kafka简介
官网:它是一个分布式的流处理平台
Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
什么kafka:
它其实一个消息中间件,以类似于消息队列方式进行流数据读写操作,
主要用于流式数据管道处理,处理数据具体分布式、副本、容错性特征
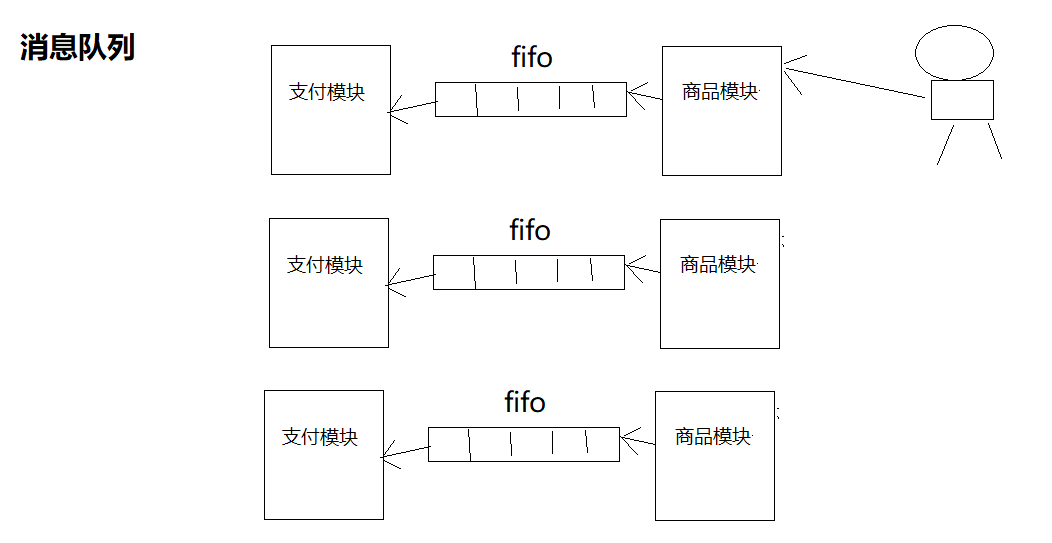
Kafka为什么会诞生
无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
能统一管理所有的消息队列,不是特殊需求不需要开发者自己去维护;
高效率的存储消息;
消费者能快速的找到想要消费的消息;
单机吞吐量
10万级别,这是kafka最大的优势,就是他的吞吐量高,一般配合大数据类的系统来进行实施数据计算,日志采集等场景
topic数据对吞吐量的影响
topic从几十个到上百个不等,但是topic越多,会很大程度的影响吞吐量,所以在同等机器下,kafka经量保证topic数量不要过度。如果要支撑大规模的topic的话,需要增加更多的集群资源。
时效性
负载均衡
可用性
非常高,kafka是分布是的,一个数据多个副本,少数机器的宕机,不会丢数据,不会导致不可用
消息可靠
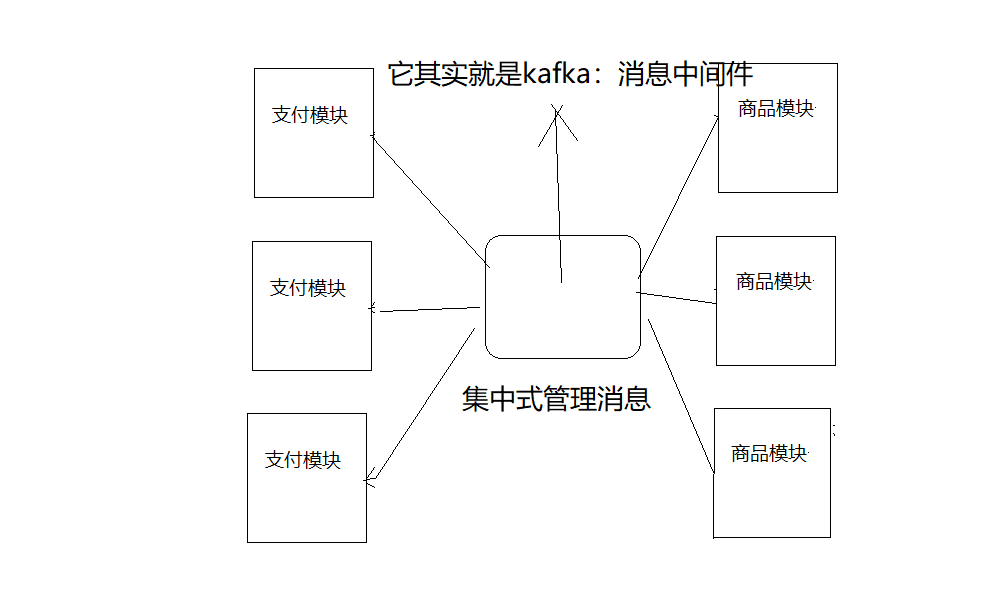
概述:
1、它读写数据是类似于一个消息系统
消息系统作用:
1、解耦

Kafka架构模型
Producer:生产者
Consumer:消费者
Broker:kafka服务器(盘子)
Topic:数据抽象的集合
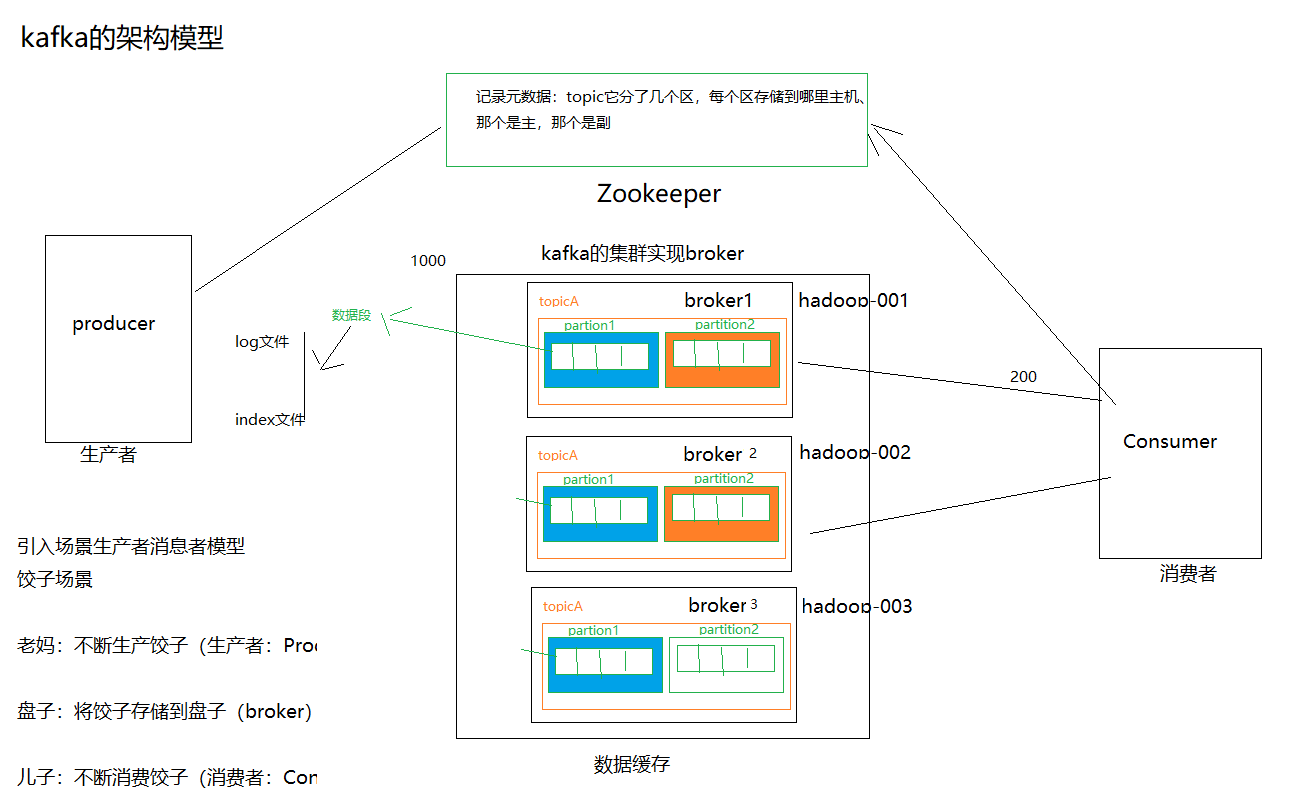
Producer :消息生产者,就是向kafka broker发消息的客户端。
Consumer :消息消费者,向kafka broker取消息的客户端。
topic:主题,里面是一类消息的抽象的集合,说白了这下面就是用来装各种数据的
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
