可伸缩性和可扩展性的概念区别
可伸缩性翻译自 Scalability,指的是通过简单地增加硬件配置而使服务处理能力呈线性增长的能力。最简单直观的例子,就是通过在应用服务器集群中增加更多的节点,来提高整个集群的处理能力。
可扩展性翻译自 Extensibility,指的是网站的架构设计能够快速适应需求的变化,当需要增加新的功能实现时,对原有架构不需要做修改或者做很少的修改就能够快速满足新的业务需求。
分层的可伸缩性架构
网站的可伸缩性架构设计主要包含两个层面的含义:
一个是指,根据功能进行物理分离来实现伸缩
有两种不同的实现方式:
1.一种是功能的“横切”,比如一个电商网站的购物功能从上至下就可以分为界面 UI 层、业务逻辑处理层、公共服务层和数据库层,如果我们将这些层区分开来,每个层就可以独立实现可伸缩;

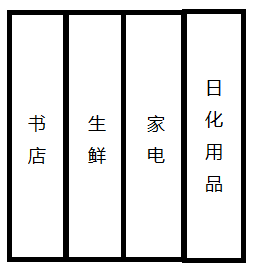
2.另一种是功能的“纵切”,比如一个电商网站可以根据经营的业务范围(比如书店、生鲜、家电和日化用品等)进行功能模块的划分,划分后的每个业务模块都可以独立地根据业务流量和压力来实现最适合自己规模的伸缩性设计。
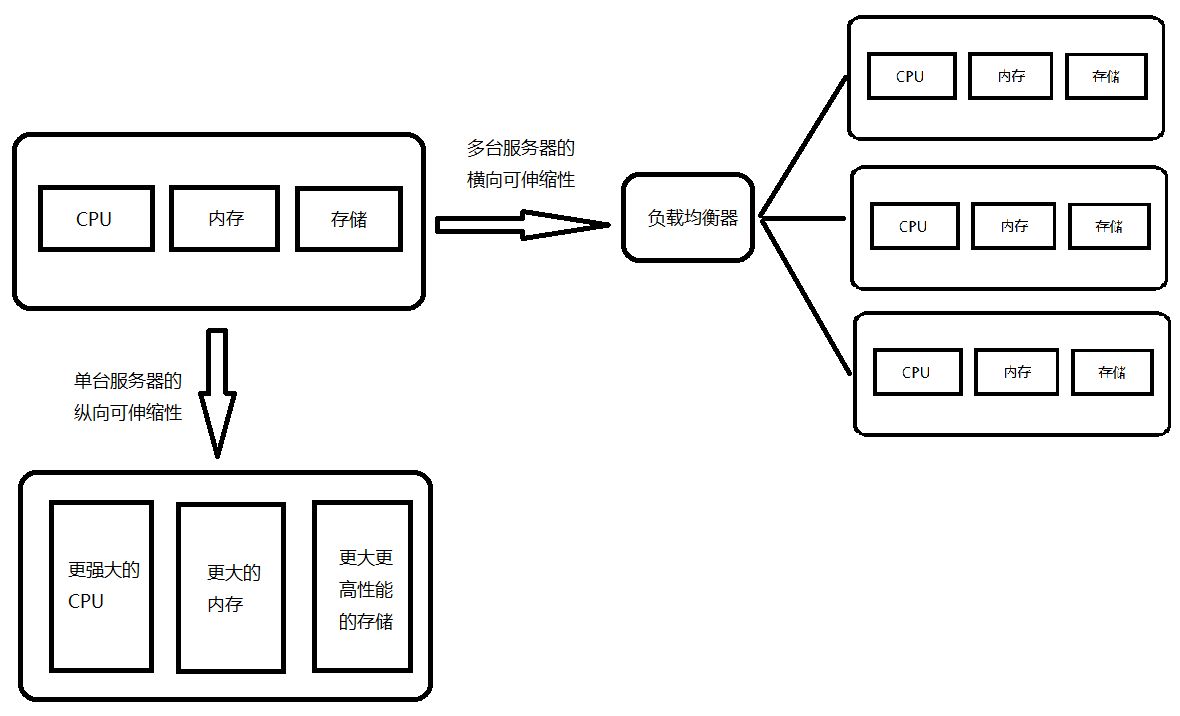
另一个是指,物理分离后的单一功能通过增加或者减少硬件来实现伸缩
有两种不同的实现方式:
1.一种是纵向的可伸缩性,指的是通过增加单一服务器上的硬件资源来提高处理能力。
2.另一种是横向的可伸缩性,指的是通过使用服务器集群来实现单一功能的可扩展性。
基于集群的可伸缩性设计,是和网站本身的分层架构设计相对应的:
-
在应用服务器层面有应用服务器集群的可伸缩性架构设计;
-
在缓存服务器层面有缓存服务器的可伸缩性架构设计;
-
在数据库层面有数据库服务器的可伸缩性架构设计。
应用服务器的可伸缩性设计
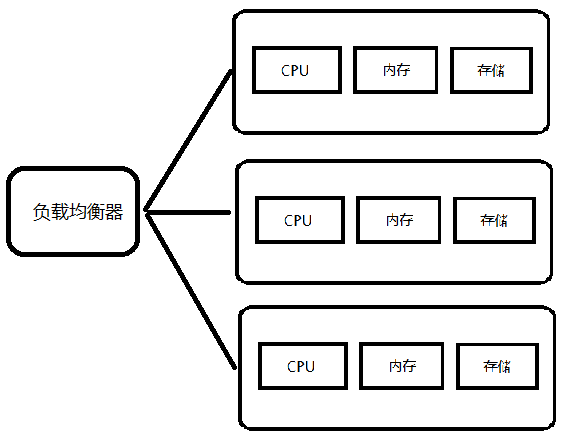
当一台应用服务器不足以支撑业务流量的时候,我们就可以用多台服务器来分担业务流量。使用一个负载均衡器作为统一的窗口来对外提供服务,同时负载均衡器会把实际的业务请求转发给集群中的机器去具体执行。
我们从测试人员的角度来想想,应该考虑哪些相关的测试场景:
-
需要通过压力测试来得出单一节点的负载承受能力;
-
验证系统整体的负载承受能力,是否能够随着集群中的节点数量呈现线性增长;
-
集群中节点的数量是否有上限;
-
