这里有一篇写的不错的:http://www.jianshu.com/p/1840035cb510
自己的“格式化”后的内容备忘下:
我们总在说c10k的问题, 也做了不少优化, 然后优化总是不够的。
其中的一个瓶颈就是一些耗时的操作(网络请求/文件操作--含耗时的数据库操作)。
如果我们不关心他们的返回值,则可以将其做成异步任务,保证执行成功即可。
开始阐述之前约定一些概念:
1. web请求处理进程(简称:消息生产者,记做P), 这是我们c10k问题注意的焦点
2. 消息的处理者(简称:消费者,记做C), 在成功“男人”后面默默无闻工作的“女人”
3. 消息存放的地方(简称: 消息队列, 记做Q)
4. 消息/任务, 记做T
基本处理过程:
1. P将T保存到Q
2. C从Q中取出一个T实例, 处理, 若处理失败则将T示例退回到Q(务必保证T得到成功处理)。
最简单的实现方案:
redis 消息队列(利用redis list类型)的lpush/rpop(brpop)来处理。python代码如下:
TaskServer.py
# -*- coding:utf-8 -*-
import traceback
import simplejson
import redis
import uuid
from functools import wraps
class TaskExecutor(object):
def __init__(self, task_name , *args, **kwargs):
self.queue = redis.StrictRedis()#host='localhost', port=6378, db=0, password='xxx_tasks')
self.task_name = task_name
def _publish_task(self, task_id , func, *args, **kwargs):
self.queue.lpush(self.task_name,
simplejson.dumps({'id':task_id, 'func':func, 'args':args, 'kwargs':kwargs})
)
def task(self, func):#decorator
setattr(func,'delay',lambda *args, **kwargs:self._publish_task(uuid.uuid4().hex, func.__name__, *args, **kwargs))
@wraps(func)
def _w(*args, **kwargs):
return func(*args, **kwargs)
return _w
def run(self):
print 'waiting for tasks...'
while True:
if self.queue.llen(self.task_name):
msg_data = simplejson.loads( self.queue.rpop(self.task_name))#这里可以用StrictRedis实例的brpop改善,去掉llen轮询。
print 'handling task(id:{0})...'.format(msg_data['id'])
try:
if msg_data.get('func',None):
func = eval(msg_data.get('func'))
if callable(func):
#print msg_data['args'], msg_data['kwargs']
ret = func(*msg_data['args'], **msg_data['kwargs'])
msg_data.update({'result':ret})
self.queue.lpush(self.task_name+'.response.success', simplejson.dumps(msg_data) )
except:
msg_data.update({'failed_times':msg_data.get('failed_times',0)+1, 'failed_reason':traceback.format_exc()})
if msg_data.get('failed_times',0)<10:#最多失败10次,避免死循环
self.queue.rpush(self.task_name,simplejson.dumps(msg_data))
else:
self.queue.lpush(self.task_name+'.response.failure', simplejson.dumps(msg_data) )
