雪碧图识别(CNN 卷积神经网络训练)
镀金的天空 是一个互联网技能认证网站, 都是些爬虫题目。其中有一道题 爬虫-雪碧图-2 需要使用到图片识别。所以模仿 mnist ,用 CNN 卷积神经网络训练一个模型,准确率达到 99.90% 。
# 基于 tensorflow 2.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==2.0.0
# 项目构成
├─glidesky
│ model.h5 # 模型文件
│ predict.py # 模型调用
│ train.py # 模型训练
│
├─data_source
│ │ data.h5 # 数据集文件
│ │ make_dataset.py # 生成数据集
│ │ spider.py # 爬虫
│ │
│ └─imgs # 存放采集图片
│
├─logs # 训练可视化日志
│
├─test # 测试图片
数据获取

数据获取,首先找到一页内容涵盖 0-9 所有数字,然后用爬虫将数字图片采集下来,以供后续作为深度学习的数据集。
- 因为每次请求都是不一样的图,但是数字是固定的,所以只要不断请求同一页即可
- 每次请求只保留 10 张图片,从而保证样本数据的均匀分布
- 采集过程较为耗时无聊,所以原计划采 100 万张,后面只采集了 45 万张
import re
import os
import uuid
import base64
import requests
from PIL import Image
from io import BytesIO
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
Cookie = 'your cookies'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': Cookie,
'Host': 'www.glidedsky.com',
'Referer': 'http://www.glidedsky.com/level/web/crawler-basic-2?page=1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
def get_img(text):
"""
:param text: 获取图片模板
:return:
"""
img_str = re.findall('base64,(.*?)"', text)[0]
img_fp = BytesIO(base64.b64decode(img_str.encode('utf-8')))
img = Image.open(img_fp)
return img
def crawler(url):
text = requests.get(url, headers=headers).text
img = get_img(text)
rows = BeautifulSoup(text, 'lxml').find_all('div', class_="col-md-1")
num_labels = list(str(123171140339373274129338158411319368))
num_imgs = []
for row in rows:
for div in row.find_all('div'):
css_name = div.get('class')[0].split(' ')[0]
tag_x = re.findall(f'.{css_name} {{ background-position-x:(.*?)px }}', text)
tag_y = re.findall(f'.{css_name} {{ background-position-y:(.*?)px }}', text)
width = re.findall(f'.{css_name} {{ (.*?)px }}', text)
height = re.findall(f'.{css_name} {{ height:(.*?)px }}', text)
tag_x = abs(int(tag_x[0]))
tag_y = abs(int(tag_y[0]))
width = int(width[0])
height = int(height[0])
box = (tag_x, tag_y, tag_x + width, tag_y + height)
num_imgs.append(img.crop(box))
save_list = [str(i) for i in range(10)]
for num_img, num_label in zip(num_imgs, num_labels):
if num_label in save_list:
file_name = f'./imgs/{num_label}_{uuid.uuid1()}.png'
num_img = num_img.resize((20, 20))
num_img.save(file_name)
save_list.remove(num_label)
os.makedirs('./imgs', exist_ok=True)
urls = []
for _ in range(90000):
url = f'http://www.glidedsky.com/level/web/crawler-sprite-image-2?page=999'
urls.append(url)
pool = ThreadPoolExecutor(max_workers=20)
for result in pool.map(crawler, urls):
...
