1、安装环境是vmware workstation10.0模拟出三个虚拟节点,每一个节点安装Ubuntu12.04 LTS操作系统,主机名分别是hadoop1、hadoop2以及hadoop3.同时在每一个节点安装好java。安装方法同之前介绍的伪分布式安装方法一样。
2、接着是对三个节点的hosts文件进行配置,先用ifconfig命令查看三个节点的ip地址,然后用sudo vim /etc/hosts命令打开hosts文件,统一编辑如下:

3、配置完hosts文件之后,设置ssh无密码互联。先在每一节点输入sudo apt-get install ssh命令安装ssh。然后用ssh-keygen –t rsa命令产生密钥。将每一个节点id_rsa.pub都复制到authorized_keys,然后把每一个节点的公钥都互相复制各自的authorized_keys文件中,即可实现无密码互连。此时注意,本机到本机的免密码登录也是需要的!
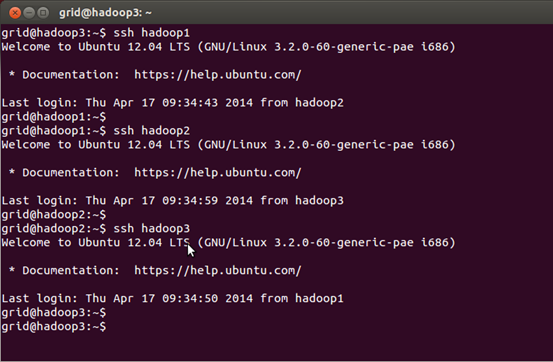
4、下面是进行hadoop1.2.1安装,只在hadoop1主机安装,然后使用scp -rp 命令复制到另外两个节点即可。
具体安装以及配置文件如图所示。
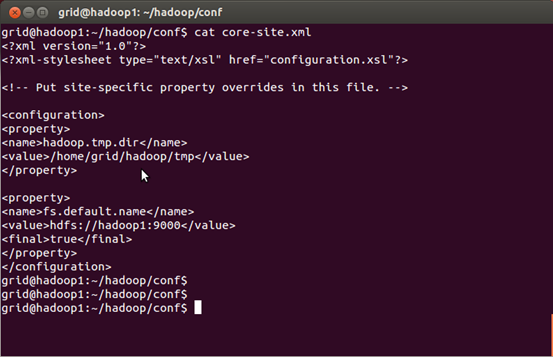
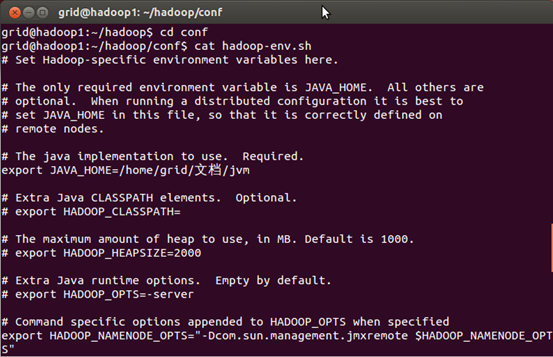
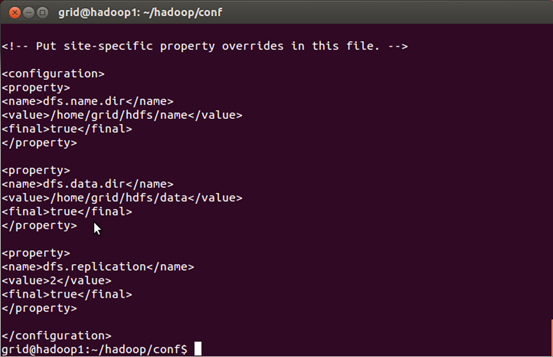

至此,配置完conf目录中的4个文件,同时需要在conf目录中的master文件添加作为master的主机名(我这里是hadoop1),在slaves文件中添加作为slaves的主机名(我这里是hadoop2,hadoop3)。即可进行格式化NAMENODE节点。以下截图是拍照上传,请多多见谅。
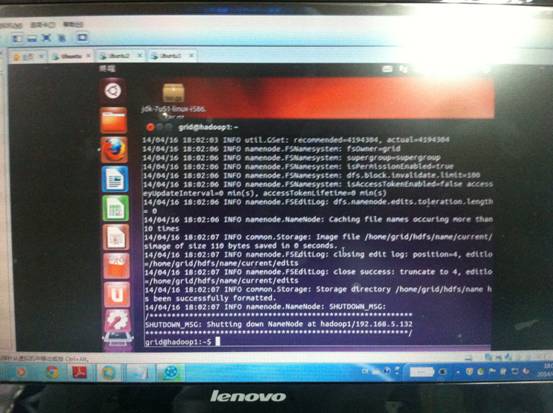
格式化后即可启动hadoop集群!
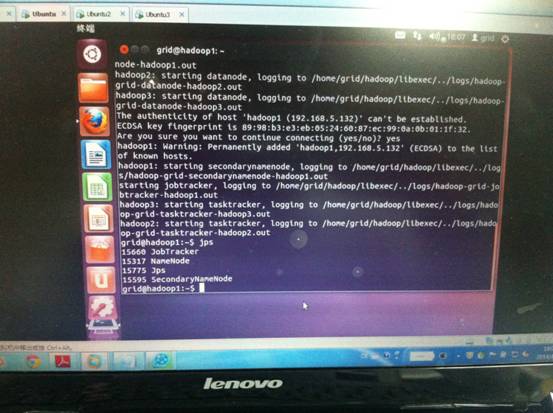
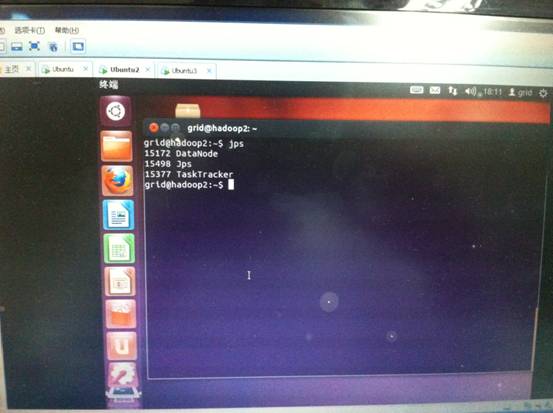
还可以用浏览器访问主机的50070以及50030端口分别查看集群的信息。
到这里,恭喜你!hadoop集群已经部署成功。
同时,可以说,如果在实际生产环境中,ssh免密码登录以及逐台机器手动写/etc/hosts文件的办法是不实际的,一般是使用DNS代替ssh免密码用NFS来共享文件。这种部署方式更加贴合实际生产环境。