新地址体验:http://www.zhouhong.icu/post/139
一、Logstash介绍
Logstash是elastic技术栈中的一个技术。它是一个数据采集引擎,可以从数据库采集数据到es中。我们可以通过设置自增id主键或者时间来控制数据的自动同步,这个id或者时间就是用于给logstash进行识别的
id:假设现在有1000条数据,Logstatsh识别后会进行一次同步,同步完会记录这个id为1000,以后数据库新增数据,那么id会一直累加,Logstatsh会有定时任务,发现有id大于1000了,则增量加入到es中
时间:同理,一开始同步1000条数据,每条数据都有一个字段,为time,初次同步完毕后,记录这个time,下次同步的时候进行时间比对,如果有超过这个时间的,那么就可以做同步,这里可以同步新增数据,或者修改元数据,因为同一条数据的时间更改会被识别,而id则不会。
二、安装Logstash
Elasticsearch安装,集群搭建请移步:
ES安装:http://www.zhouhong.icu/post/128
ES集群搭建、与SpringBoot整合:http://www.zhouhong.icu/post/138
准备:
- 数据库:db_mblog
- 表:mto_post
- Logstatsh
- mysql-connector-java-8.0.11.jar
数据准备:
CREATE TABLE `mto_post` ( `id` DOUBLE , `author_id` DOUBLE , `channel_id` DOUBLE , `comments` DOUBLE , `created` DATETIME , `favors` DOUBLE , `featured` DOUBLE , `status` DOUBLE , `summary` VARCHAR (420), `tags` VARCHAR (192), `thumbnail` VARCHAR (384), `title` VARCHAR (192), `views` DOUBLE , `weight` DOUBLE ); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('35','1','1','0','2020-02-11 11:17:24','0','0','0','如果有来生,要做一棵树, 站成永恒。没有悲欢的姿势, 一半在尘土里安详, 一半在风里飞扬; 一半洒落荫凉, 一半沐浴阳光。 非常沉默、非常骄傲。 从不依靠、从不寻找。 如果有来生,要化成一阵风, 一瞬间也能成为永恒。 没有善感的情怀, 没有多情的...','','//qiniusave.zhouhong.icu/3NSPTP433IDHNH7G9FLEL1ANU3.jpg','如果有来生---三毛','110','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('37','1','1','0','2020-02-13 13:51:34','2','0','0','从明天起,做一个幸福的人 喂马、劈柴,周游世界 从明天起,关心粮食和蔬菜 我有一所房子,面朝大海,春暖花开; 从明天起,和每一个亲人通信 告诉他们我的幸福 那幸福的闪电告诉我的 我将告诉每一个人; 给每一条河每一座山取一个温暖的名字 陌生人,我也...','夏日','//qiniusave.zhouhong.icu/2VPB7PA4NFLG1MP764H1NRMILN.jpg','面朝大海,春暖花开','64','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('38','1','1','0','2020-02-21 13:55:27','1','0','0','人生有一首诗, 当我们拥有它的时候, 往往并没有读懂它; 而当我们能够读懂它的时候, 它却早已远去, 这首诗的名字就叫 青春。 青春是那么美好, 在这段不可复制的旅途当中, 我们拥有独一无二的记忆, 不管它是迷茫的、孤独的、不安的, 还是欢腾的、...','时光','//qiniusave.zhouhong.icu/1VHFIK2DVSGUCJNPDL707NEBIN.jpg','青春','95','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('39','1','5','0','2021-01-15 14:45:42','0','1','0','>欢迎访问我的博客园:Tom-shushu的博客园 56、关于缓存穿透,缓存击穿,缓存雪崩,热点数据失效问题的解决方案 55、CENTOS7下用FASTDFS搭建图片服务器 54、JAVA实现PDF和EXCEL生成和数据动态插入以及导出 5...','博客园搬家','//qiniusave.zhouhong.icu/GJEPCOMLNME5EVODJVRQV1EL.jpg','我的博客园博文搬新家啦^_^','224','3'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('40','1','1','1','2020-03-21 20:59:27','0','0','0','我有时喜欢一个人行走。闲暇之余,能够不做闲人,却又不能够没有闲情。这样一来,我有时就喜欢一个人行走。在这个喧嚣的世界里,唯有一个人行走才没有羁绊束缚;唯有一个人行走才能感觉到自己真实的心跳;唯有一个人行走才能放纵属于自己的那份情绪。在一个人中享受...','微笑','//qiniusave.zhouhong.icu/QL7IAJGT9I3MIC7QNAEVI80FP.jpg','独处--领悟','207','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('43','1','5','0','2020-04-19 02:46:56','0','1','0','关于缓存穿透,缓存击穿,缓存雪崩,热点数据失效问题的解决方案 1.我们使用缓存时的业务流程大概为: 当我们查询一条数据时,先去查询缓存,如果缓存有就直接返回,如果没有就去查询数据库,然后返回。这种情况下就可能出现下面的一些现象。 2.