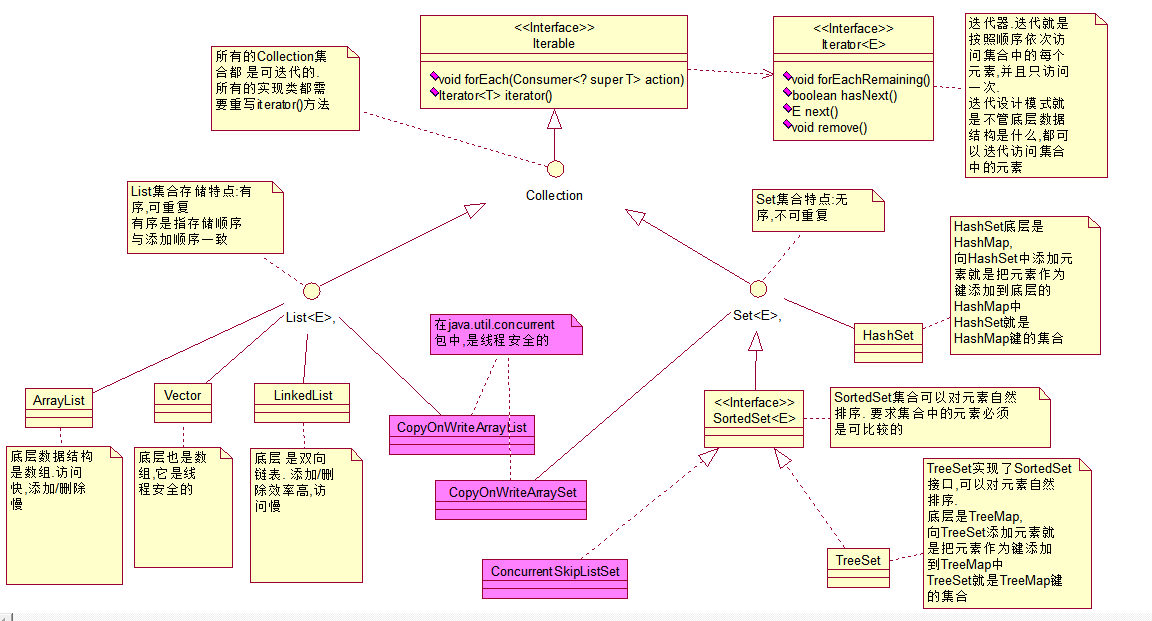
集合分为两大类:
Collection集合: 单个存储
Map集合: 按<键,值>对的形式存储, <员工姓名,工资>
Collection类关系图
Collection常见方法
|
|
|
|
|
addAll |
|
|
clear |
|
|
|
|
|
isEmpty |
|
iterator |
|
|
|
|
|
|
removeAll |
|
|
size |
|
Object |
toArray |
|
|
toArray |
-------------------------------------------------------------
List接口继承了Collection接口. Collection的所有操作List都可以继承到
List存储特点:
有序,可重复
List集合为每个元素指定一个索引值,增加了针对索引值的操作
add(index, o) remove(index) get(index) set(index, o)
sort( Comparator )
》》》》》》》》》》》》》》
ArrayList与Vector
1) 底层是数组, 访问快,添加删除慢
2) ArrayList不是线程安全的,Vector是线程安全的
3) ArrayList初始化容量: 10 , Vector初始化容量: 10
4) 扩容ArrayList按1.5倍, Vector按2倍大小扩容
---------------------------------------------------------------------------
Set集合
无序, 存储顺序可能与添加顺序不一样
不能存储重复的数据
---------------------------------------------------------------
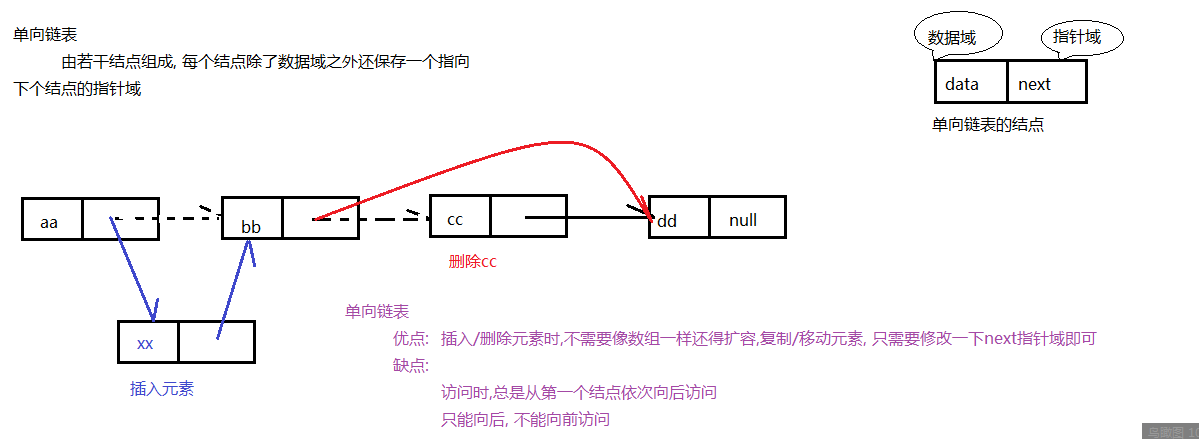
单向链表
由若干个节点组成,每个节点除了数据域之外还保存一个指向下个节点的指针域。
优点:
插入/删除元素时,不需要像数组一样还得扩容、复制/移动元素,只需要修改一下next指针域即可。
缺点:
访问时,总是从第一个结点依次向后访问,只能向后访问,不能向前访问。
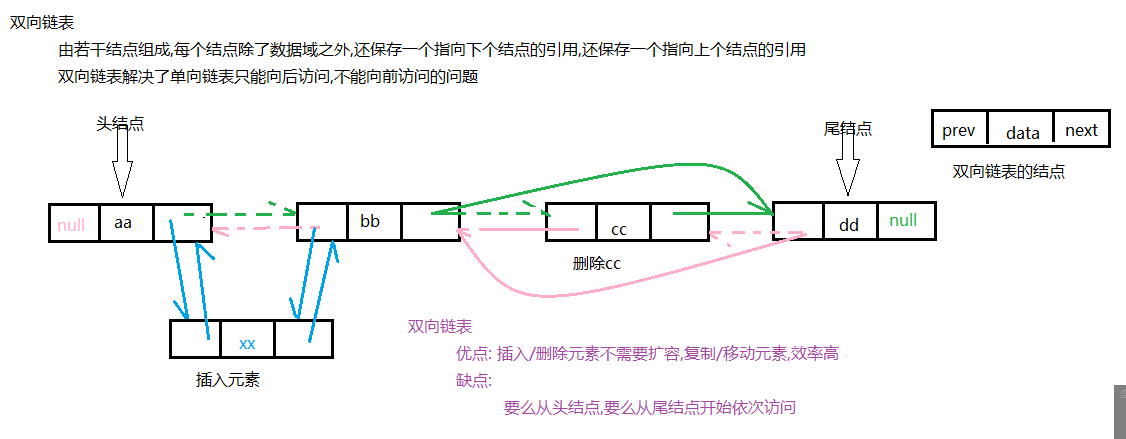
双向链表
LinkedList底层采用双向链表
使用LinkedList模拟栈结构。栈结构特点:后进先出。
Push()
Pop()
使用LinkedList,模拟队列。队列:先进先出。
Offer()
Poll();
单项链表示例图:
双向链表示例图:
--------------------------------------------------------------
HashSet
* 1)底层是HashMap