制作数据集
将所有图片统一尺寸为 20*20 后,转为灰度值;对应的标签转为独热编码,通过 sklearn 随机切分训练集和测试集数据,最后保存为 h5 数据集文件。
- 测试集最好不要和训练集重叠,这样才能评估模型的泛化能力
- 保存数据集时,不事先进行预处理的原因:直接保存,数据文件大小为 190 M; 归一化后再保存,则为 1.9 G
- h5 层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件
- 独热编码即一位有效编码,比如 0-9 共十个数字,可以用一个长度为 10 的 list 表示。比如 2 是 [0,0,1,0,0,0,0,0,0,0],9 是 [0,0,0,0,0,0,0,0,0,1],以此类推;值可以通过 np.argmax() 获取。

import os
import h5py
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
images = []
labels = []
for path in os.listdir('./imgs'):
label = int(path.split('_')[0])
label_one_hot = [0 if i != label else 1 for i in range(10)]
labels.append(label_one_hot)
img = Image.open('./imgs/' + path).resize((20, 20)).convert('L')
img_arr = np.reshape(img, 20 * 20)
images.append(img_arr)
# 拆分训练集、测试集
train_images, test_images, train_labels, test_labels = train_test_split(images, labels, test_size=0.1, random_state=0)
with h5py.File('./data.h5', 'w') as f:
f.create_dataset('train_images', data=np.array(train_images))
f.create_dataset('train_labels', data=np.array(train_labels))
f.create_dataset('test_images', data=np.array(test_images))
f.create_dataset('test_labels', data=np.array(test_labels))
训练模型
构建卷积神经网络模型,喂数据(40万的训练集,4万的测试集),对模型进行训练。
- 数据集是由白底黑字的灰度图转成矩阵(20*20)构成的,每个数字是在 0-255 之间,黑色 0,白色 255。预处理将其转成黑底白字后,除以 255.0 即完成归一化。数据归一化后,有助于提高模型的准确度。为什么要归一化
- epochs,训练集的数据全部被训练一次,即为一个 epoch ; epochs 设置多次次合适,目前没有万能公式,需要不断尝试
- 模型编译的时候需要指定 optimizer 优化器、loss 损失函数、metrics 衡量指标等参数
- 模型训练的过程中,可以指定回调函数,比如保存模型、记录日志等等
- 训练过的模型,可以加载后继续训练
经过训练后,模型准确率达到了 99.91%

在测试集的准确率达到了 99.90%

import os
import h5py
import tensorflow as tf
from tensorflow.keras import layers, models
class Train:
def __init__(self):
# 最终模型存放路径
self.modelpath = './model.h5'
# 定义模型
if os.path.exists(self.modelpath):
self.model = tf.keras.models.load_model(self.modelpath)
print(f"{self.model} 模型加载成功,继续训练...")
else:
self.model = models.Sequential([
# 第1层卷积,卷积核大小为3*3,32个,28*28为待训练图片的大小
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(20, 20, 1)),
layers.MaxPooling2D((2, 2)),
# 第2层卷积,卷积核大小为3*3,64个
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 第3层卷积,卷积核大小为3*3,64个
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax'),
])
self.model.summary()
# 读取数据
with h5py.File('./data_source/data.h5', 'r') as f:
self.train_images = f['train_images'][()]
self.train_labels = f['train_labels'][()]
self.test_images = f['test_images'][()]
self.test_labels = f['test_labels'][()]
train_count, test_count = 400000, 40000
self.train_images = self.train_images[:train_count].reshape((train_count, 20, 20, 1))
self.train_labels = self.train_labels[:train_count]
self.test_images = self.test_images[:test_count].reshape((test_count, 20, 20, 1))
self.test_labels = self.test_labels[:test_count]
# 数据处理 归一化
self.train_images = 1 - self.train_images / 255.0
self.test_images = 1 - self.test_images / 255.0
def train(self):
# 可视化 tensorboard --logdir=D:GitHubantmanglidedskylogs
TensorBoardcallback = tf.keras.callbacks.TensorBoard(
log_dir='logs',
histogram_freq=1,
write_graph=True,
write_images=True,
update_freq=10000
)
self.model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
self.model.fit(self.train_images, self.train_labels, epochs=10, callbacks=[TensorBoardcallback])
self.model.save(self.modelpath)
def test(self):
self.model = tf.keras.models.load_model(self.modelpath)
test_loss, test_acc = self.model.evaluate(self.test_images, self.test_labels)
print("准确率: %.4f,共测试了%d张图片 " % (test_acc, len(self.test_labels)))
if __name__ == "__main__":
app = Train()
app.train()
app.test()
模型调用
模型的调用输入:归一化的三维矩阵(尺寸 20*20,需要转成黑底白字) 构成的列表;输出: 标签独热编码 构成的列表。
- 模型的输入应该与训练时的数据使用相同的处理方式
- 独热编码取最大值的下标,即代表的标签数字
最后,测试准备的这 5 张图,模型都能正确识别
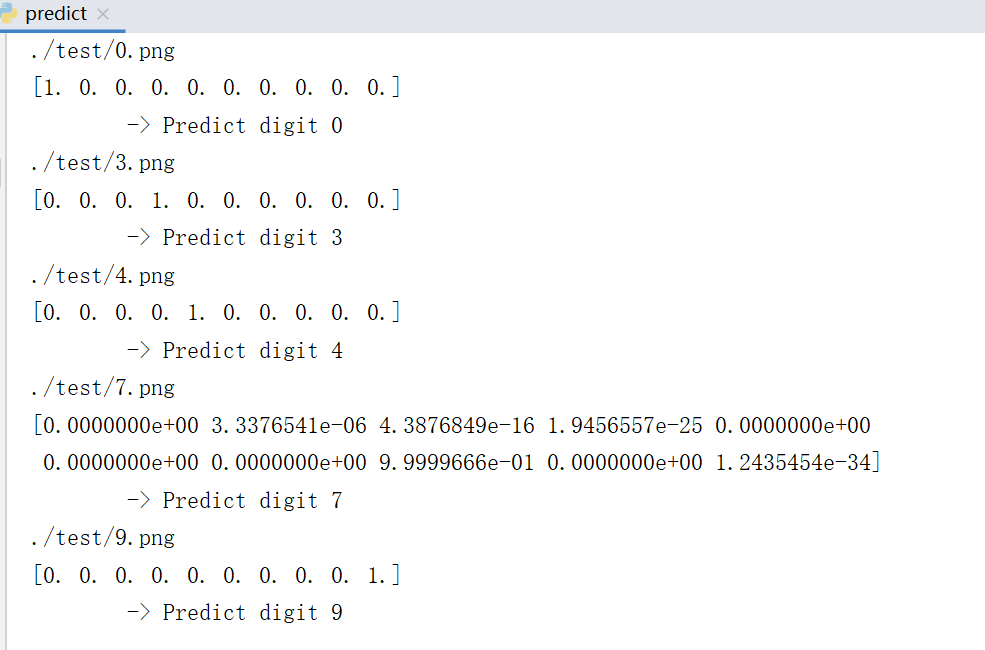
import numpy as np
import tensorflow as tf
from PIL import Image
class Predict(object):
def __init__(self):
self.cnn = tf.keras.models.load_model('./model.h5')
def predict(self, image_path):
# 以黑白方式读取图片
img = Image.open(image_path).resize((20, 20)).convert('L')
img_arr = 1 - np.reshape(img, (20, 20, 1)) / 255.0
x = np.array([img_arr])
# API refer: https://keras.io/models/model/
y = self.cnn.predict(x)
# 因为x只传入了一张图片,取y[0]即可
# np.argmax()取得最大值的下标,即代表的数字
print(image_path)
print(y[0])
print(' -> Predict digit', np.argmax(y[0]))
if __name__ == "__main__":
app = Predict()
app.predict('./test/0.png')
app.predict('./test/3.png')
app.predict('./test/4.png')
app.predict('./test/7.png')
app.predict('./test/9.png')
通过爬虫测试
直接在爬虫中调用模型,因为存在概率问题,所以多跑几次,就可以解决这道爬虫题目。有兴趣的话,可以参考完整的代码 glidedsky 通关笔记