继承
继承是一种创建新类的方式,在Python中,新建的类可以继承一个或多个父类,新建的类可称为子类或派生类,父类又可称为基类或超类
class ParentClass1: #定义父类
pass
class ParentClass2: #定义父类
pass
class SubClass1(ParentClass1): #单继承
pass
class SubClass2(ParentClass1,ParentClass2): #多继承
pass
通过类的内置属性__bases__可以查看类继承的所有父类
SubClass2.__bases__ #和上面链接的 (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
在Python2中有经典类与新式类之分,没有显式地继承object类的类,以及该类的子类,都是经典类。
显式地继承object的类,以及该类的子类,都是新式类。而在Python3中,即使没有显式地继承object,也会默认继承该类,如下
>>> ParentClass1.__bases__ (<class ‘object'>,) >>> ParentClass2.__bases__ (<class 'object'>,)
因而在Python3中统一都是新式类
继承与抽象
要找出类与类之间的继承关系,需要先抽象,再继承。抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类
class Student:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def choose(self):
print('%s is choosing a course' %self.name)
class Teacher:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def teach(self):
print('%s is teaching' %self.name)
类Teacher与Student之间存在重复的代码,老师与学生都是人类,所以我们可以得出如下继承关系,实现代码重用
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Student(People):
def choose(self):
print('%s is choosing a course' %self.name)
class Teacher(People):
def teach(self):
print('%s is teaching' %self.name)
Teacher类内并没有定义__init__方法,但是会从父类中找到__init__,因而仍然可以正常实例化,如下
>>> teacher1=Teacher('lili','male',18)
>>> teacher1.school,teacher1.name,teacher1.sex,teacher1.age
('清华大学', 'lili', 'male', 18)
属性查找
有了继承关系,对象在查找属性时,先从对象自己的__dict__中找,如果没有则去子类中找,然后再去父类中找
class Foo:
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1()
class Bar(Foo):
def f1(self):
print('Foo.f1')
b=Bar()
>>> b.f2()
Foo.f2
Foo.f1
b.f2()会在父类Foo中找到f2,先打印Foo.f2,然后执行到self.f1()
即b.f1(),仍会按照:对象本身->类Bar->父类Foo的顺序依次找下去,在类Bar中找到f1,因而打印结果为Foo.f1
父类如果不想让子类覆盖自己的方法,可以采用双下划线开头的方式将方法设置为私有的
class Foo:
def __f1(self): # 变形为_Foo__fa
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.__f1() # 变形为self._Foo__fa,因而只会调用自己所在的类中的方法
class Bar(Foo):
def __f1(self): # 变形为_Bar__f1
print('Foo.f1')
b=Bar()
b.f2() #在父类中找到f2方法,进而调用b._Foo__f1()方法,同样是在父类中找到该方法
Foo.f2
Foo.f1
继承的实现原理
4.1 菱形问题
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的
这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”)
菱形其实就是对下面这种继承结构的形象比喻
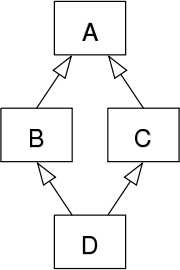
A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。 这种继承结构下导致的问题称之为菱形问题: 如果A中有一个方法,B和/或C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法:B的还是C的?如下所示
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B,C):
pass
obj = D()
obj.test() # 结果为:from B
要想搞明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
继承原理
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
D.mro() # 新式类内置了mro方法可以查看线性列表的内容,经典类没有该内置该方法 [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
子类会先于父类被检查多个父类会根据它们在列表中的顺序被检查如果对下一个类存在两个合法的选择,选择第一个父类
深度优先和广度优先
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
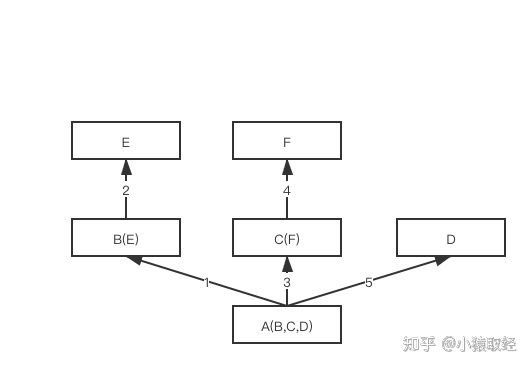
class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
# def test(self):
# print('from A')
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''
obj = A()
obj.test() # 结果为:from B
# 可依次注释上述类中的方法test来进行验证
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先

class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->G->C->F->D->object
# 可依次注释上述类中的方法test来进行验证,注意请在python2.x中进行测试
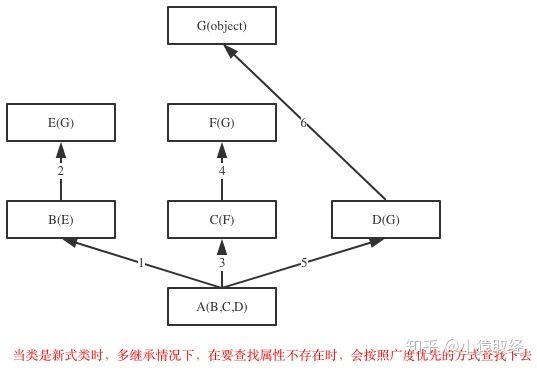
class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->C->F->D->G->object
# 可依次注释上述类中的方法test来进行验证
Python Mixins机制
# 多继承的正确打开方式:mixins机制 # mixins机制核心:就是在多继承背景下尽可能地提升多继承的可读性 # ps:让多继承满足人的思维习惯=》什么"是"什么
一个子类可以同时继承多个父类,这样的设计常被人诟病,一来它有可能导致可恶的菱形问题,二来在人的世界观里继承应该是个”is-a”关系。
比如轿车类之所以可以继承交通工具类,是因为基于人的世界观,我们可以说:轿车是一个(“is-a”)交通工具,
而在人的世界观里,一个物品不可能是多种不同的东西,因此多重继承在人的世界观里是说不通的,它仅仅只是代码层面的逻辑。不过有没有这种情况,一个类的确是需要继承多个类呢? 答案是有,我们还是拿交通工具来举例子: 民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass
民航飞机和直升飞机和汽车都属于交通工具,如果我们要解决民航飞机和直升飞机的代码冗余把飞行功能提取到交通工具类中。会导致汽车也能飞,这就违反了我们设置汽车类的原则。