缓存穿透 ...','Redis 缓存,博客园迁移','//qiniusave.zhouhong.icu/13I57KJ8PRII7RIQIP60F5RTFA.jpg','关于缓存穿透,缓存击穿,缓存雪崩,热点数据失效问题的解决方案','30','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('44','1','4','0','2020-04-24 15:06:24','0','0','0','LeetCode传送门:判断一个整数是否是回文数 package com.zhouhong.LeetCode; import java.util.Stack; public class LeetCode0009 { //判断一个整数是否是回文数。...','LeetCode','//qiniusave.zhouhong.icu/3P1G4QARU5FC6CD80AB0J4QCPF.jpg','LeetCode0009:判断一个整数是否是回文数','5','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('45','1','4','0','2020-05-07 21:10:47','0','0','0','传送门:LeetCode26原地删除重复出现的排序元素 package com.zhouhong.LeetCode; //给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。 // 不要使用额外的...','双指针,LeetCode','//qiniusave.zhouhong.icu/3F64LCIEC353EFOU9RH35S10C1.jpg','LeetCode0026:原地删除重复出现的排序元素','7','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('46','1','4','0','2020-06-15 10:15:04','0','0','0','传送门:LeetCode27原地移除目标值 package com.zhouhong.LeetCode; //给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 // 不要使用额外...','LeetCode,双指针,数组','//qiniusave.zhouhong.icu/3LLSKK2ETVUCHKFMML1HMEJ3H5.jpg','LeetCode0027:原地移除目标值','5','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('47','1','4','0','2020-09-19 17:31:01','0','0','0','传送门:LeetCode0034找出排序数组中给定值的开始结束位置 package com.zhouhong.LeetCode; import java.util.ArrayList; /** *给定一个按照升序排列的整数数组 nums,和一个目...','LeetCode,数组','//qiniusave.zhouhong.icu/3U38M4FL08SO1SBFU7282F15AH.jpg','LeetCode0034:找出排序数组中给定值的开始结束位置','9','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('48','1','4','0','2020-10-08 12:36:30','0','0','0','传送门:LeetCode0035搜索插入位置 package com.zhouhong.LeetCode; /** * 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。 * 如果目标值不存在于数组中,返回它将会被按顺序插入的位置。...','数组,二分搜索,LeetCode','//qiniusave.zhouhong.icu/4F2BNHQL652GQVN6EU6EAKUCU.jpg','LeetCode0035:搜索插入位置','8','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('49','1','4','0','2020-10-11 18:41:03','0','0','0','传送门:LeetCode0075颜色分类排序 package com.zhouhong.LeetCode; import java.util.Arrays; //给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜...','快排,LeetCode','//qiniusave.zhouhong.icu/1CRLSEE4KFD9RT3SMRBBI7RDTT.jpg','LeetCode0075:颜色分类排序','7','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('50','1','4','0','2020-10-15 15:47:24','0','0','0','传送门:LeetCode0136只出现一次的元素 package com.zhouhong.LeetCode; import java.util.Arrays; //给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那...','LeetCode,双指针','//qiniusave.zhouhong.icu/2GTM1BRNT8EARTTVKAAOJ4KOJM.jpg','LeetCode0136:只出现一次的元素','12','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('51','1','4','0','2020-10-20 09:57:02','0','0','0','传送门:LeetCode0164最大间距,排序后两两数字直接最大的差值 package com.zhouhong.LeetCode; import java.util.Arrays; //给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的...','LeetCode,双指针','//qiniusave.zhouhong.icu/G7MRRA45B1G2BDEE422V93PMH.jpg','LeetCode0164:最大间距,排序后两两数字直接最大的差值','13','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('52','1','4','0','2020-11-07 15:59:40','0','0','0','传送门:LeetCode0206翻转一个单链表 package com.zhouhong.LeetCode; public class LeetCode0206 { public class ListNode { int val; ListNod...','LeetCode,链表','//qiniusave.zhouhong.icu/25D5QTG1CPRRAO1MTGH5CAIB08.jpg','LeetCode0206:翻转一个单链表','13','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('53','1','4','0','2020-11-19 