* 2)向HashSet添加元素就是把该元素作为键添加到底层的HashMap中
* 3) HasetSet就是HashMap键的集合
* 4) 存储在HashSet中的元素, 需要重写equals()/hashCode()方法
2 TreeSet
TreeSet实现了SortedSet接口,可以对集合中的元素自然排序, 要求元素必须是可比较的
1) 在TreeSet构造方法中指定Comparator比较器
2) 如果没有Comparator比较器,元素的类实现Comparable接口
* TreeSet
* 1)TreeSet集合可以对元素排序, 要求元素必须是可比较的
* (1)在构造方法中指定Comparator比较器
* (2)如果没有Comparator,元素的类需要实现Comparable接口
* TreeSet是先选择Comparator,
在没有Comparator的情况下,再找Comaprable
* 2)TreeSet底层是TreeMap
* 3)向TreeSet添加元素就是把元素作为键添加到底层的TreeMap中
* 4)TreeSet就是TreeMap键的集合
TreeSet
可以对元素排序,要求元素必须是可以比较的。
TreeSet是先选择Comparator,没有Comparator再选择
Comparable。
TreeSet的底层是TreeMap
TreeSet如果比较两个元素相同,只能存在一个。
要非常注意,比较方法。TreeSet集合根据Comparator/Comparable的比较结果是否为0,来判断元素是否为同一个元素的。
==================================
3.5 Collection小结
Collection单个存储
基本操作:
add(o), remove(o), contains(o), size(),
iterator() hasNext(), next(), remove()
----List
特点:
有序,存储顺序与添加顺序一样
可重复,可以存储重复的数据
为每个元素指定一个索引值
新增的操作:
add(inex, o ), remove(index), get(index), set(index, newValue)
sort(Comparator)
--------ArrayList
底层是数组, 访问快,添加删除慢
初始化容量:10
扩容: 1.5 倍
--------Vector
底层是数组, 它是线程安全的, ArrayList不是线程安全的
初始化容量: 10
扩容: 2倍
--------LinkedList
底层是双向链表, 添加/删除效率高,访问慢
新增的操作:
addFirst(o) / addLast(o)removeFirst()/removeLast()
getFirst()/getLast()
push(o)/pop()
offer(o)/poll()