新加入的节点是否可以提供和原来节点无差异的服务;
-
对于有状态的应用,是否能够实现一次会话(session)的多次请求都被分配到集群中某一台固定的服务器上;
-
验证负载均衡算法的准确性。
缓存集群的可伸缩性设计
缓存的核心原理
假定,一个缓存集群中有 3 台机器,那么我们在将需要缓存的内容存入缓存集群的过程,包括了这三步:
-
首先,将需要缓存的内容的 Key 值做 Hash 运算;
-
然后,将得到的 Hash 值对 3 取余数;
-
最后,将缓存内容写入余数所代表的那台服务器。
而此时,如果我们在缓存集群中加入了一台新的机器,也就是说缓存集群中机器的数量变成了 4。这时 Key 的 Hash 值就应该对 4 取余,你会发现这么一来,原本已经缓存的绝大多数内容就都失效了,必须重构整个缓存集群。
为了解决上述这个问题,使得缓存集群也可以做到按需、高效地伸缩,那就必须采用更为先进的 Hash 一致性算法。这个算法可以很巧妙地解决缓存集群的扩容问题,保证了新增机器节点的时候大部分的缓存不会失效。
我们从测试人员的角度出发,看看需要额外关注哪些点:
-
针对缓存集群中新增节点的测试,验证其对原有缓存的影响是否足够小;
-
验证系统冷启动完成后,缓存中还没有任何数据的时候,如果此时网站负载较大,数据库是否可以承受这样的压力;
-
需要验证各种情况下,缓存数据和数据库数据的一致性;
-
验证是否已经对潜在的缓存穿透攻击进行了处理,因为如果有人刻意利用这个漏洞来发起海量请求的话,就有可能会拖垮数据库。
数据库的可伸缩性设计
数据库的可伸缩性设计主要有四种方式:
第一种方式是目前最常用的业务分库,也就是从业务上将一个庞大的数据库拆分成多个不同的数据库。
第二种方式是读写分离的数据库设计,其中主库用于所有的写操作,从库用于所有的读操作,然后主从库会自动进行数据同步操作。
第三种数据库的可伸缩性设计:分布式数据库。
第四种方式则是完全颠覆了传统关系型数据数据库的 NoSQL 设计。
从测试的角度出发,无论是数据库架构哪种设计,我们一般都会从以下几个方面来考虑测试用例的设计:
-
正确读取到刚写入数据的延迟时间;
-
在数据库架构发生改变,或者同样的架构数据库参数发生了改变时,数据库基准性能是否会发生明显的变化;
-
压力测试过程中,数据库服务器的各项监控指标是否符合预期;
-
数据库在线扩容过程中对业务的影响程度;
-
数据库集群中,某个节点由于硬件故障对业务的影响程度。
来源于 极客时间 茹炳晟 软件测试52讲