数组
1、定长数组和变长数组
package cn.gec.scala
import scala.collection.mutable.ArrayBuffer
object ArrayDemo {
def main(args: Array[String]) {
//初始化一个长度为8的定长数组,其所有元素均为0
val arr1 = new Array[Int](8)
//直接打印定长数组,内容为数组的hashcode值
println(arr1)
//将数组转换成数组缓冲,就可以看到原数组中的内容了
//toBuffer会将数组转换长数组缓冲
println(arr1.toBuffer)
//注意:如果new,相当于调用了数组的apply方法,直接为数组赋值
//初始化一个长度为1的定长数组
val arr2 = Array[Int](10)
println(arr2.toBuffer)
//定义一个长度为3的定长数组
val arr3 = Array("hadoop", "storm", "spark")
//使用()来访问元素
println(arr3(2))
//////////////////////////////////////////////////
//变长数组(数组缓冲)
//如果想使用数组缓冲,需要导入import scala.collection.mutable.ArrayBuffer包
val ab = ArrayBuffer[Int]()
//向数组缓冲的尾部追加一个元素
//+=尾部追加元素
ab += 1
//追加多个元素
ab += (2, 3, 4, 5)
//追加一个数组++=
ab ++= Array(6, 7)
//追加一个数组缓冲
ab ++= ArrayBuffer(8,9)
//打印数组缓冲ab
//在数组某个位置插入元素用insert
ab.insert(0, -1, 0)
//删除数组某个位置的元素用remove
ab.remove(8, 2)
println(ab)
}
}
|
2、遍历数组
1.增强for循环
2.好用的until会生成脚标,0 until 10 包含0不包含10

package cn.gec.scala
object ForArrayDemo {
def main(args: Array[String]) {
//初始化一个数组
val arr = Array(1,2,3,4,5,6,7,8)
//增强for循环
for(i <- arr)
println(i)
//好用的until会生成一个Range
//reverse是将前面生成的Range反转
for(i <- (0 until arr.length).reverse)
println(arr(i))
}
}
|
3.数组转换
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变

package cn.gec.scala
object ArrayYieldDemo {
def main(args: Array[String]) {
//定义一个数组
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//将偶数取出乘以10后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yield e * 10
println(res.toBuffer)
//更高级的写法,用着更爽
//filter是过滤,接收一个返回值为boolean的函数
//map相当于将数组中的每一个元素取出来,应用传进去的函数
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println(r.toBuffer)
}
}
|
4、数组常用算法
在Scala中,数组上的某些方法对数组进行相应的操作非常方便!

映射
在Scala中,把哈希表这种数据结构叫做映射
1、构建映射

2、获取和修改映射中的值

好用的getOrElse

注意:在Scala中,有两种Map,一个是immutable包下的Map,该Map中的内容不可变;另一个是mutable包下的Map,该Map中的内容可变
例子:

注意:通常我们在创建一个集合是会用val这个关键字修饰一个变量(相当于java中的final),那么就意味着该变量的引用不可变,该引用中的内容是不是可变,取决于这个引用指向的集合的类型
元组
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值。
1、创建元组
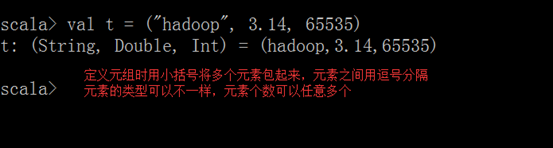
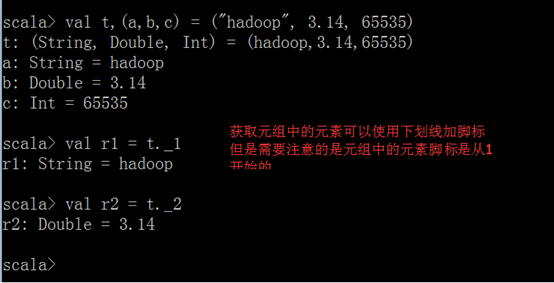
2、获取元组中的值
3、将对偶的集合转换成映射