16:02:28','0','0','0','传送门:LeetCode0242有效的字母异位词 package com.zhouhong.LeetCode; import java.util.Arrays; //给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。...','LeetCode','//qiniusave.zhouhong.icu/1ICO3UF95GO0C91NVNOI76E5E5.jpg','LeetCode0242:有效的字母异位词','21','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('66','1','4','0','2020-12-01 11:28:56','0','0','0','传送门:LeetCode283移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 必须在原数组上操作,不能拷贝额外的数组。尽量减少操作次数。 一、双指针解决 /** * 分为两种情况:...','LeetCode,双指针','//qiniusave.zhouhong.icu/2VPB7PA4NFLG1MP764H1NRMILN.jpg','LeetCode0283:移动零','19','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('67','1','4','1','2020-12-06 19:32:54','0','0','0','传送门:LeetCode0287寻找重复的数 给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。 说明:// 不能更改原数组(...','LeetCode,双指针','//qiniusave.zhouhong.icu/2HSPJJEUOQP9DC4AGG7D92CJ09.jpg','LeetCode0287:寻找重复的数','34','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('68','1','4','0','2020-12-10 20:37:29','0','0','0','数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0 /** * 排序后,次数大于一半,...','字符串,算法','//qiniusave.zhouhong.icu/3L7DV6AKJ0SEJ5D4QQ408C78LE.jpg','找出次数超过数组一半长度的数','32','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('69','1','4','0','2020-12-28 21:42:13','0','0','0','方法一、循环实现 static void method1(){ Scanner in = new Scanner(System.in); String str = in.nextLine(); char[] arr = str.toCharAr...','算法','//qiniusave.zhouhong.icu/TO6E9PCMLB92EL0AR1HQJ5GA8.jpg','5种方法实现字符串翻转','27','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('70','1','8','0','2021-01-11 16:44:46','1','0','0','package com.zhouhong.util; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; imp...','工具','//qiniusave.zhouhong.icu/2GTM1BRNT8EARTTVKAAOJ4KOJM.jpg','SQL转Java工具','25','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('71','1','4','0','2021-01-13 00:18:37','0','0','0','传送门:LeetCode0455分发饼干 一、题目描述 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼...','贪心算法,LeetCode','//qiniusave.zhouhong.icu/3MBBFME404DS6EMAVMAA4LHAPK.jpg','贪心算法--LeetCode0455分发饼干','17','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('72','1','4','0','2021-01-19 01:53:11','0','0','0','LeetCode0509斐波那契数列 一、题目 斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的...','动态规划,LeetCode,斐波那契','//qiniusave.zhouhong.icu/1ES930G0D90TIIDB7LLGGDFGG.jpg','动态规划--LeetCode0509斐波那契数列,不同方法耗时比较','61','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('74','14','8','0','2021-01-21 23:45:20','0','0','0','1.空格:默认匹配、普通匹配 location / { root /home; } 2.= :精确匹配(表示匹配到 /home/resources/img/face.png 这张图片) location = /resourc...','Nginx','//qiniusave.zhouhong.icu/2U5F2D30E1BGD8GTVVI830BDF7.jpg','Nginx配置文件nginx.conf中location的匹配原则','19','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('79','1','8','0','2021-01-23 12:50:08','0','0','0','跨域问题的本质: 两个站点域名不一样,就会出现跨域问题。 所以跨域问题的本质是域名不同 一、跨域问题解决 1、CORS跨域资源共享---Cross-origin resource sharing 它允许浏览器向跨源服务器,发出XMLHttpReq...','跨域,Nginx,架构','//qiniusave.zhouhong.icu/2R5POVKLSG2JTH0B3LVVR337QP.jpg','Nginx、SprongBoot Cors解决跨域问题与Nginx中静态资源防盗链配置','10','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('80','1','8','0','2021-01-23 13:21:46','0','0','0','一、Linux下Nginx的安装 1.