最近因为找工作的原因,都有两个周没有写博客了。今天来学习一个MapReduce编程场景。
这是一个处理基站数据的场景。基站数据被抽象成两个文件,分别是以“NET”开头和“POS”开头的文件。一个是记录用户的移动位置,另一个是记录用户的上网数据。任务是从大量的这些数据中提取出用户的移动轨迹,也就是用户到了哪些基站,分别停留了多久。有了这些数据,就可以勾勒出用户的移动轨迹。
ok,下面先看示例数据,然后直接上程序。
下面是POSITION文件,里面分别是imsi | imei | updatetype | loc | time
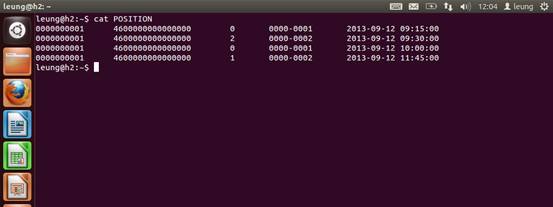
下面是NETWORK文件。里面分别是imsi | imei | loc | time | url

好了,看到输入数据的示例之后就上程序,然后在程序里面看Mapper与Reducer。总的来说,Mapper输出的的是<imsi|timeflag,position|t>,中间shuffle的过程之后,Reducer的输入为<imsi|timeflag,<position1|t1,position2|t2,position3|t3...>>,最后Reducer的输出为<imsi|timeflag|position|staytime>。其中,staytime是停留时间,position是位置。这里面的key使用了NullWritabe,故输出为空。
package org.leung.myhadoopdev;
import java.io.*;
import java.util.Date;
import java.text.SimpleDateFormat;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map.Entry;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class BaseStationDataPreprocess {
enum Counter
{
TIMESKIP,
OUTOFTIMESKIP,
LINESKIP,
USERSKIP
}
public static class Map extends Mapper<LongWritable,Text,Text,Text>{
String date;
String[] timepoint;
boolean dataSource;
public void setup(Context context) throws IOException {
this.date = context.getConfiguration().get("date");
this.timepoint = context.getConfiguration().get("timepoint").split("-");
FileSplit fs = (FileSplit)context.getInputSplit();//打开输入的文件
String fileName = fs.getPath().getName();//获取文件名(getName是Path的方法,getPath返回的是Path类)。
if( fileName.startsWith("POS")){ //POS文件就是true
dataSource = true;
}
else if( fileName.startsWith("NET")){//NET文件就是false
dataSource = false;
}
else{
throw new IOException("file is not correct!");
}
}
public void map (LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
TableLine tableLine = new TableLine();
try{
tableLine.set(line,this.dataSource,this.date,this.timepoint);
}
catch( LineException e )
{
if(e.getFlag()==-1)
context.getCounter(Counter.OUTOFTIMESKIP).increment(1); //接收到时间错误的记录,然后相应的counter加1
else
context.getCounter(Counter.TIMESKIP).increment(1);//格式不对,解析不了,然后相应的counter加1
return;
}
catch(Exception e)
{
context.getCounter(Counter.LINESKIP).increment(1);//读取失败,直接跳过整行
return;
}
context.write(tableLine.outKey(),tableLine.outValue());
}
}
public static class Reduce extends Reducer<Text,Text,NullWritable,Text>{
private String date;
private SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void setup(Context context){
this.date = context.getConfiguration().get("date");
}
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
String imsi = key.toString().split("\|")[0];//取出用户
String timeFlag = key.toString().split("\|")[1];//取出时间段
TreeMap<Long,String>uploads = new TreeMap<Long,String>();//需要键值对,并关心元素的自然排序时使用
String valueString;
for(Text val:values)
{
valueString = val.toString();
try
{
uploads.put(Long.valueOf(valueString.split("\|")[1]),valueString.split("\|")[0]);//t放在第一个位置,position放在第二个位置
}
catch (NumberFormatException e )
{
context.getCounter(Counter.TIMESKIP).increment(1);
continue;
}
}
try
{
Date tmp = this.formatter.parse( this.date + " "+ timeFlag.split("-")[1]+":00:00" );//组合最后时间出来
uploads.put((tmp.getTime() / 1000L), "OFF");//自己设定的一个最后时间OFF
HashMap<String,Float> locs = getStayTime(uploads);//需要键值对表示,并不关心顺序的
for(Entry<String,Float> entry : locs.entrySet()) //使用entry进行遍历
{
StringBuilder builder = new StringBuilder();
builder.append(imsi).append("|");
builder.append(entry.getKey()).append("|");
builder.append(timeFlag).append("|");
builder.append(entry.getValue());
context.write(NullWritable.get(),new Text(builder.toString()));
}
}catch (Exception e){
context.getCounter(Counter.USERSKIP).increment(1);
return;
}
}
//下面是计算停留时间,后一个时间减去前一个时间,如果间隔超过60分钟就认定为关机了。
private HashMap<String,Float> getStayTime(TreeMap<Long,String> uploads){ //uploads里面是<t,position>
Entry<Long, String> upload , nextUpload ;
HashMap<String, Float> locs = new HashMap<String,Float>();
Iterator<Entry<Long,String>> it = uploads.entrySet().iterator();
upload = it.next();
while(it.hasNext())
{
nextUpload = it.next();
float diff = (float)(nextUpload.getKey()-upload.getKey()) / 60.0f;
if(diff <= 60.0 )//时间间隔过大则代表关机
{
if(locs.containsKey(upload.getValue()))
locs.put(upload.getValue(),locs.get(upload.getValue())+diff);
else
locs.put(upload.getValue(),diff);
}
upload = nextUpload;
}
return locs;
}
}
public static void main(String args[]) throws Exception{
String input = "hdfs://172.17.150.7:9000/home/base";
String output = "hdfs://172.17.150.7:9000/home/output";
Configuration conf = new Configuration();
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.set("date", "2013-09-12");//设置指定的日期
conf.set("timepoint", "09-17-24");//设置指定的时间段
Job job = new Job(conf,"BaseStationDataPreprocess");
job.setJarByClass(BaseStationDataPreprocess.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path(input));
FileOutputFormat.setOutputPath(job,new Path(output));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
好。下面贴出TableLine这个类。这个类主要作用是解析每一行数据,提取需要的部分。
package org.leung.myhadoopdev;
import org.apache.hadoop.io.Text;
import java.text.ParseException;
import java.util.Date;
import java.text.SimpleDateFormat;
//自定义异常类
class LineException extends Exception{
private static final long serialVersionUID = 8245008693589452584L;
int flag;
public LineException(String msg,int flag){
super(msg);
this.flag = flag;
}
public int getFlag()
{
return flag;
}
}
//主要分析类
public class TableLine {
private String imsi,position,time,timeFlag;
private Date day;
private SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void set(String line,boolean source,String date,String[] timepoint) throws LineException{
String[] lineSplit = line.split(" ");
if(source)
{
this.imsi = lineSplit[0];
this.position = lineSplit[3];
this.time = lineSplit[4];
}
else
{
this.imsi = lineSplit[0];
this.position = lineSplit[2];
this.time = lineSplit[3];
}
if( !this.time.startsWith(date)) //检查时间是否与输入的相同
{
throw new LineException("",-1);//与输入时间不同,flag是-1
}
try
{
this.day = this.formatter.parse(this.time);//按照formatter的格式来解析输入的time格式
}
catch(ParseException e)
{
throw new LineException("",0);//格式不对,flag是0
}
//下面是判断时间是否在指定的时间段里面
int i = 0, n = timepoint.length;//数组中的元素个数
int hour = Integer.valueOf(this.time.split(" ")[1].split(":")[0]);//yyyy-MM-dd HH:mm:ss 提取HH
while (i < n && Integer.valueOf(timepoint[i] ) <= hour)
i++;
if(i<n)
{
if(i == 0)
this.timeFlag = ("00-" + timepoint[i]);//判断是否在时间段之前,然后输出时间段
else
this.timeFlag = ( timepoint[i-1]+"-"+timepoint[i]);
}
else
throw new LineException("",-1);//不是在指定的时间段里面
}
public Text outKey(){
return new Text (this.imsi + "|"+ this.timeFlag);
}
public Text outValue(){
long t =( day.getTime() / 1000L ); //用一个UNIX的时间,getTime本身就是返回一个unix的时间
return new Text(this.position + "|" + String.valueOf(t));
}
}
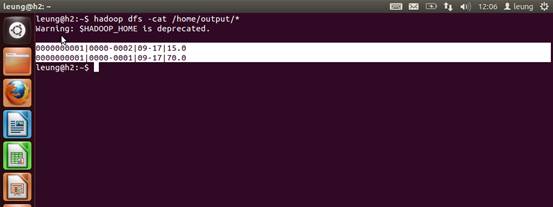
OK,下面看看示例数据的结果。可以看到这位同志在9-17点的时间段在0001这个基站附近逗留了70分钟,由在0002这个基站附近逗留了15分钟。
就学习到这里。谢谢大家!本人水平有限,请不吝指正!