13:05 2015/9/11 午睡醒来收到几封CPU使用率预警邮件。登录对应服务器,打开资源监视器,看到sqlservr.exe进程的CPU达到40%(平常服务器CPU消耗在10%以内)。查看CPU信息跟踪表,近一小时的CPU都维持在40%左右。
图1 CPU使用率预警邮件
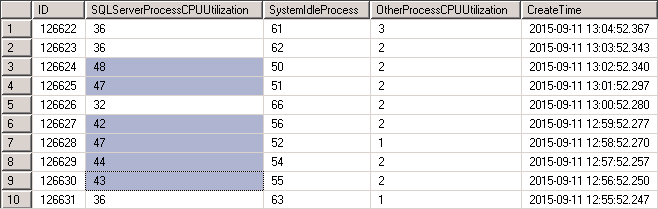
图2 资源监视器和CPU信息跟踪表
开启profiler跟踪,筛选CPU>60毫秒的事件。发现有一个存储过程调用非常频繁,而且cpu>90 read>2800。查看此过程,语句很简单,返回记录数很少,表上有对应索引。但从profiler所得开销看,语句肯定没有使用索引。之前遇到类似的问题,只需删除存储过程的计划缓存,cpu、read就降下去了。


--返回做IO数目最多的存储过程以及它们的执行计划(微秒) SELECT TOP 20 DB_NAME(a.database_id) DBname ,OBJECT_NAME(OBJECT_ID ,database_id) 'proc name' ,a.cached_time ,a.last_execution_time ,a.execution_count ,a.last_logical_reads ,a.total_logical_reads / a.execution_count avg_logical_reads ,a.total_logical_writes / a.execution_count avg_logical_writes ,a.total_physical_reads / a.execution_count avg_physical_reads --,a.total_worker_time / a.execution_count AS avg_worker_time ,a.total_elapsed_time / a.execution_count avg_elapsed_time --,b.text ,c.query_plan ,a.plan_handle FROM sys.dm_exec_procedure_stats AS a CROSS APPLY sys.dm_exec_sql_text(a.sql_handle) b CROSS APPLY sys.dm_exec_query_plan(a.plan_handle) c where OBJECT_NAME(OBJECT_ID ,database_id) ='ProcName' ORDER BY a.total_logical_reads/a.execution_count desc --DBCC FREEPROCCACHE(0x0500080094EA1B2F40A1B3DE000000000000000000000000)

图3 处理前消耗情况
图4 处理后消耗情况
图5 半分钟内过程调用情况
问题现象很明显(不定期会重现),就是一个很简单的过程,频繁调用,突然在某个时间点,过程消耗变得很大;只要把对应缓存计划删除,消耗立马降下去。问题的本质是执行计划的变更。过程最开始执行(或者手动执行时)走的是索引查找+键查找;出问题的时候变成了聚集索引扫描!
图6 手动执行时的执行计划
查看CPU信息跟踪表,找出此次CPU上涨的起始时间(2015-09-11 11:15:51.447)。查询过程涉及表所依赖的存储过程,查询是否有作业对表(直接或者通过存储过程)进行数据变更,分析表中数据变更与CPU上涨的时间是否吻合。
--表依赖的过程 select name,object_id,text from sys.procedures a,syscomments b where a.object_id=b.id and text like '%Table%' --作业调用的表/过程 select top 3 sj.name,sjs.command from msdb.dbo.sysjobs sj inner join msdb.dbo.sysjobsteps sjs on sj.job_id=sjs.job_id where sjs.command like '%TableOrProc%'
发现有两个过程,被两个作业调用,有对表中数据清空然后再写入。其中一个作业是每天凌晨03:03(排除),另一个作业是每小时执行一次。查看每小时执行一次的作业历史记录,发现在11:15的时候作业耗时46秒,其他时候基本为0。也就是那个时间点对表中数据进行了清空再写入的操作。
--查看作业执行情况 select top 20 sj.name,sjh.step_id,sjh.message,sjh.run_status ,msdb.dbo.agent_datetime(run_date,run_time) run_time,sjh.run_duration from msdb.dbo.sysjobhistory sjh inner join msdb.dbo.sysjobs sj on sjh.job_id=sj.job_id where sj.name='jobname' order by msdb.dbo.agent_datetime(run_date,run_time) desc
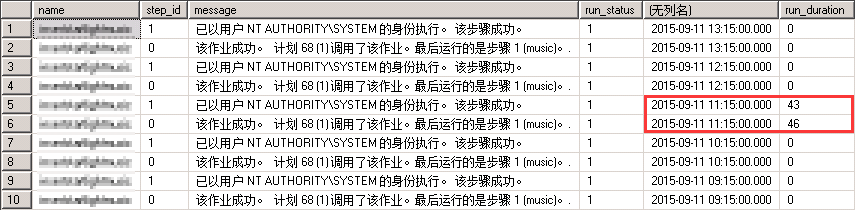
图7 作业历史执行时间
查询统计信息更新时间
SELECT STATS_DATE(object_id,stats_id) statsdate,* FROM sys.stats