4、拉链操作
zip命令可以将多个值绑定在一起
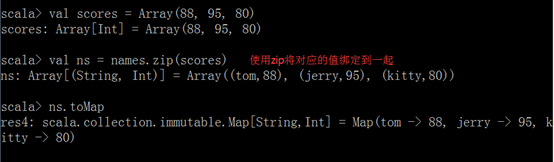
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质
在Scala中集合有可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后就不能改变了(注意与val修饰的变量进行区别)
1、序列
不可变的序列 import scala.collection.immutable._
在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
9 :: List(5, 2) :: 操作符是将给定的头和尾创建一个新的列表
注意::: 操作符是右结合的,如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))
package cn.gec.collect
object ImmutListDemo {
def main(args: Array[String]) {
//创建一个不可变的集合
val lst1 = List(1,2,3)
//将0插入到lst1的前面生成一个新的List
val lst2 = 0 :: lst1
val lst3 = lst1.::(0)
val lst4 = 0 +: lst1
val lst5 = lst1.+:(0)
//将一个元素添加到lst1的后面产生一个新的集合
val lst6 = lst1 :+ 3
val lst0 = List(4,5,6)
//将2个list合并成一个新的List
val lst7 = lst1 ++ lst0
//将lst0插入到lst1前面生成一个新的集合
val lst8 = lst1 ++: lst0
//将lst0插入到lst1前面生成一个新的集合
val lst9 = lst1.:::(lst0)
println(lst9)
}
}
|
可变的序列 import scala.collection.mutable._
package cn.gec.collect
import scala.collection.mutable.ListBuffer
object MutListDemo extends App{
//构建一个可变列表,初始有3个元素1,2,3
val lst0 = ListBuffer[Int](1,2,3)
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5)
//将lst1中的元素最近到lst0中, 注意:没有生成新的集合
lst0 ++= lst1
//将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
val lst2= lst0 ++ lst1
//将元素追加到lst0的后面生成一个新的集合
val lst3 = lst0 :+ 5
}
|
Set
不可变的Set
package cn.gec.collect
import scala.collection.immutable.HashSet
object ImmutSetDemo extends App{
val set1 = new HashSet[Int]()
//将元素和set1合并生成一个新的set,原有set不变
val set2 = set1 + 4
//set中元素不能重复
val set3 = set1 ++ Set(5, 6, 7)
val set0 = Set(1,3,4) ++ set1
println(set0.getClass)
}
|
可变的Set
package cn.gec.collect
import scala.collection.mutable
object MutSetDemo extends App{
//创建一个可变的HashSet
val set1 = new mutable.HashSet[Int]()
//向HashSet中添加元素
set1 += 2
//add等价于+=
set1.add(4)
set1 ++= Set(1,3,5)
println(set1)
//删除一个元素
set1 -= 5
set1.remove(2)
println(set1)
}
|
Map
package cn.gec.collect
import scala.collection.mutable
object MutMapDemo extends App{
val map1 = new mutable.HashMap[String, Int]()
//向map中添加数据
map1("spark") = 1
map1 += (("hadoop", 2))
map1.put("storm", 3)
println(map1)
//从map中移除元素
map1 -= "spark"
map1.remove("hadoop")
println(map1)
}
|
Scala写wordcount程序
val lines = List("hello java hello python","hello scala","hello scala hello java hello scala")
// 切分并压平
val words = lines.flatMap(_.split(" "))
// 把每个单词生成一个一个的pair
val tuples = words.map((_,1))
// 以key(单词)进行分组
val grouped = tuples.groupBy(_._1)
// 统计value长度
val sumed = grouped.mapValues(_.size)
// 排序
val sorted = sumed.toList.sortBy(_._2)
// 降序排列
val result = sorted.reverse
println(result)
lines.map(x=>x.split(" ")).flatten.map((_,1)).groupBy(_ _1).mapValues(t=>t.size)
lines.map(_.split(" ")).flatten.map((_,1)).groupBy(_ _1).mapValues(_.size).toList.sortBy(_ _2).reverse
具体过程如下:
