部分 IV
OpenCV 中的图像处理
23 图像变换
23.1 傅里叶变换
目标
本小节我们将要学习:
• 使用 OpenCV 对图像进行傅里叶变换
• 使用 Numpy 中 FFT(快速傅里叶变换)函数
• 傅里叶变换的一些用处
• 我们将要学习的函数有:cv2.dft(),cv2.idft() 等
原理
傅里叶变换经常被用来分析不同滤波器的频率特性。我们可以使用 2D 离散傅里叶变换 (DFT) 分析图像的频域特性。实现 DFT 的一个快速算法被称为快速傅里叶变换(FFT)。关于傅里叶变换的细节知识可以在任意一本图像处理或信号处理的书中找到。请查看本小节中更多资源部分。
对于一个正弦信号:x(t) = Asin(2πft), 它的频率为 f,如果把这个信号转到它的频域表示,我们会在频率 f 中看到一个峰值。如果我们的信号是由采样产生的离散信号好组成,我们会得到类似的频谱图,只不过前面是连续的,现在是离散。你可以把图像想象成沿着两个方向采集的信号。所以对图像同时进行 X 方向和 Y 方向的傅里叶变换,我们就会得到这幅图像的频域表示(频谱图)。
更直观一点,对于一个正弦信号,如果它的幅度变化非常快,我们可以说他是高频信号,如果变化非常慢,我们称之为低频信号。你可以把这种想法应用到图像中,图像那里的幅度变化非常大呢?边界点或者噪声。所以我们说边界和噪声是图像中的高频分量(注意这里的高频是指变化非常快,而非出现的次数多)。如果没有如此大的幅度变化我们称之为低频分量。
现在我们看看怎样进行傅里叶变换。
23.1.1 Numpy 中的傅里叶变换
首先我们看看如何使用 Numpy 进行傅里叶变换。Numpy 中的 FFT 包可以帮助我们实现快速傅里叶变换。函数 np.fft.fft2() 可以对信号进行频率转换,输出结果是一个复杂的数组。本函数的第一个参数是输入图像,要求是灰度格式。第二个参数是可选的, 决定输出数组的大小。输出数组的大小和输入图像大小一样。如果输出结果比输入图像大,输入图像就需要在进行 FFT 前补0。如果输出结果比输入图像小的话,输入图像就会被切割。
现在我们得到了结果,频率为 0 的部分(直流分量)在输出图像的左上角。如果想让它(直流分量)在输出图像的中心,我们还需要将结果沿两个方向平移
N
2
。函数 np.fft.fftshift() 可以帮助我们实现这一步。(这样更容易分析)。
进行完频率变换之后,我们就可以构建振幅谱了。
import cv2 import numpy as np from matplotlib import pyplot as plt img = cv2.imread('messi5.jpg',0) f = np.fft.fft2(img) fshift = np.fft.fftshift(f) # 这里构建振幅图的公式没学过 magnitude_spectrum = 20*np.log(np.abs(fshift)) plt.subplot(121),plt.imshow(img, cmap = 'gray') plt.title('Input Image'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray') plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([]) plt.show()
结果如下:

我们可以看到输出结果的中心部分更白(亮),这说明低频分量更多。
现在我们可以进行频域变换了,我们就可以在频域对图像进行一些操作了,例如高通滤波和重建图像(DFT 的逆变换)。比如我们可以使用一个60x60 的矩形窗口对图像进行掩模操作从而去除低频分量。然后再使用函数np.fft.ifftshift() 进行逆平移操作,所以现在直流分量又回到左上角了,左后使用函数 np.ifft2() 进行 FFT 逆变换。同样又得到一堆复杂的数字,我们可以对他们取绝对值:
rows, cols = img.shape crow,ccol = rows/2 , cols/2 fshift[crow-30:crow+30, ccol-30:ccol+30] = 0 f_ishift = np.fft.ifftshift(fshift) img_back = np.fft.ifft2(f_ishift) img_back = np.abs(img_back) plt.subplot(131),plt.imshow(img, cmap = 'gray') plt.title('Input Image'), plt.xticks([]), plt.yticks([]) plt.subplot(132),plt.imshow(img_back, cmap = 'gray') plt.title('Image after HPF'), plt.xticks([]), plt.yticks([]) plt.subplot(133),plt.imshow(img_back) plt.title('Result in JET'), plt.xticks([]), plt.yticks([]) plt.show()
结果如下:

上图的结果显示高通滤波其实是一种边界检测操作。这就是我们在前面图像梯度那一章看到的。同时我们还发现图像中的大部分数据集中在频谱图的低频区域。我们现在已经知道如何使用 Numpy 进行 DFT 和 IDFT 了,接着我们来看看如何使用 OpenCV 进行这些操作。
如果你观察仔细的话,尤其是最后一章 JET 颜色的图像,你会看到一些不自然的东西(如我用红色箭头标出的区域)。看上图那里有些条带装的结构,这被成为振铃效应。这是由于我们使用矩形窗口做掩模造成的。这个掩模被转换成正弦形状时就会出现这个问题。所以一般我们不适用矩形窗口滤波。最好的选择是高斯窗口。
23.1.2 OpenCV 中的傅里叶变换
OpenCV 中相应的函数是 cv2.dft() 和 cv2.idft()。和前面输出的结果一样,但是是双通道的。第一个通道是结果的实数部分,第二个通道是结果的虚数部分。输入图像要首先转换成 np.float32 格式。我们来看看如何操作。
import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('messi5.jpg',0) dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT) dft_shift = np.fft.fftshift(dft) magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1])) plt.subplot(121),plt.imshow(img, cmap = 'gray') plt.title('Input Image'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray') plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([]) plt.show()
注意:你可以使用函数 cv2.cartToPolar(),它会同时返回幅度和相位。
现在我们来做逆 DFT。在前面的部分我们实现了一个 HPF(高通滤波),现在我们来做 LPF(低通滤波)将高频部分去除。其实就是对图像进行模糊操作。首先我们需要构建一个掩模,与低频区域对应的地方设置为 1, 与高频区域对应的地方设置为 0。
rows, cols = img.shape crow,ccol = rows/2 , cols/2 # create a mask first, center square is 1, remaining all zeros mask = np.zeros((rows,cols,2),np.uint8) mask[crow-30:crow+30, ccol-30:ccol+30] = 1 # apply mask and inverse DFT fshift = dft_shift*mask f_ishift = np.fft.ifftshift(fshift) img_back = cv2.idft(f_ishift) img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1]) plt.subplot(121),plt.imshow(img, cmap = 'gray') plt.title('Input Image'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(img_back, cmap = 'gray') plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([]) plt.show()
结果如下:

注意:OpenCV 中的函数 cv2.dft() 和 cv2.idft() 要比 Numpy 快。但是Numpy 函数更加用户友好。关于性能的描述,请看下面的章节。
23.1.3 DFT 的性能优化
当数组的大小为某些值时 DFT 的性能会更好。当数组的大小是 2 的指数时 DFT 效率最高。当数组的大小是 2,3,5 的倍数时效率也会很高。所以如果你想提高代码的运行效率时,你可以修改输入图像的大小(补 0)。对于OpenCV 你必须自己手动补 0。但是 Numpy,你只需要指定 FFT 运算的大小,它会自动补 0。
那我们怎样确定最佳大小呢?OpenCV 提供了一个函数:cv2.getOptimalDFTSize()。
它可以同时被 cv2.dft() 和 np.fft.fft2() 使用。让我们一起使用 IPython的魔法命令%timeit 来测试一下吧。
In [16]: img = cv2.imread('messi5.jpg',0) In [17]: rows,cols = img.shape In [18]: print rows,cols 342 548 In [19]: nrows = cv2.getOptimalDFTSize(rows) In [20]: ncols = cv2.getOptimalDFTSize(cols) In [21]: print nrows, ncols 360 576
看到了吧,数组的大小从(342,548)变成了(360,576)。现在我们为它补 0,然后看看性能有没有提升。你可以创建一个大的 0 数组,然后把我们的数据拷贝过去,或者使用函数 cv2.copyMakeBoder()。
nimg = np.zeros((nrows,ncols))
nimg[:rows,:cols] = img
或者:
right = ncols - cols bottom = nrows - rows #just to avoid line breakup in PDF file bordertype = cv2.BORDER_CONSTANT nimg = cv2.copyMakeBorder(img,0,bottom,0,right,bordertype, value = 0)
现在我们看看 Numpy 的表现:
In [22]: %timeit fft1 = np.fft.fft2(img) 10 loops, best of 3: 40.9 ms per loop In [23]: %timeit fft2 = np.fft.fft2(img,[nrows,ncols]) 100 loops, best of 3: 10.4 ms per loop
速度提高了 4 倍。我们再看看 OpenCV 的表现:
In [24]: %timeit dft1= cv2.dft(np.float32(img),flags=cv2.DFT_COMPLEX_OUTPUT) 100 loops, best of 3: 13.5 ms per loop In [27]: %timeit dft2= cv2.dft(np.float32(nimg),flags=cv2.DFT_COMPLEX_OUTPUT) 100 loops, best of 3: 3.11 ms per loop
也提高了 4 倍,同时我们也会发现 OpenCV 的速度是 Numpy 的 3 倍。
你也可以测试一下逆 FFT 的表现。
23.1.4 为什么拉普拉斯算子是高通滤波器?
我在论坛中遇到了一个类似的问题。为什么拉普拉斯算子是高通滤波器?
为什么 Sobel 是 HPF?等等。对于第一个问题的答案我们以傅里叶变换的形式给出。我们一起来对不同的算子进行傅里叶变换并分析它们:
import cv2 import numpy as np from matplotlib import pyplot as plt # simple averaging filter without scaling parameter mean_filter = np.ones((3,3)) # creating a guassian filter x = cv2.getGaussianKernel(5,10) #x.T 为矩阵转置 gaussian = x*x.T # different edge detecting filters # scharr in x-direction scharr = np.array([[-3, 0, 3], [-10,0,10], [-3, 0, 3]]) # sobel in x direction sobel_x= np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) # sobel in y direction sobel_y= np.array([[-1,-2,-1], [0, 0, 0], [1, 2, 1]]) # laplacian laplacian=np.array([[0, 1, 0], [1,-4, 1], [0, 1, 0]]) filters = [mean_filter, gaussian, laplacian, sobel_x, sobel_y, scharr] filter_name = ['mean_filter', 'gaussian','laplacian', 'sobel_x', 'sobel_y', 'scharr_x'] fft_filters = [np.fft.fft2(x) for x in filters] fft_shift = [np.fft.fftshift(y) for y in fft_filters] mag_spectrum = [np.log(np.abs(z)+1) for z in fft_shift] for i in xrange(6): plt.subplot(2,3,i+1),plt.imshow(mag_spectrum[i],cmap = 'gray') plt.title(filter_name[i]), plt.xticks([]), plt.yticks([]) plt.show()
结果:

从图像中我们就可以看出每一个算子允许通过那些信号。从这些信息中我
们就可以知道那些是 HPF 那是 LPF。
更多资源
1. An Intuitive Explanation of Fourier Theoryby Steven Lehar
2. Fourier Transformat HIPR
3. What does frequency domain denote in case of images?
练习
24 模板匹配
目标
在本节我们要学习:
1. 使用模板匹配在一幅图像中查找目标
2. 函数:cv2.matchTemplate(),cv2.minMaxLoc()
原理
模板匹配是用来在一副大图中搜寻查找模版图像位置的方法。OpenCV 为我们提供了函数:cv2.matchTemplate()。和 2D 卷积一样,它也是用模板图像在输入图像(大图)上滑动,并在每一个位置对模板图像和与其对应的输入图像的子区域进行比较。OpenCV 提供了几种不同的比较方法(细节请看文档)。返回的结果是一个灰度图像,每一个像素值表示了此区域与模板的匹配程度。
如果输入图像的大小是(WxH),模板的大小是(wxh),输出的结果的大小就是(W-w+1,H-h+1)。当你得到这幅图之后,就可以使用函数cv2.minMaxLoc() 来找到其中的最小值和最大值的位置了。第一个值为矩形左上角的点(位置),(w,h)为 moban 模板矩形的宽和高。这个矩形就是找到的模板区域了。
注意:如果你使用的比较方法是 cv2.TM_SQDIFF,最小值对应的位置才是匹配的区域。
24.1 OpenCV 中的模板匹配
我们这里有一个例子:我们在梅西的照片中搜索梅西的面部。所以我们要制作下面这样一个模板:

我们会尝试使用不同的比较方法,这样我们就可以比较一下它们的效果了。
import cv2 import numpy as np from matplotlib import pyplot as plt img = cv2.imread('messi5.jpg',0) img2 = img.copy() template = cv2.imread('messi_face.jpg',0) w, h = template.shape[::-1] # All the 6 methods for comparison in a list methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR', 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED'] for meth in methods: img = img2.copy() #exec 语句用来执行储存在字符串或文件中的 Python 语句。 # 例如,我们可以在运行时生成一个包含 Python 代码的字符串,然后使用 exec 语句执行这些语句。 #eval 语句用来计算存储在字符串中的有效 Python 表达式 method = eval(meth) # Apply template Matching res = cv2.matchTemplate(img,template,method) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 使用不同的比较方法,对结果的解释不同 # If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]: top_left = min_loc else: top_left = max_loc bottom_right = (top_left[0] + w, top_left[1] + h) cv2.rectangle(img,top_left, bottom_right, 255, 2) plt.subplot(121),plt.imshow(res,cmap = 'gray') plt.title('Matching Result'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(img,cmap = 'gray') plt.title('Detected Point'), plt.xticks([]), plt.yticks([]) plt.suptitle(meth) plt.show()
结果如下:
cv2.TM_CCOEFF
 cv2.TM_CCOEFF_NORMED
cv2.TM_CCOEFF_NORMED
 cv2.TM_CCORR
cv2.TM_CCORR
 cv2.TM_CCORR_NORMED
cv2.TM_CCORR_NORMED
 cv2.TM_SQDIFF
cv2.TM_SQDIFF
 cv2.TM_SQDIFF_NORMED
cv2.TM_SQDIFF_NORMED