去官网 http://nginx.org/download/下载对应的Nginx安装包,推荐使用稳定版本。 2.上传Nginx到Linux服务器。 3.安装依赖环境 (1)安装gcc环境 yum inst...','Nginx,架构','//qiniusave.zhouhong.icu/3J6TGJ2KOSSEDFCEJHR056M91E.jpg','Nginx安装/进程模型/事件处理机制/详细配置/定时切割日志','19','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('82','1','4','0','2021-01-24 01:08:41','0','0','0','传送门:LeetCode0070爬楼梯问题 题目: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 跟斐波那契数列一样 解法一、使用动态规划方法解决 cl...','斐波那契,LeetCode,动态规划','//qiniusave.zhouhong.icu/2NMPPF6J9ENNRG7IDS8O1HU9Q7.jpg','动态规划--LeetCode0070爬楼梯问题','14','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('83','1','8','0','2021-01-24 11:22:05','0','0','0','一、Nginx模块化体系结构 event module:事件模块 phase handler:处理客户端请求和内容相应 output filter:输出过滤,例如gzip,upstream 反向代理模块,会把请求打到真正的服务器去处理 load ...','Nginx,架构,负载均衡','//qiniusave.zhouhong.icu/3894VA2SDV5G84FUN95A4FEADG.jpg','Nginx集群、负载均衡解析','14','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('84','1','8','0','2021-01-24 13:26:04','0','0','0','一、四层负载均衡 四层负载均衡 : 能够为企业网络设备或者服务器带来更好的服务,提高吞吐量、提升并发性能、增强服务器的处理能力,并且可以提高服务器计算能力,使得我们的网络设备更加灵活。 负载均衡是当有大量的并发请求来到服务器的时...','架构,Nginx','//qiniusave.zhouhong.icu/1H8HTTRSR9J46EN8BDDOGU353S.jpg','四层、七层和DNS负载均衡','22','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('85','1','8','0','2021-01-24 13:55:57','0','0','0','一、利用Nginx构建三台TomCat集群 我们现在有四台机器,一台用来做Nginx负载用,另外三台为正常的集群节点。 配置反向代理: 配置一个server虚拟主机,用来监听端口,用来接收http请求 location配置proxy_pass ...','Nginx,负载均衡','//qiniusave.zhouhong.icu/FHLEQ8SEBVO0PB26OVO3P7PQT.jpg','Nginx集群构建以及负载均衡策略---轮询、加权轮询','19','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('86','1','8','0','2021-01-24 14:53:54','0','0','0','一、max_conns max_conns 用于限制一台服务器的最大连接数,默认值是0表示无限制,每个工作进程都能生效,限流,老版本要商业版才能使用; # worker进程设置1个,便于测试观察成功的连接数 worker_processes 1;...','Nginx,架构','//qiniusave.zhouhong.icu/1MGQUSCKEGCA91VF9AOH26MNUR.jpg','Nginx中upstream指令参数解析和keepalive提高吞吐量','28','0'); INSERT INTO `mto_post` (`id`, `author_id`, `channel_id`, `comments`, `created`, `favors`, `featured`, `status`, `summary`, `tags`, `thumbnail`, `title`, `views`, `weight`) VALUES('98','1','8','0','2021-01-24 21:45:33','0','0','0','一、今天登录我的网站,突然发现报了下面的一个错误: 我的第一反应是:超时了应该是Nginx代理没有设置超时时间,默认的超时时间估计太小了,然后就按照正常的方式用Xshell连接服务器,应该是网络或者是其他的原因吧,好巧不巧的我的Xshell连接...','问题','//qiniusave.zhouhong.icu/2D98FKFVS216MBOIS5TS9CTR7R.jpg','Nginx报504 gateway timeout错误的解决方法','33','0');
官方链接:
https://www.elastic.co/cn/downloads/past-releases
注:使用Logstatsh的版本号与elasticsearch版本号需要保持一致
本插件用于同步,es6.x起自带,这个是集成在了 logstash中的。所以直接配置同步数据库的配置文件即可。
-
解压
tar -zxvf logstash-6.4.3.tar.gz
-
将解压文件夹移到 /usr/local 下面
mv logstash-6.4.3 /usr/local
-
进入目录新建文件夹
cd /usr/local/logstash-6.4.3/ mkdir sync
-
进入 sync 目录新建 logstash-db-sync.conf 和 my_blog.sql 两个文件
-
logstash-db-sync.conf 内容如下
-
-