多继承解决了我们代码冗余问题,也没有违反汽车类的原则。
但是多继承又给我们带来新的问题,程序可读性差。
这里引入一种规范,如果我们需要为多种类去总结一类功能,我们可以定义一个特殊的功能类,以Mixin为结尾,在集成时放在唯一父类的左边。
Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的
并不是用来标识子类的从属"is-a"关系的,所以Mixins机制本质仍是多继承,但同样遵守”is-a”关系
使用Mixin类实现多重继承要非常小心
- 首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀
- 其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is-a”原则,只能继承一个标识其归属含义的父类
- 然后,它不依赖于子类的实现
- 最后,子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)
派生与方法重用
子类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找,例如每个老师还有职称这一属性,我们就需要在Teacher类中定义该类自己的__init__覆盖父类的
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Teacher(People):
def __init__(self,name,sex,age,title): # 派生
self.name=name
self.sex=sex
self.age=age
self.title=title
def teach(self):
print('%s is teaching' %self.name)
obj=Teacher('lili','female',28,'高级讲师') #只会找自己类中的__init__,并不会自动调用父类的
print(obj.name,obj.sex,obj.age,obj.title) #lili female 28 高级讲师
很明显子类Teacher中__init__内的前三行又是在写重复代码,若想在子类派生出的方法内重用父类的功能,有两种实现方式
“指名道姓”地调用某一个类的函数==》不依赖于继承关系
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Teacher(People):
def __init__(self,name,sex,age,title): # 派生
People.__init__(self,name,sex,age) #调用的是函数,因而需要传入self,
self.title=title
def teach(self):
print('%s is teaching' %self.name)
obj=Teacher('lili','female',28,'高级讲师')
print(obj.name,obj.sex,obj.age,obj.title) #lili female 28 高级讲师
super()调用父类提供给自己的方法=》严格依赖继承关系
调用super()会得到一个特殊的对象,该对象会参照发起属性查找的那个类的mro,去当前类的父类中找属性
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Teacher(People):
def __init__(self,name,sex,age,title): # 派生
#super(Teacher,self).__init__(name,sex,age) #在Python2中super的使用需要完整地写成super(自己的类名,self) ,而在python3中可以简写为super()。
super().__init__(name,sex,age) #调用的是方法,自动传入对象
self.title=title
def teach(self):
print('%s is teaching' %self.name)
obj=Teacher('lili','female',28,'高级讲师')
print(obj.name,obj.sex,obj.age,obj.title) #lili female 28 高级讲师
这两种方式的区别是:
方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super()仍然会按照MRO继续往后查找
class A: #A没有继承B
def test(self):
super().test()
class B:
def test(self):
print('from B')
class C(A,B):
pass
obj=C() # 属性查找的发起者是类C的对象obj,所以中途发生的属性查找都是参照C.mro()
obj.test()
print(C.mro()) #[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
# 在代码层面A并不是B的子类,但从MRO列表来看,属性查找时,就是按照顺序C->A->B->object,B就相当于A的“父类”
obj.test()首先找C自己下面有没有test()方法,发现没有再到A下查找test()方法,发现有test()方法,执行super().test()会基于MRO列表(以C.mro()为准)
当前所处的位置(当前找到A,下一个是B)继续往后查找test(),然后在B中找到了test方法并执行。
关于在子类中重用父类功能的这两种方式,使用任何一种都可以,但是在最新的代码中还是推荐使用super()
组合
在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码的重用性问题。
不同的是:继承是一种“是”的关系,比如老师是人、学生是人,当类之间有很多相同的之处,应该使用继承;
而组合则是一种“有”的关系,比如老师有生日,老师有多门课程,当类之间有显著不同,并且较小的类是较大的类所需要的组件时,应该使用组合,如下示例
class Course:
def __init__(self,name,period,price):
self.name=name
self.period=period
self.price=price
def tell_info(self):
print('<%s %s %s>' %(self.name,self.period,self.price))
class Date:
def __init__(self,year,mon,day):
self.year=year
self.mon=mon
self.day=day
def tell_birth(self):
print('<%s-%s-%s>' %(self.year,self.mon,self.day))
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
#Teacher类基于继承来重用People的代码,基于组合来重用Date类和Course类的代码
class Teacher(People): #老师是人
def __init__(self,name,sex,age,title,year,mon,day):
super().__init__(name,age,sex)
self.birth=Date(year,mon,day) #老师有生日
self.courses=[] #老师有课程,可以在实例化后,往该列表中添加Course类的对象
def teach(self):
print('%s is teaching' %self.name)
python=Course('python','3mons',3000.0)
linux=Course('linux','5mons',5000.0)
teacher1=Teacher('lili','female',28,'博士生导师',1990,3,23)
# teacher1有两门课程
teacher1.courses.append(python)
teacher1.courses.append(linux)
# 重用Date类的功能
teacher1.birth.tell_birth()
# 重用Course类的功能
for obj in teacher1.courses:
obj.tell_info()
此时对象teacher1集对象独有的属性、Teacher类中的内容、Course类中的内容于一身(都可以访问到),是一个高度整合的产物