我们看到 cv2.TM_CCORR 的效果不想我们想的那么好。
24.2 多对象的模板匹配
在前面的部分,我们在图片中搜素梅西的脸,而且梅西只在图片中出现了一次。假如你的目标对象只在图像中出现了很多次怎么办呢?函数cv.imMaxLoc() 只会给出最大值和最小值。此时,我们就要使用阈值了。
在下面的例子中我们要经典游戏 Mario 的一张截屏图片中找到其中的硬币。
import cv2 import numpy as np from matplotlib import pyplot as plt img_rgb = cv2.imread('mario.png') img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY) template = cv2.imread('mario_coin.png',0) w, h = template.shape[::-1] res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED) threshold = 0.8 loc = np.where( res >= threshold) for pt in zip(*loc[::-1]): cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2) cv2.imwrite('res.png',img_rgb)
结果:

25 Hough 直线变换
目标
• 理解霍夫变换的概念
• 学习如何在一张图片中检测直线
• 学习函数:cv2.HoughLines(),cv2.HoughLinesP()
原理
霍夫变换在检测各种形状的的技术中非常流行,如果你要检测的形状可以用数学表达式写出,你就可以是使用霍夫变换检测它。及时要检测的形状存在一点破坏或者扭曲也可以使用。我们下面就看看如何使用霍夫变换检测直线。一条直线可以用数学表达式 y = mx + c 或者 ρ = xcosθ + y sinθ 表示。
ρ 是从原点到直线的垂直距离,θ 是直线的垂线与横轴顺时针方向的夹角(如果你使用的坐标系不同方向也可能不同,我是按 OpenCV 使用的坐标系描述的)。如下图所示:
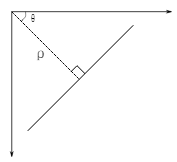
所以如果一条线在原点下方经过,ρ 的值就应该大于 0,角度小于 180。但是如果从原点上方经过的话,角度不是大于 180,也是小于 180,但 ρ 的值小于 0。垂直的线角度为 0 度,水平线的角度为 90 度。让我们来看看霍夫变换是如何工作的。每一条直线都可以用 (ρ,θ) 表示。
所以首先创建一个 2D 数组(累加器),初始化累加器,所有的值都为 0。行表示 ρ,列表示 θ。这个数组的大小决定了最后结果的准确性。如果你希望角度精确到 1 度,你就需要 180 列。对于 ρ,最大值为图片对角线的距离。所以如果精确度要达到一个像素的级别,行数就应该与图像对角线的距离相等。
想象一下我们有一个大小为 100x100 的直线位于图像的中央。取直线上的第一个点,我们知道此处的(x,y)值。把 x 和 y 带入上边的方程组,然后遍历 θ 的取值:0,1,2,3,...,180。分别求出与其对应的 ρ 的值,这样我们就得到一系列(ρ,θ)的数值对,如果这个数值对在累加器中也存在相应的位置,就在这个位置上加 1。所以现在累加器中的(50,90)=1。(一个点可能存在与多条直线中,所以对于直线上的每一个点可能是累加器中的多个值同时加 1)。
现在取直线上的第二个点。重复上边的过程。更新累加器中的值。现在累加器中(50,90)的值为 2。你每次做的就是更新累加器中的值。对直线上的每个点都执行上边的操作,每次操作完成之后,累加器中的值就加 1,但其他地方有时会加 1, 有时不会。按照这种方式下去,到最后累加器中(50,90)的值肯定是最大的。如果你搜索累加器中的最大值,并找到其位置(50,90),这就说明图像中有一条直线,这条直线到原点的距离为 50,它的垂线与横轴的夹角为 90 度。下面的动画很好的演示了这个过程(Image Courtesy: AmosStorkey )。

这就是霍夫直线变换工作的方式。很简单,也许你自己就可以使用 Numpy搞定它。下图显示了一个累加器。其中最亮的两个点代表了图像中两条直线的参数。(Image courtesy: Wikipedia)。

