A Lexicon-Based Graph Neural Network for Chinese NER 基于词汇的中文NER图神经网络
用于顺序命名字符和单词信息的中文命名实体识别(NER)的递归神经网络(RNN)取得了巨大的成功。 但是,链结构和缺乏全局语义的特征决定了基于RNN的模型容易受到单词歧义的影响。 在这项工作中,我们尝试通过引入具有全局语义的基于词典的图神经网络来缓解此问题,在该网络中,词典知识用于连接字符以捕获局部组成,而全局中继节点可以捕获全局语句语义和长距离传递 依赖性。基于字符,潜在单词和整个句子语义之间基于多个图的交互,可以有效解决单词歧义。 在四个NER数据集上进行的实验表明,与其他基准模型相比,该模型取得了显着改进。
相关工作
基于字的表现要比基于词的表现好
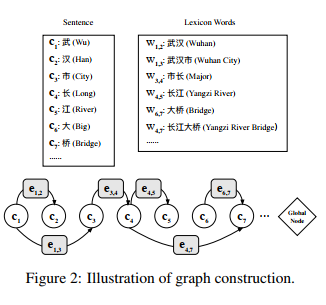
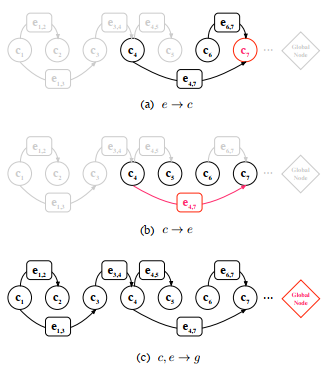
整个句子将转换为有向图,如图2所示,其中每个节点代表一个字符,单词中第一个和最后一个字符之间的连接可以视为边缘。 第i个节点的状态表示文本序列中第i个token的特征。 每个边的状态代表相应的潜在单词的特征。 global node用作虚拟集线器,从所有节点和边缘收集信息,然后利用全局信息来帮助节点消除歧义。
词典中与字符子序列匹配的潜在单词可以表示为$ w_ {b,e} = $ $ c_ {b},c_ {b + 1}, ldots,c_ {e-1},c_ {e} ,(,首字母和后字母的索引分别为) b (和) e (。 在这项工作中,我们建议使用有向图) mathcal {G} =( mathcal {V}, mathcal {E})(来建模句子,其中每个字符) c_ {i} in mathcal {V} (是图节点,) mathcal {E} (是边集。 一旦字符子序列与潜在单词) w_ {b,e},(匹配,我们就从起始字符) c_ {b} (指向一个边) e_ {b,e} in $ $ mathcal {E} $ 到结束字符$ c_ {e} $。
为了捕获全局信息,我们添加了一个全局中继节点来连接每个字符节点和单词边缘。 对于具有n个字符节点和m个边的图形,存在n + m个全局连接,将每个节点和边链接到共享中继节点。 通过全局连接,每两个不相邻的节点都是两跳邻居,并且通过两步更新来接收非本地信息。
什么是转置图

我们对四个中文NER数据集进行了实验。 (1)OntoNotes 4.0(Weischedel等,2011):OntoNotes是新闻领域中的一种手动注释的多语言语料库,包含各种文本注释,包括中文命名的实体标签。 可以使用黄金标准的细分。 我们仅使用中文文档(约1万6千个句子),并以与Che等人相同的方式处理数据。 (2013)。 (2)MSRA(Levow,2006年):MSRA还是新闻领域中的数据集,包含三种类型的命名实体:LOC,PER和ORG。 训练集中提供中文分词,但测试集中不提供。 (3)微博NER(Peng和Dredze,2015年):它包含从社交媒体新浪微博2提取的带注释的NER消息。 语料库包含命名实体和名义提及的PER,ORG,GPE和LOC。 (4)简历NER(Zhang and Yang,2018):它由从新浪财经3收集的简历组成,并以8种命名实体进行注释。 微博和简历数据集均不包含黄金标准的中文细分。 表1详细列出了上述数据集的统计信息