print traceback.format_exc()
PingTask = TaskExecutor('PingTask')
@PingTask.task
def ping_url(url):
import os
os.system('ping -c 2 '+url)
if __name__=='__main__':
PingTask.run()
运行服务:python TaskServer.py
ps:
1. TaskExecutor类是一个轻量级的celery.Celery实现。提供了 task修饰器。对被修饰的函数添加delay 方法(将原任务方法名/参数保存到redis的list中--FIFO--实际上celery也是类似的处理)
2. 客户端只要定义自己的TaskExecutor实例以及用此实例的task修饰对应的任务处理函数func。并在代码中待用 func.delay(...)实现异步调用(为了保证成功,最多调用10次); 成功的记录会保存在 redis的 "任务名.response.success" 队列中, 超过10次仍然失败的保存在 “任务名.response.failure"队列中。
3. 待改进的地方是很多的, 比如多线程, 负载均衡。(尚未阅读celery源码)
TaskClient.py
# -*- coding:utf-8 -*- import sys sys.path.append('./') from my_tasks import ping_url ping_url.delay('www.baidu.com')
ps: 客户端和服务器文件在统一linux目录下。
celery
试验证明, celery目测大体上跟上面的“基本处理过程”基本一致。即:
P将T保存在Q中。
C从Q中取出T处理(保证成功--会不会死循环?执行一个注定失败的任务--就没有验证了)。
celery的运用比较简单:
1.安装celery
2.编写需要异步执行的任务函数,并用celery实例的task修饰器修饰
3.调用异步任务时, 用函数名.delay(参数)形式调用为异步调用。 函数名(参数)方式为同步调用。
4.执行celery监听服务
demo 这里有:http://www.jianshu.com/p/1840035cb510。 再来一个极简的:
tasks.py
# -*- coding:utf-8 -*- from celery import Celery brokers = 'redis://127.0.0.1:6379/5' backend = 'redis://127.0.0.1:6379/6' import time app = Celery('tasks', backend=backend, broker=brokers) @app.task def add(x,y): time.sleep(10) return x+y
运行celery监听服务:celery -A tasks worker -l error
顺便附上测试代码:tasks_test.py(跟tasks.py同一路径,linux环境)
# -*- coding:utf-8 -*- import sys sys.path.append('./') def test(): from tasks import add for i in range(1000): add.delay(i,i+1) if __name__=='__main__': test()
执行之 : python tasks_test.py
(可以1秒内跑完, 证明的确异步处理了)
顺便查看了下进程,发现celery自动开了一个主进程, 与cpu核数相同的子线程。看了下官方文档,有web监控用的插件(flower)。
安装: sudo pip install flower
运行之(跟tasks.py先同目录): celery -A tasks flower --port=5555
效果图如下(木有发现失败任务--"Failed tasks"---很遗憾):
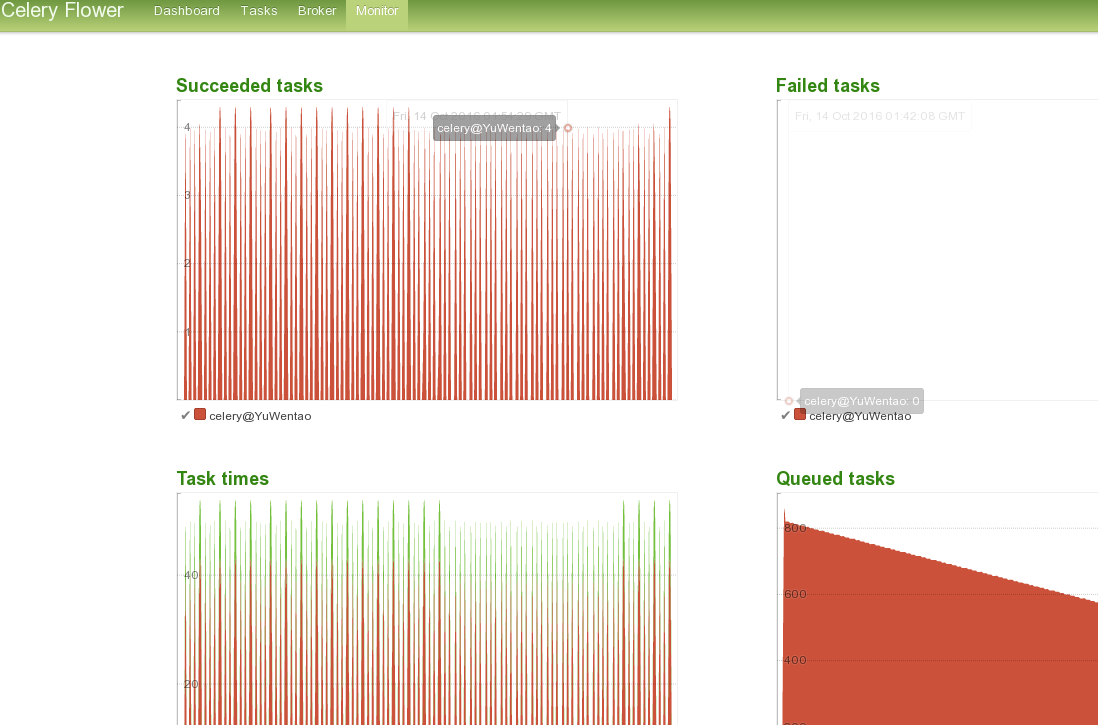
flower的基本原理推测是直接查询Q, 并基于结果输出图表等。
ref: https://abhishek-tiwari.com/post/amqp-rabbitmq-and-celery-a-visual-guide-for-dummies
转载请注明来源:http://www.cnblogs.com/Tommy-Yu/p/5955294.html
谢谢!