第一步,生成一张最简单的词云图
1 from wordcloud import WordCloud 2 import matplotlib.pyplot as plt 3 #读取一个文本 4 txt = open('1.txt',encoding='utf-8').read() 5 #创建一个wordcloud对象 6 wc = WordCloud().generate(txt) 7 plt.imshow(wc) 8 plt.axis("off")#影藏坐标 9 plt.show()#将图片展示出来
Ctrl点击WordCloud()查看源代码

可以看到,里面有很多参数可以使用
这里我们用几个常用的
wc = WordCloud(background_color='white',scale=2,width=400,height=600,max_words=200,mask=None).generate(txt)
分别为设置背景色,scale可以理解为清晰度,越大图片越清晰,处理时间越长,width和height设置宽高,mask代表蒙版,也可以理解为贴图,我们后面会用到
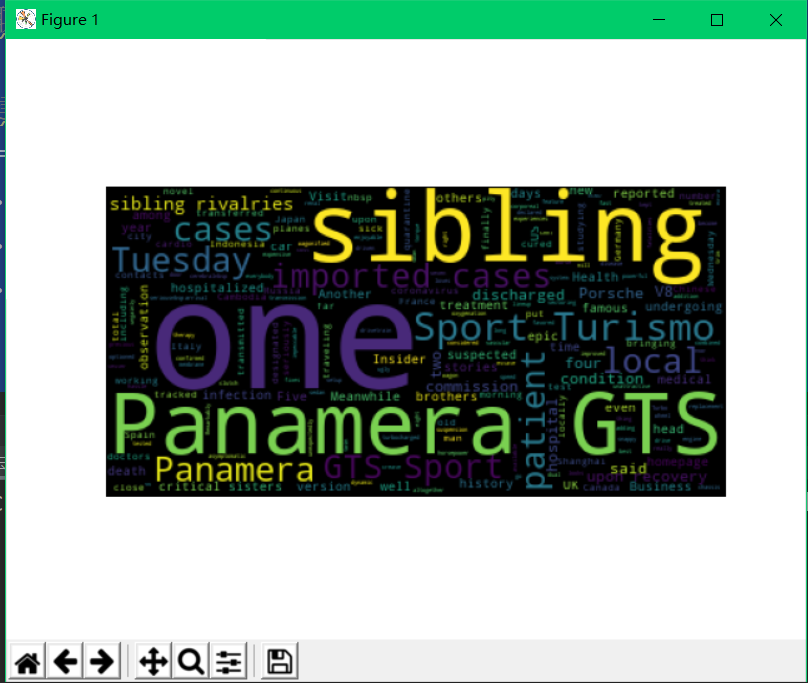
运行结果如图

接下来我们来尝试制作中文的词云图,wordcloud默认是不支持中文的,所有我们需要导入中文字体,否在会出现乱码
这时,我们在wordcloud中加入font_path="你字体的路径" 就可以解决 找不到就网上下一个
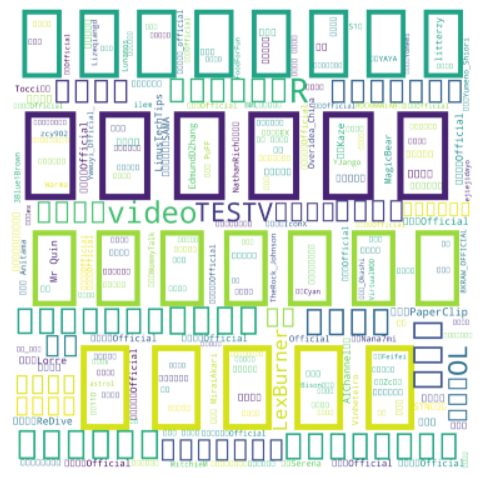

当然这个是我本身就已经分词分好了的情况,不然我们得用jieba库来分词,也很简单,加一段这个
1 word = jieba.lcut(text) 2 text =''.join(word)
这样的词云图看上去还是很low对吧,这时我们需要用图片来生成好看的词云图
1 rom wordcloud import WordCloud 2 import matplotlib.pyplot as plt 3 from PIL import Image 4 import numpy as np 5 #读取一个文本 6 text = open('1.txt',encoding='utf-8').read() 7 #创建一个wordcloud对象 8 image = np.array(Image.open("ai.png")) 9 wc = WordCloud(font_path="字体.ttc",#设置字体,默认不支持中文 10 background_color='white',#设置背景色为空时背景透明色 11 # max_font_size=400, #最大字号 12 # min_font_size=100,#最小字号 13 max_words=3000,#最大词数 14 mask=image, 15 scale=2, 16 width=800, 17 height=500,#如果mask非空,则width和height将被忽略 18 #random_state=10#设置随机数 19 ).generate(text=text) 20 plt.imshow(wc) 21 plt.axis("off")#影藏坐标 22 #wc.to_file("wc.png")#保存图片 23 plt.show()


有几个坑讲一下吧,文本格式看清楚是什么有可能是ANSI等,那就相应改一下,保存的话用to_file()清晰度会好一些