input { jdbc { # 设置 MySql/MariaDB 数据库url以及数据库名称 jdbc_connection_string => "jdbc:mysql://192.168.2.158:3306/db_mblog?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=GMT" # 用户名和密码 jdbc_user => "root" jdbc_password => "root" # 数据库驱动所在位置,可以是绝对路径或者相对路径(在maven 仓库里面可以得到) jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-8.0.11.jar" # 驱动类名 jdbc_driver_class => "com.mysql.cj.jdbc.Driver" # 开启分页 jdbc_paging_enabled => "true" # 分页每页数量,可以自定义 jdbc_page_size => "10000" # 执行的sql文件路径 statement_filepath => "/usr/local/logstash-6.4.3/sync/my_blog.sql" # 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务 schedule => "* * * * *" # 索引类型 type => "_doc" # 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件 use_column_value => true # 记录上一次追踪的结果值 last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/blog_track_time" # 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间 tracking_column => "updated_time" # tracking_column 对应字段的类型 tracking_column_type => "timestamp" # 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录 clean_run => false # 数据库字段名称大写转小写 lowercase_column_names => false } } output { elasticsearch { # es地址 hosts => ["192.168.2.120:9200"] # 同步的索引名 index => "my_blog" # 设置_docID和数据相同 document_id => "%{id}" } # 日志输出 stdout { codec => json_lines } }
-
my_blog.sql 文件内容如下
-
SELECT a.id AS id, a.comments AS comments, a.created AS created, a.favors AS favors, a.featured AS featured, a.status AS mstatus, a.summary AS summary, a.tags AS tags, a.thumbnail AS thumbnail, a.title AS title, a.views AS views, a.weight AS weight FROM mto_post a WHERE a.created >= :sql_last_value
-
-
进入 bin 目录启动
-
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
-
-
查看
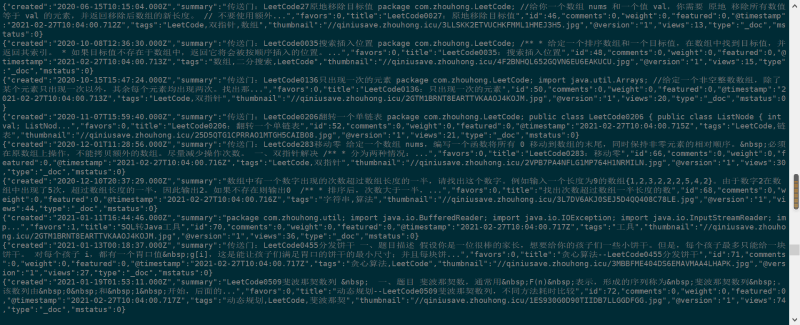
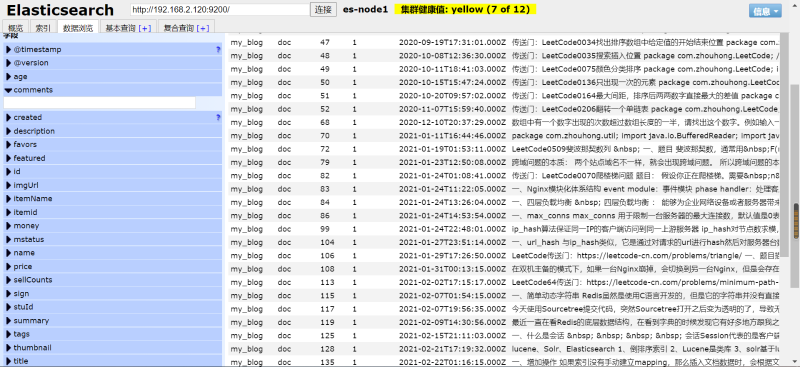
可见数据已经成功添加至ES中。
-
自定义模板配置ik中文分词器
-
GET http://192.168.2.120:9200/_template/logstash 获取到 logstash 修改相关内容,在 /usr/local/logstash-6.4.3/sync 下面新建 logstash-ik.json 将获取到的内容修改后复制进去
-
logstash-ik.json内容如下:
-
{ "order": 0, "version": 1, "index_patterns": ["*"], "settings": { "index": { "refresh_interval": "5s" } }, "mappings": { "_default_": { "dynamic_templates": [ { "message_field": { "path_match": "message", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false } } }, { "string_fields": { "match": "*", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } ], "properties": { "@timestamp": { "type": "date" }, "@version": { "type": "keyword" }, "geoip": { "dynamic": true, "properties": { "ip": { "type": "ip" }, "location": { "type": "geo_point" }, "latitude": { "type": "half_float" }, "longitude": { "type": "half_float" } } } } } }, "aliases": {} }
-
将 logstash-ik.json 引入配置文件 logstash-db-sync.conf output模块中做如下修改: -
output { elasticsearch { # es地址 hosts => ["192.168.2.120:9200"] # 同步的索引名 index => "my_blog" # 设置_docID和数据相同 document_id => "%{id}" # 定义模板名称 template_name => "myik" # 模板所在位置 template => "/usr/local/logstash-6.4.3/sync/logstash-ik.json" # 重写模板 template_overwrite => true # 默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置为false manage_template => false } # 日志输出 stdout { codec => json_lines } }
-
启动
-
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
-