai for all i. The third line contains n positive integers indicating bi for all i. It is guaranteed that 0 ≤ ai ≤ bi ≤ 1, 000, 000, 000. The end-of-file is marked by a test case with n = k = 0 and should not be processed.
Output
For each test case, write a single line with the highest cumulative average possible after dropping k of the given test scores. The average should be rounded to the nearest integer.
Sample Input
3 1 5 0 2 5 1 6 4 2 1 2 7 9 5 6 7 9 0 0
Sample Output
83 100
Hint
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
Source


1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 #include<math.h> 6 #include<stdlib.h> 7 using namespace std; 8 #define N 1006 9 int n,k; 10 double ratio; 11 struct Node{ 12 double a,b; 13 bool friend operator <(Node x,Node y){ 14 return x.a-ratio*x.b>y.a-ratio*y.b; 15 } 16 }node[N]; 17 bool solve(double mid){ 18 ratio=mid; 19 sort(node,node+n); 20 double sum1=0; 21 double sum2=0; 22 for(int i=0;i<n-k;i++){ 23 sum1+=node[i].a; 24 sum2+=node[i].b; 25 } 26 return sum1/sum2>=mid; 27 } 28 29 int main() 30 { 31 while(scanf("%d%d",&n,&k)==2 && n+k!=0){ 32 for(int i=0;i<n;i++){ 33 scanf("%lf",&node[i].a); 34 } 35 for(int i=0;i<n;i++){ 36 scanf("%lf",&node[i].b); 37 } 38 double low=0; 39 double high=1; 40 for(int i=0;i<1000;i++){ 41 double mid=(low+high)/2; 42 if(solve(mid)){ 43 low=mid; 44 } 45 else{ 46 high=mid; 47 } 48 } 49 printf("%.0lf ",high*100); 50 } 51 return 0; 52 }
乍看以为贪心或dp能解决,后来发现贪心策略与当前的总体准确率有关,行不通,于是二分解决。
依然需要确定一个贪心策略,每次贪心地去掉那些对正确率贡献小的考试。如何确定某个考试[a_i, b_i]对总体准确率x的贡献呢?a_i / b_i肯定是不行的,不然例子里的[0,1]会首当其冲被刷掉。在当前准确率为x的情况下,这场考试“额外”对的题目数量是a_i – x * b_i,当然这个值有正有负,恰好可以作为“贡献度”的测量。于是利用这个给考试排个降序,后k个刷掉就行了。
之后就是二分搜索了,从0到1之间搜一遍,我下面的注释应该很详细,不啰嗦了。
1 #ifndef ONLINE_JUDGE 2 #pragma warning(disable : 4996) 3 #endif 4 #include <iostream> 5 #include <algorithm> 6 #include <cmath> 7 #include <iomanip> 8 using namespace std; 9 10 #define MAX_N 1000 11 int n, k; 12 double x; // 搜索过程中的正确率 13 struct Test 14 { 15 int a, b; 16 bool operator < (const Test& other) const 17 { 18 return a - x * b > other.a - x * other.b; // 按照对准确率的贡献从大到小排序 19 } 20 }; 21 Test test[MAX_N]; 22 23 // 判断是否能够获得大于mid的准确率 24 bool C(double mid) 25 { 26 x = mid; 27 sort(test, test + n); 28 double total_a = 0, total_b = 0; 29 for (int i = 0; i < n - k; ++i) // 去掉后k个数计算准确率 30 { 31 total_a += test[i].a; 32 total_b += test[i].b; 33 } 34 35 return total_a / total_b > mid; 36 } 37 38 ///////////////////////////SubMain////////////////////////////////// 39 int main(int argc, char *argv[]) 40 { 41 #ifndef ONLINE_JUDGE 42 freopen("in.txt", "r", stdin); 43 freopen("out.txt", "w", stdout); 44 #endif 45 while (cin >> n >> k && (n || k)) 46 { 47 for (int i = 0; i < n; ++i) 48 { 49 cin >> test[i].a; 50 } 51 for (int i = 0; i < n; ++i) 52 { 53 cin >> test[i].b; 54 } 55 56 double lb = 0; double ub = 1; 57 while (abs(ub - lb) > 1e-4) 58 { 59 double mid = (lb + ub) / 2; 60 if (C(mid)) 61 { 62 lb = mid; // 行,说明mid太小 63 } 64 else 65 { 66 ub = mid; // 不行,说明mid太大 67 } 68 } 69 70 cout << fixed << setprecision(0) << lb * 100 << endl; 71 } 72 #ifndef ONLINE_JUDGE 73 fclose(stdin); 74 fclose(stdout); 75 system("out.txt"); 76 #endif 77 return 0; 78 } 79 ///////////////////////////End Sub//////////////////////////////////