*******应用场景***************************************************
存储可以重复的数据选择List集合
如果以查询访问为主,选择ArrayList
如果频繁的进行添加/删除操作,选LinkedList
如果开发多线程程序,选择juc包中的CopyOnWriterArrayList
-------注意------------------------------------------------------------------------------------------------
List集合,在contains(o), remove(o)操作时,需要比较元素,调用equals()方法
如果在List存储自定义类型数据,需要重写equals()/hashCode()
----Set
特点:
无序:存储顺序与添加顺序可能不一样
不可重复,存储的数据不允许重复
--------HashSet
底层是HashMap
向HashSet添加元素就是把该元素作为键添加到底层的HashMap中
HashSet就是HashMap键的集合
--------TreeSet
TreeSet实现了SortedSet接口,可以对元素自然排序,要求元素必须 是可比较的
(1)在构造方法中指定Comaparator比较器
(2)没有Comaprator,需要让元素的类实现Comaparable接口
TreeSet是先选择Comparator,在没有Comparator的情况下,再选择Comparable
TreeSet底层是TreeMap
向TreeSet添加元素就是把该元素作为键添加到底层的TreeMap中
TreeSet就是TreeMap键的集合
******应用场景*******************************************************
如果存储不重复的元素使用Set集合
如果不需要排序就使用HashSet
如果需要排序就选择TreeSet
-----注意--------------------------------------------------------------------------------------------------
HashSet中的元素需要重写equals()/hashCode()方法
TreeSet集合中判断是否相同的元素, 根据Comparator/Comparable比较结果是否为0来判断
===========================================
Map是以键值对存储数据
如<员工姓名,工资>, <学生姓名,成绩>…
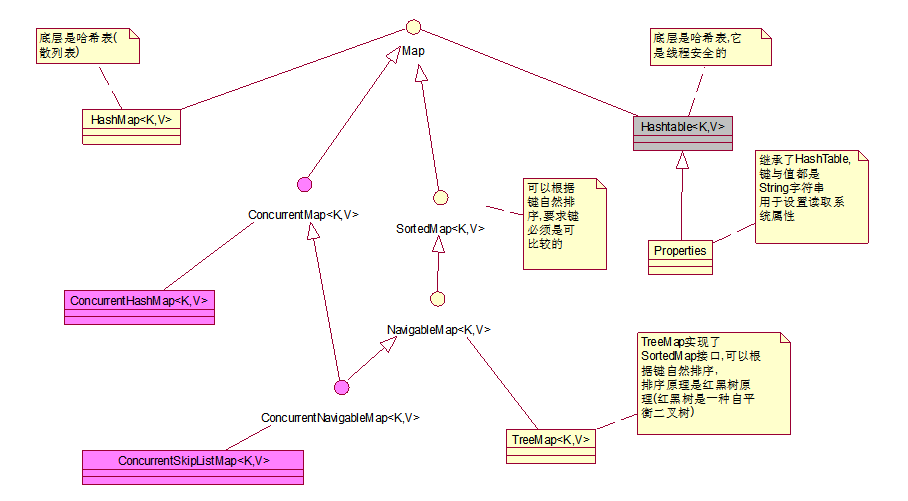
-----------------------------------------------------