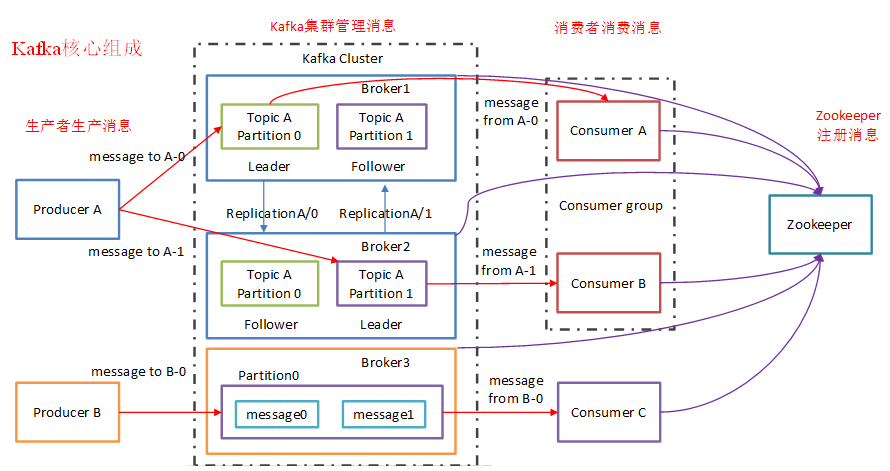
Kafka模型组件
Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
kafka集群安装配置
kafka的安装
三台机器安装zookeeper
注意:安装zookeeper之前一定要确保三台机器时钟同步
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org;
三台机器配置文件修改
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/bigdatasoftware/zookeeper-3.4.13/zkdata
dataLogDir=/home/hadoop/bigdatasoftware/zookeeper-3.4.13/zkdata
clientPort=2181
autopurge.purgeInterval=1
autopurge.snapRetainCount=3
server.1=hadoop-001:2888:3888
server.2=hadoop-002:2888:3888
server.3=hadoop-003:2888:3888
三台机器分别在/export/servers/zookeeper-3.4.9/zkData/data 目录下添加文件myid,并编辑每个文件中的内容
hadoop-001 机器myid内容为20
hadoop-002机器myid内容为21
hadoop-003机器myid内容为22
三台机器启动zookeeper
bin/zkServer.sh start
三台机器安装kafka集群
下载kafka安装压缩包
http://archive.apache.org/dist/kafka/
上传压缩包并解压
这里统一使用 kafka_2.11-1.0.0.tgz 这个版本
修改kafka配置文件
第一台机器修改kafka配置文件server.properties
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/hadoop/bigdatasoftware/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=hadoop-001:2181,hadoop-002:2181,hadoop-003:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=hadoop-001
第二台机器修改kafka配置文件server.properties
broker.id=1
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/hadoop/bigdatasoftware/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=hadoop-001:2181,hadoop-002:2181,hadoop-003:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=hadoop-002
第三台机器修改kafka配置文件server.properties
broker.id=2
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/hadoop/bigdatasoftware/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=hadoop-001:2181,hadoop-002:2181,hadoop-003:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=hadoop-003
启动kafka集群
三台机器启动kafka服务
./kafka-server-start.sh ../config/server.properties
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 & 后台启动命令