图8 统计信息更新时间
数据清空再写入,导致统计信息更新,进而影响执行计划?现在查看统计信息是在11:15更新的,会不会是刚好清空表的时候,程序调用了过程,表中没数据,生成了一个表扫描的执行计划,之后就一直重用这个计划?总之就是表数据变更(清空)影响统计信息,进而影响执行计划的重新生成(表扫描),接着数据再次写入,统计信息会再次更新,但执行计划却还是旧的(表扫描),导致消耗变大。如果手动执行,它会依据新的统计信息,生成新的执行计划(索引查找+键查找)……找个时间测试下
12:05 2015/9/21 出现同样的现象,查看异常时高CPU过程缓存情况,显示的cached_time(2015-09-19 11:16:03.320)
图9 异常时的过程缓存
滚动条拉到后面,查看过程对应的执行计划(query_plan)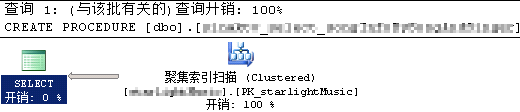
图10 异常时的执行计划
查看CPU信息跟踪表,找出此次CPU上涨的起始时间,意外地是这次并不像上次那样CPU一下就窜到40%,而是从早上(2015-09-21 07:16:07.153)涨到10%,然后一直维持在10%并逐渐上涨,7-11点偶尔会超过40%,但没有达到触发邮件提醒的条件。在(2015-09-21 12:05:00.437)服务器发出预警邮件。
分别在过程缓存的cached_time和CPU上涨的时间表点查看作业执行情况,单独从作业执行时间来看,每小时执行的作业根本就没有执行清空再写入的步骤
图11 cached_time前后作业执行时间
图12 CPU上涨前后作业执行时间
查看与清空表相关的过程对应的缓存情况
图13 作业1调用过程pro1
图14 作业2调用过程pro2
作业1计划是每天凌晨03:03执行一次,截图中cached_time(2015-09-20 03:03:00.497),last_execution_time(2015-09-21 12:06:01.050),但执行次数却高达32次。应该是其他地方有调用这个过程,查询没有依赖的过程,也没有其他作业调用此过程。
作业2是(03:15-22:59)每小时执行一次,从截图看恰好是42次。作业2调用的过程pro2,实际是先判断两张表的记录数是否一致,不一致就调用过程pro3(清空表再插入)。但是在缓存中却没有看到pro3的缓存情况。这就表明作业2是按计划执行,调用过程pro2,pro2检查表中记录数一直保持一致,所以就跳过没有执行过程pro3。
根据各过程缓存时间点,及CPU上涨时间,大致推测此次异常应该是由过程pro1引起(但不是作业1引起的),重点跟踪此过程的执行情况!
18:01 2015/9/24 收到CPU使用率预警邮件,查看异常时高CPU过程缓存情况,显示的cached_time(2015-09-24 07:24:06.050)

图15 异常时的过程缓存
查看与清空表相关的过程对应的缓存情况
图16 作业2调用过程pro2
图17 过程pro2调用pro3
作业2是(03:15-22:59)每小时执行一次,从截图看恰好是10次。作业2调用的过程pro2,实际是先判断两张表的记录数是否一致,不一致就调用过程pro3(清空表再插入)。pro3显示的cached_time(2015-09-24 14:15:00.717),execution_count(1),CPU信息跟踪表,此次CPU上涨的起始时间(2015-09-24 14:16:18.840)。基本可以确定作业2在14:15执行时调用了过程pro3,表中数据变更引起统计信息的变更,然后引起执行计划的重新生成,最终体现就是CPU上涨。只是当时的CPU消耗尚未达到触发邮件提醒的条件。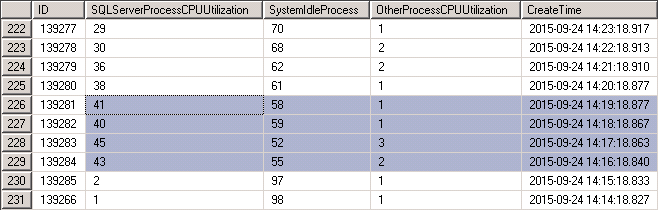
图18 CPU信息跟踪表