25.1 OpenCV 中的霍夫变换
上面介绍的整个过程在 OpenCV 中都被封装进了一个函数:cv2.HoughLines()。
返回值就是(ρ,θ)。ρ 的单位是像素,θ 的单位是弧度。这个函数的第一个参数是一个二值化图像,所以在进行霍夫变换之前要首先进行二值化,或者进行Canny 边缘检测。第二和第三个值分别代表 ρ 和 θ 的精确度。第四个参数是阈值,只有累加其中的值高于阈值时才被认为是一条直线,也可以把它看成能检测到的直线的最短长度(以像素点为单位)。
import cv2 import numpy as np img = cv2.imread('dave.jpg') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray,50,150,apertureSize = 3) lines = cv2.HoughLines(edges,1,np.pi/180,200) for rho,theta in lines[0]: a = np.cos(theta) b = np.sin(theta) x0 = a*rho y0 = b*rho x1 = int(x0 + 1000*(-b)) y1 = int(y0 + 1000*(a)) x2 = int(x0 - 1000*(-b)) y2 = int(y0 - 1000*(a)) cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2) cv2.imwrite('houghlines3.jpg',img)
结果如下:

25.2 Probabilistic Hough Transform
从上边的过程我们可以发现:仅仅是一条直线都需要两个参数,这需要大量的计算。Probabilistic_Hough_Transform 是对霍夫变换的一种优化。它不会对每一个点都进行计算,而是从一幅图像中随机选取(是不是也可以使用图像金字塔呢?)一个点集进行计算,对于直线检测来说这已经足够了。但是使用这种变换我们必须要降低阈值(总的点数都少了,阈值肯定也要小呀!)。
下图是对两种方法的对比。(Image Courtesy : Franck Bettinger’s homepage)

OpenCV 中使用的 Matas, J. ,Galambos, C. 和 Kittler, J.V. 提出的Progressive Probabilistic Hough Transform。这个函数是 cv2.HoughLinesP()。
它有两个参数。
• minLineLength - 线的最短长度。比这个短的线都会被忽略。
• MaxLineGap - 两条线段之间的最大间隔,如果小于此值,这两条直线就被看成是一条直线。
更加给力的是,这个函数的返回值就是直线的起点和终点。而在前面的例子中,我们只得到了直线的参数,而且你必须要找到所有的直线。而在这里一切都很直接很简单。
import cv2 import numpy as np img = cv2.imread('dave.jpg') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray,50,150,apertureSize = 3) minLineLength = 100 maxLineGap = 10 lines = cv2.HoughLinesP(edges,1,np.pi/180,100,minLineLength,maxLineGap) for x1,y1,x2,y2 in lines[0]: cv2.line(img,(x1,y1),(x2,y2),(0,255,0),2) cv2.imwrite('houghlines5.jpg',img)
结果如下:

26 Hough 圆环变换
目标
• 学习使用霍夫变换在图像中找圆形(环)。
• 学习函数:cv2.HoughCircles()。
原理
圆形的数学表达式为 (x − x center ) 2 +(y − y center ) 2 = r 2 ,其中(x center ,y center )为圆心的坐标,r 为圆的直径。从这个等式中我们可以看出:一个圆环需要 3个参数来确定。所以进行圆环霍夫变换的累加器必须是 3 维的,这样的话效率就会很低。所以 OpenCV 用来一个比较巧妙的办法,霍夫梯度法,它可以使用边界的梯度信息。
我们要使用的函数为 cv2.HoughCircles()。文档中对它的参数有详细的解释。这里我们就直接看代码吧。
import cv2 import numpy as np img = cv2.imread('opencv_logo.png',0) img = cv2.medianBlur(img,5) cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR) circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,20, param1=50,param2=30,minRadius=0,maxRadius=0) circles = np.uint16(np.around(circles)) for i in circles[0,:]: # draw the outer circle cv2.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2) # draw the center of the circle cv2.circle(cimg,(i[0],i[1]),2,(0,0,255),3) cv2.imshow('detected circles',cimg) cv2.waitKey(0) cv2.destroyAllWindows() #Python: cv2.HoughCircles(image, method, dp, minDist, circles, param1, param2, minRadius, maxRadius) #Parameters: #image – 8-bit, single-channel, grayscale input image. # 返回结果为 Output vector of found circles. Each vector is encoded as a #3-element floating-point vector (x, y, radius) . #circle_storage – In C function this is a memory storage that will contain #the output sequence of found circles. #method – Detection method to use. Currently, the only implemented method is #CV_HOUGH_GRADIENT , which is basically 21HT , described in [Yuen90]. #dp – Inverse ratio of the accumulator resolution to the image resolution. #For example, if dp=1 , the accumulator has the same resolution as the input image. #If dp=2 , the accumulator has half as big width and height. #minDist – Minimum distance between the centers of the detected circles. #If the parameter is too small, multiple neighbor circles may be falsely #detected in addition to a true one. If it is too large, some circles may be missed. #param1 – First method-specific parameter. In case of CV_HOUGH_GRADIENT , #it is the higher threshold of the two passed to the Canny() edge detector # (the lower one is twice smaller). #param2 – Second method-specific parameter. In case of CV_HOUGH_GRADIENT , # it is the accumulator threshold for the circle centers at the detection stage. #The smaller it is, the more false circles may be detected. Circles, # corresponding to the larger accumulator values, will be returned first. #minRadius – Minimum circle radius. #maxRadius – Maximum circle radius.
结果如下:

更多资源
练习
27 分水岭算法图像分割
目标
本节我们将要学习
• 使用分水岭算法基于掩模的图像分割
• 函数:cv2.watershed()
原理
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水。随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝知道所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。这就是分水岭算法的背后哲理。你可以通过访问网站CMM webpage on watershed来加深自己的理解。
但是这种方法通常都会得到过度分割的结果,这是由噪声或者图像中其他不规律的因素造成的。为了减少这种影响,OpenCV 采用了基于掩模的分水岭算法,在这种算法中我们要设置那些山谷点会汇合,那些不会。这是一种交互式的图像分割。我们要做的就是给我们已知的对象打上不同的标签。如果某个区域肯定是前景或对象,就使用某个颜色(或灰度值)标签标记它。如果某个区域肯定不是对象而是背景就使用另外一个颜色标签标记。而剩下的不能确定是前景还是背景的区域就用 0 标记。这就是我们的标签。然后实施分水岭算法。每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后我们得到的边界对象(堤坝)的值为 -1。
27.1 代码
下面的例子中我们将就和距离变换和分水岭算法对紧挨在一起的对象进行分割。
如下图所示,这些硬币紧挨在一起。就算你使用阈值操作,它们任然是紧挨着的。

我们从找到硬币的近似估计开始。我们可以使用 Otsu's 二值化。
import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('coins.png') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
结果

现在我们要去除图像中的所有的白噪声。这就需要使用形态学中的开运算。
为了去除对象上小的空洞我们需要使用形态学闭运算。所以我们现在知道靠近对象中心的区域肯定是前景,而远离对象中心的区域肯定是背景。而不能确定的区域就是硬币之间的边界。
所以我们要提取肯定是硬币的区域。腐蚀操作可以去除边缘像素。剩下就可以肯定是硬币了。当硬币之间没有接触时,这种操作是有效的。但是由于硬币之间是相互接触的,我们就有了另外一个更好的选择:距离变换再加上合适的阈值。接下来我们要找到肯定不是硬币的区域。这是就需要进行膨胀操作了。膨胀可以将对象的边界延伸到背景中去。这样由于边界区域被去处理,我们就可以知道那些区域肯定是前景,那些肯定是背景。如下图所示。

剩下的区域就是我们不知道该如何区分的了。这就是分水岭算法要做的。
这些区域通常是前景与背景的交界处(或者两个前景的交界)。我们称之为边界。从肯定是不是背景的区域中减去肯定是前景的区域就得到了边界区域。
# noise removal kernel = np.ones((3,3),np.uint8) opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2) # sure background area sure_bg = cv2.dilate(opening,kernel,iterations=3) # Finding sure foreground area # 距离变换的基本含义是计算一个图像中非零像素点到最近的零像素点的距离,也就是到零像素点的最短距离 # 个最常见的距离变换算法就是通过连续的腐蚀操作来实现,腐蚀操作的停止条件是所有前景像素都被完全 # 腐蚀。这样根据腐蚀的先后顺序,我们就得到各个前景像素点到前景中心??像素点的 # 距离。根据各个像素点的距离值,设置为不同的灰度值。这样就完成了二值图像的距离变换 #cv2.distanceTransform(src, distanceType, maskSize) # 第二个参数 0,1,2 分别表示 CV_DIST_L1, CV_DIST_L2 , CV_DIST_C dist_transform = cv2.distanceTransform(opening,1,5) ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0) # Finding unknown region sure_fg = np.uint8(sure_fg) unknown = cv2.subtract(sure_bg,sure_fg)
如结果所示,在阈值化之后的图像中,我们得到了肯定是硬币的区域,而且硬币之间也被分割开了。(有些情况下你可能只需要对前景进行分割,而不需要将紧挨在一起的对象分开,此时就没有必要使用距离变换了,腐蚀就足够了。当然腐蚀也可以用来提取肯定是前景的区域。)

