本篇涵盖
1、HashMap并不是用keySet来存储key的原因及证明
2、keySet方法返回后的remove、add操作原理
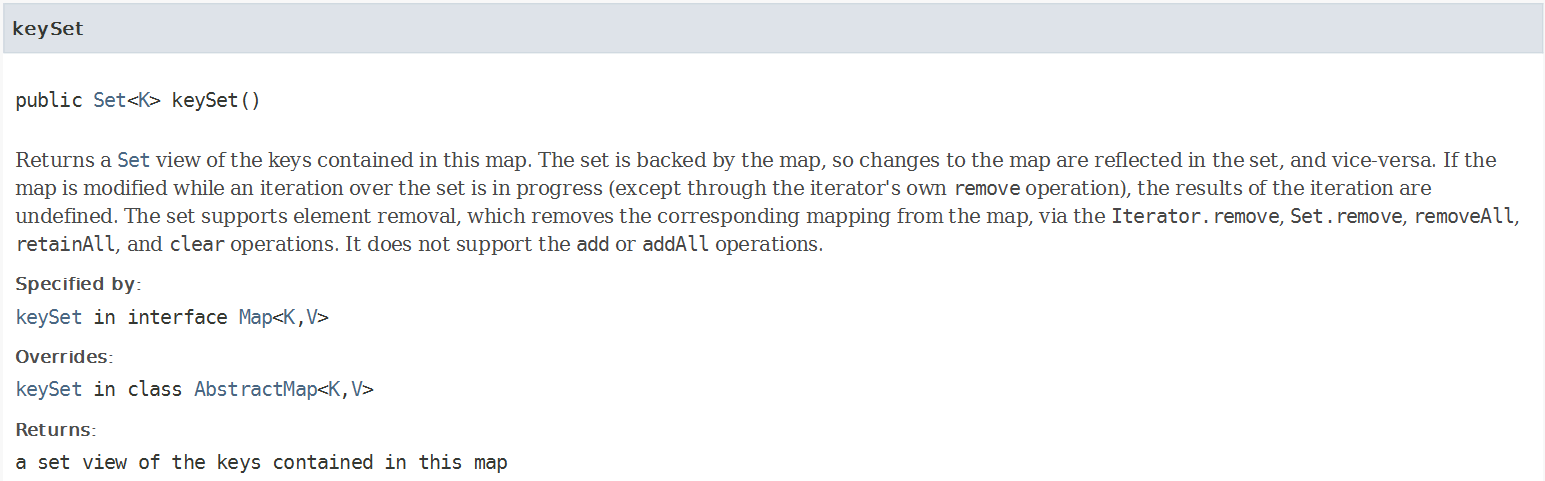
一、方法作用
概括一下
1、keySet方法返回map中包含的键的集合视图
2、集合由map支持,改变集合会影响map,反之亦然
3、集合支持删除操作,不支持添加
二、原理分析
1、HashMap源码分析

keySet方法查看keySet是否为null
不为null则直接返回,若为null则创建后返回
接下来看构造函数中做了什么


/** * {@inheritDoc} * * @implSpec * This implementation returns a set that subclasses {@link AbstractSet}. * The subclass's iterator method returns a "wrapper object" over this * map's <tt>entrySet()</tt> iterator. The <tt>size</tt> method * delegates to this map's <tt>size</tt> method and the * <tt>contains</tt> method delegates to this map's * <tt>containsKey</tt> method. * * <p>The set is created the first time this method is called, * and returned in response to all subsequent calls. No synchronization * is performed, so there is a slight chance that multiple calls to this * method will not all return the same set. */ public Set<K> keySet() { Set<K> ks = keySet; if (ks == null) { ks = new AbstractSet<K>() { public Iterator<K> iterator() { return new Iterator<K>() { private Iterator<Entry<K,V>> i = entrySet().iterator(); public boolean hasNext() { return i.hasNext(); } public K next() { return i.next().getKey(); } public void remove() { i.remove(); } }; } public int size() { return AbstractMap.this.size(); } public boolean isEmpty() { return AbstractMap.this.isEmpty(); } public void clear() { AbstractMap.this.clear(); } public boolean contains(Object k) { return AbstractMap.this.containsKey(k); } }; keySet = ks; } return ks; }
代码注释中提到,创建的对象是AbstractSet的子类
并且说明了keySet集合是在第一次调用此方法时创建的
再来看KeySet这个类
final class KeySet extends AbstractSet<K> { public final int size() { return size; } public final void clear() { HashMap.this.clear(); } public final Iterator<K> iterator() { return new KeyIterator(); } public final boolean contains(Object o) { return containsKey(o); } public final boolean remove(Object key) { return removeNode(hash(key), key, null, false, true) != null; } public final Spliterator<K> spliterator() { return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0); } public final void forEach(Consumer<? super K> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); if (size > 0 && (tab = table) != null) { int mc = modCount; for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) action.accept(e.key); } if (modCount != mc) throw new ConcurrentModificationException(); } } }
里面包含了clear、remove、forEach等方法
需要注意,这里不存在任何能存放键的数据结构
那keySet集合是怎样拿到所有键的呢?不要着急,我们进入父类查看
2、AbstractSet分析(removeAll实现)
![]()
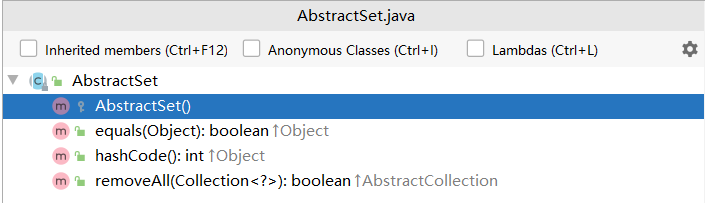
这是一个抽象类,还是没有任何存储结构
不过我们找到了removeAll方法