|
|
clear |
|
|
containsKey |
|
|
containsValue |
|
entrySet |
|
|
|
|
|
|
forEach |
|
|
isEmpty |
|
keySet |
|
|
|
putAll |
|
|
|
|
|
|
|
|
size |
|
values |
HashMap工作原理图:
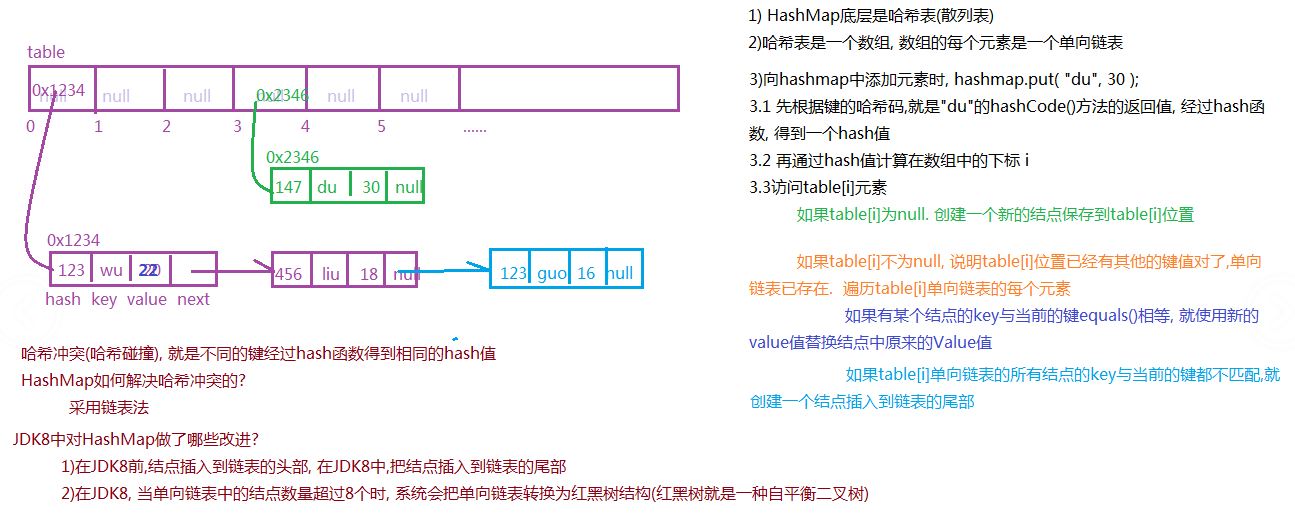
获取元素图:

HashMap
* 1)底层是哈希表,哈希表是一个数组,数组的每个元素是一个单向链表,数组元素实际存储的是单向链表第一个结点的引用
* 2)默认初始化容量: 16
* 3)默认加载因子: 0.75, 当键值对的数量大于 容量 * 加载因子时, 数组扩容
* 4)扩容:2倍
* 5)HashMap的键与值都可以为null
* 6)在定义Hashmap时,可以指定初始化容量,系统会自动调整为2的幂次方,即把17~31之间的数调整为32, 把33~63之间的数调整为64
* 为了能够快速计算数组的下标
-------------------------------
HashTable
* 1)底层是哈希表, 哈希表就是一个数组,数组的元素是一个单向链表,数组元素实际存储的是单向链表第一个结点的引用
* 2)默认初始化容量: 11
* 3)加载因子: 0.75
* 4)扩容:2倍 + 1
* 5)HashTable的键与值都不能为null
* 6)在定义时可以指定初始化容量, 不会调整大小
* 7) HashTable是线程安全的,
HashMap不是线程安全的
--------------------------------------------------------------
Properties
Properties继承了HashTable
键与值都是String字符串
经常用于设置/读取系统属性值
常用 方法:
setProperty(属性名, 属性值)
getProperty(属性名)
-----------------------------------------------------
TreeMap
* TreeMap实现了SortedMap接口,可以根据键自然排序, 要求键必须是可比较的
* 1)在构造方法中指定Comparator比较器
* 2)没有Comparator时,键要实现Comparable接口
* 对于TreeMap来说,先判断是否有Comparator,有的话就按Comparator比较; 如果没有Comaparator,系统要查看键是否实现了Comparable接口
* 对于程序员来说,一般情况下通过Comparable定义一个默认的比较规则(绝大多数使用的排序规则), 通过Comparator可以定义很多不同的排序规则
TreeMap是根据二叉树原理实现排序的
二叉树原理图示例:
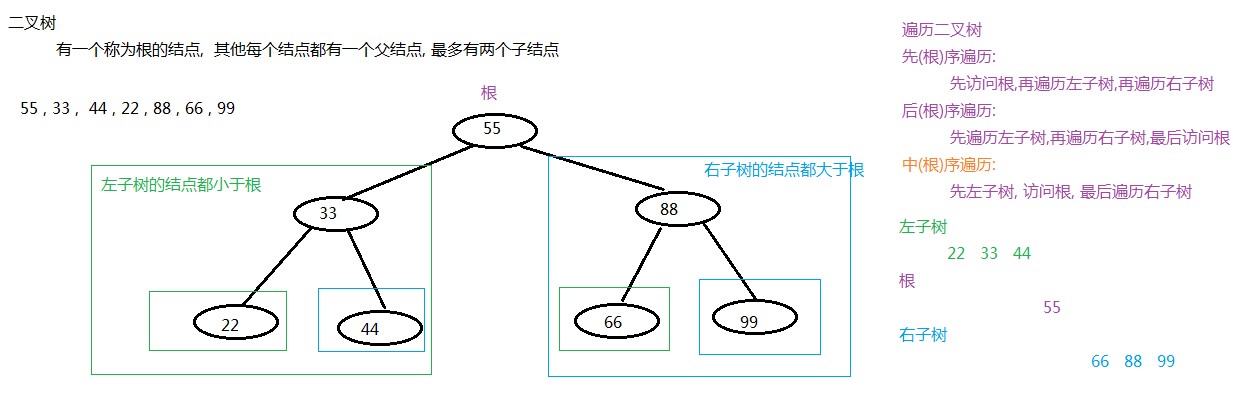
-----------------------------------------------------------------------------------------
Map小结
Map是按<键,值>对的形式存储数据
基本操作:
put(k,v) remove(k) remove(k,v)
containsKey(k) containsValue(v) get(k) size()
keySet() values() entrySet()
replace( k , v)
---- HashMap
底层是哈希表(散列表), 哈希表是一个数组,数组的每个元素是一个单向链表,数组元素其实存储的是单向链表的第一个结点的引用
初始化容量: 16
扩容: 2倍
键与值可以为null
指定初始化容量,系统会调整为2的幂次方
----HashTable
底层是哈希表(散列表), 它是线程安全的,HashMap不是线程安全的
初始化容量: 11
扩容: 2倍+1
键与值 不 可以为null
指定初始化容量,系统不调整
-------- Properties
继承了HashTable,
键与值都是String字符串
经常用来设置/读取系统属性
一般把属性保存在配置文件中, 可以通过Properties读取
----TreeMap
实现了SortedMap接口,可以根据键自然排序, 要求键必须是可比较的
1) 在构造方法中指定Comparator比较器
2) 没有Comparator时, 键要实现Comparable接口
对于 TreeMap来说,先选择Comparator,
对于 开发人员来说,一般让键实现Comparable接口定义一个默认的比较规则,通过Comparator可以定义其他不同的比较规则
TreeMap的键是根据红黑树排序的,红黑树是一种自平衡二叉树
*****应用场景**********************************************************
如果不需要根据键排序选择HashMap
如果需要键排序,选择TreeMap
开发多线程程序,一般不使用HashTable, 使用juc包中的ConcurrentHashMap,如果要根据键排序就使用juc包中的ConcurrentSkipListMap. ConcurrentHashMap采用分段锁协议,默认分为16段锁,并发效率高.
--------注意------------------------------------------------------------------------------------
HashMap,HashTable的键需要重写equals()/hashCode()
TreeMap的键是根据Comparator/Comparable的比较结果是否为0来判断是否相同的键