现在知道了那些是背景那些是硬币了。那我们就可以创建标签(一个与原图像大小相同,数据类型为 in32 的数组),并标记其中的区域了。对我们已经确定分类的区域(无论是前景还是背景)使用不同的正整数标记,对我们不确定的区域使用 0 标记。我们可以使用函数 cv2.connectedComponents()来做这件事。它会把将背景标记为 0,其他的对象使用从 1 开始的正整数标记。
但是,我们知道如果背景标记为 0,那分水岭算法就会把它当成未知区域了。所以我们想使用不同的整数标记它们。而对不确定的区域(函数cv2.connectedComponents 输出的结果中使用 unknown 定义未知区域)标记为 0。
# Marker labelling ret, markers1 = cv2.connectedComponents(sure_fg) # Add one to all labels so that sure background is not 0, but 1 markers = markers1+1 # Now, mark the region of unknown with zero markers[unknown==255] = 0 结果使用 JET 颜色地图表示。深蓝色区域为未知区域。肯定是硬币的区域使用不同的颜色标记。其余区域就是用浅蓝色标记的背景了。 现在标签准备好了。到最后一步:实施分水岭算法了。标签图像将会被修改,边界区域的标记将变为 -1. markers3 = cv2.watershed(img,markers) img[markers3 == -1] = [255,0,0]
结果如下。有些硬币的边界被分割的很好,也有一些硬币之间的边界分割的不好。

Now our marker is ready. It is time for final step, apply watershed. Then marker image will be modified. The boundary region will be marked with -1.
markers = cv2.watershed(img,markers)
img[markers == -1] = [255,0,0]
See the result below. For some coins, the region where they touch are segmented properly and for some, they are not.

练习
1. OpenCV 自带的示例中有一个交互式分水岭分割程序:watershed.py。
自己玩玩吧。
28 使用 GrabCut 算法进行交互式前景提取
目标
在本节中我们将要学习:
• GrabCut 算法原理,使用 GrabCut 算法提取图像的前景
• 创建一个交互是程序完成前景提取
原理
GrabCut 算法是由微软剑桥研究院的 Carsten_Rother,Vladimir_Kolmogorov和 Andrew_Blake 在文章《GrabCut”: interactive foreground extraction using iterated graph cuts》中共同提出的。此算法在提取前景的操作过程中需要很少的人机交互,结果非常好。
从用户的角度来看它到底是如何工作的呢?开始时用户需要用一个矩形将前景区域框住(前景区域应该完全被包括在矩形框内部)。然后算法进行迭代式分割直达达到最好结果。但是有时分割的结果不够理想,比如把前景当成了背景,或者把背景当成了前景。在这种情况下,就需要用户来进行修改了。用户只需要在不理想的部位画一笔(点一下鼠标)就可以了。画一笔就等于在告诉计算机:“嗨,老兄,你把这里弄反了,下次迭代的时候记得改过来呀!”。然后,在下一轮迭代的时候你就会得到一个更好的结果了。
如下图所示。运动员和足球被蓝色矩形包围在一起。其中有我做的几个修正,白色画笔表明这里是前景,黑色画笔表明这里是背景。最后我得到了一个很好的结果。

在整个过程中到底发生了什么呢?
• 用户输入一个矩形。矩形外的所有区域肯定都是背景(我们在前面已经提到,所有的对象都要包含在矩形框内)。矩形框内的东西是未知的。同样用户确定前景和背景的任何操作都不会被程序改变。
• 计算机会对我们的输入图像做一个初始化标记。它会标记前景和背景像素。
• 使用一个高斯混合模型(GMM)对前景和背景建模。
• 根据我们的输入,GMM 会学习并创建新的像素分布。对那些分类未知的像素(可能是前景也可能是背景),可以根据它们与已知分类(如背景)的像素的关系来进行分类(就像是在做聚类操作)。
• 这样就会根据像素的分布创建一副图。图中的节点就是像素点。除了像素点做节点之外还有两个节点:Source_node 和 Sink_node。所有的前景像素都和 Source_node 相连。所有的背景像素都和 Sink_node 相连。
• 将像素连接到 Source_node/end_node 的(边)的权重由它们属于同一类(同是前景或同是背景)的概率来决定。两个像素之间的权重由边的信息或者两个像素的相似性来决定。如果两个像素的颜色有很大的不同,那么它们之间的边的权重就会很小。
• 使用 mincut 算法对上面得到的图进行分割。它会根据最低成本方程将图分为 Source_node 和 Sink_node。成本方程就是被剪掉的所有边的权重之和。在裁剪之后,所有连接到 Source_node 的像素被认为是前景,所有连接到 Sink_node 的像素被认为是背景。
• 继续这个过程直到分类收敛。
下图演示了这个过程(Image Courtesy: http://www.cs.ru.ac.za/research/g02m1682/):

28.1 演示
现在我们进入 OpenCV 中的 grabcut 算法。OpenCV 提供了函数:
cv2.grabCut()。我们来先看看它的参数:
• img - 输入图像
• mask-掩模图像,用来确定那些区域是背景,前景,可能是前景/背景等。可以设置为:cv2.GC_BGD,cv2.GC_FGD,cv2.GC_PR_BGD,cv2.GC_PR_FGD,或者直接输入 0,1,2,3 也行。
• rect - 包含前景的矩形,格式为 (x,y,w,h)
• bdgModel, fgdModel - 算法内部使用的数组. 你只需要创建两个大小为 (1,65),数据类型为 np.float64 的数组。
• iterCount - 算法的迭代次数
• mode 可以设置为 cv2.GC_INIT_WITH_RECT 或 cv2.GC_INIT_WITH_MASK,
也可以联合使用。这是用来确定我们进行修改的方式,矩形模式或者掩模模式。
首先,我们来看使用矩形模式。加载图片,创建掩模图像,构建 bdgModel和 fgdModel。传入矩形参数。都是这么直接。让算法迭代 5 次。由于我们在使用矩形模式所以修改模式设置为 cv2.GC_INIT_WITH_RECT。运行grabcut。算法会修改掩模图像,在新的掩模图像中,所有的像素被分为四类:
背景,前景,可能是背景/前景使用 4 个不同的标签标记(前面参数中提到过)。
然后我们来修改掩模图像,所有的 0 像素和 1 像素都被归为 0(例如背景),所有的 1 像素和 3 像素都被归为 1(前景)。我们最终的掩模图像就这样准备好了。用它和输入图像相乘就得到了分割好的图像。
import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('messi5.jpg') mask = np.zeros(img.shape[:2],np.uint8) bgdModel = np.zeros((1,65),np.float64) fgdModel = np.zeros((1,65),np.float64) rect = (50,50,450,290) # 函数的返回值是更新的 mask, bgdModel, fgdModel cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT) mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8') img = img*mask2[:,:,np.newaxis] plt.imshow(img),plt.colorbar(),plt.show()
结果如下:

哎呀,梅西的头发被我们弄没了!让我们来帮他找回头发。所以我们要在那里画一笔(设置像素为 1,肯定是前景)。同时还有一些我们并不需要的草地。我们需要去除它们,我们再在这个区域画一笔(设置像素为 0,肯定是背景)。现在可以象前面提到的那样来修改掩模图像了。
实际上我是怎么做的呢?我们使用图像编辑软件打开输入图像,添加一个图层,使用笔刷工具在需要的地方使用白色绘制(比如头发,鞋子,球等);使用黑色笔刷在不需要的地方绘制(比如,logo,草地等)。然后将其他地方用灰色填充,保存成新的掩码图像。在 OpenCV 中导入这个掩模图像,根据新的掩码图像对原来的掩模图像进行编辑。代码如下:
# newmask is the mask image I manually labelled newmask = cv2.imread('newmask.png',0) # whereever it is marked white (sure foreground), change mask=1 # whereever it is marked black (sure background), change mask=0 mask[newmask == 0] = 0 mask[newmask == 255] = 1 mask, bgdModel, fgdModel = cv2.grabCut(img,mask,None,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_MASK) mask = np.where((mask==2)|(mask==0),0,1).astype('uint8') img = img*mask[:,:,np.newaxis] plt.imshow(img),plt.colorbar(),plt.show()
结果如下:

就是这样。你也可以不使用矩形初始化,直接进入掩码图像模式。使用 2像素和 3 像素(可能是背景/前景)对矩形区域的像素进行标记。然后象我们在第二个例子中那样对肯定是前景的像素标记为 1 像素。然后直接在掩模图像模式下使用 grabCut 函数。
练习
1. OpenCV 自带的示例中有一个使用 grabcut 算法的交互式工具 grabcut.py,自己玩一下吧。
2. 你可以创建一个交互是取样程序,可以绘制矩形,带有滑动条(调节笔刷的粗细)等。