可以看到需要传入一个collection
利用迭代器遍历,通过remove方法实现删除
按照这种思想,keySet方法会不会也是利用了迭代器来获取key?
我们继续进入父类
3、AbstractCollection分析(add抛异常原因)
![]()
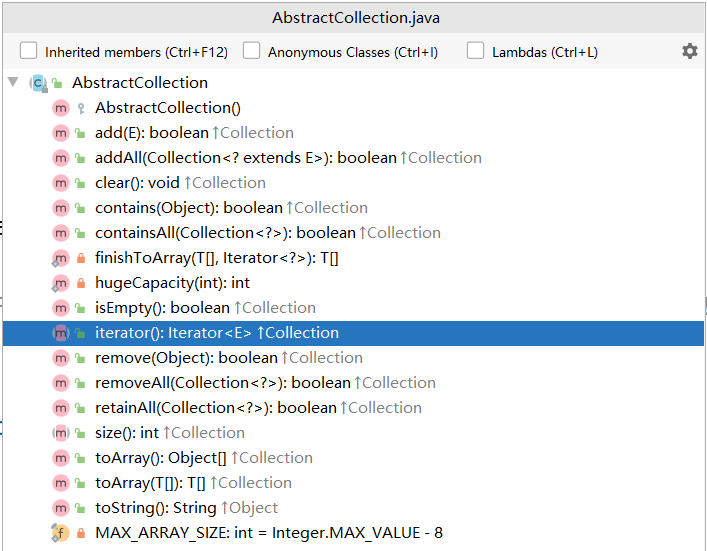
还是不存在任何存储结构
因为实现了collection接口,所以有迭代方法
我们还看到了add和addAll方法


使用add时直接抛出不支持异常
addAll调用add,所以还是会报异常
到这里我们知道add抛异常的出处了,是在AbstractCollection中规定的
4、KeyIterator迭代器分析
到此我们没有发现任何的存储结构
接下来来验证keySet方法是利用了迭代器来获取key的

使用了KeyIterator迭代器

进入父类
abstract class HashIterator { Node<K,V> next; // next entry to return Node<K,V> current; // current entry int expectedModCount; // for fast-fail int index; // current slot HashIterator() { expectedModCount = modCount; Node<K,V>[] t = table; current = next = null; index = 0; if (t != null && size > 0) { // advance to first entry do {} while (index < t.length && (next = t[index++]) == null); } } public final boolean hasNext() { return next != null; } final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } }
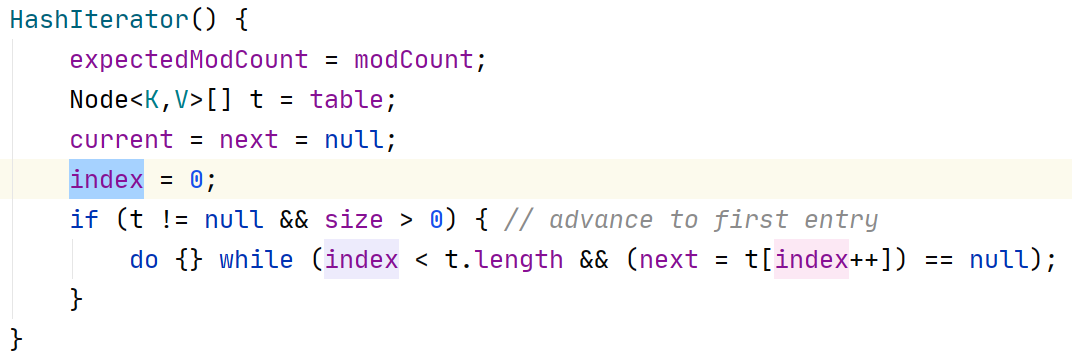
构造方法中拿到table
循环并将index置于table的第一位(第一个有元素的位置)
将next置为下一位
再来看看获取下一个节点的方法

1、将e设为next
2、将next置为下一位元素
3、返回e
使用迭代器一直迭代的话,就应该是从数组前到后
每次获取数组当前下标链表的下一个元素
直到元素为null,代表前端链表结束
数组下标增加,继续遍历下一个链表
三、总结
keySet方法并没有存储HashMap的key,而是以迭代器的形式,遍历获取HashMap中的所有key
对于HashMap的values方法,也是类似的原理