接第一部分

-
一种实现高动态范围的新方法,弥补了过去对于图像裁剪和量化带来的损失误差,利用简单的网络架构实现了很高的性能。并利用了色调映射品质因素(tone mapped image quality index TMQI)和自然图像品质评价因素(naturalness image quality evaluator NIQE)来进行了测评。(from 首都大学东京)
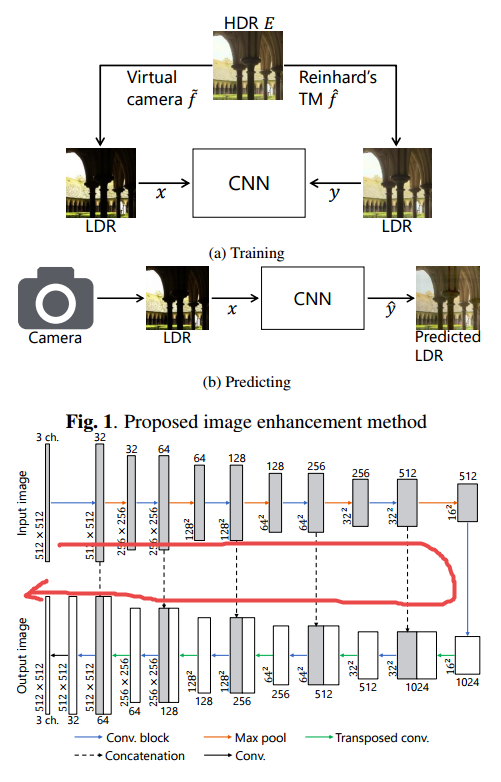
利用了基于Unet 的网络架构:
得到的结果如下所示:
code:https://github.com/ybsong00/DRHT
数据集中的虚拟相机来自于HDRCNN的第四部分第二段。对于代码, 项目
一些相关的方法:直方图均衡histogram equalization (HE), 对比累积直方图均值contrastaccumulated histogram equalization (CACHE) [2], 反射和光照同估计simultaneous reflectance and illumination estimation (SRIE) [4], and 深度呼唤HDR转换deep reciprocating HDR transformation 1 (DRHT) [8], where SRIE is a (视网膜皮层)Retinex-based method and DRHT is a CNN-based one.
相关数据集:EMPA HDR images dataset: http://empamedia.ethz.ch/hdrdatabase/index.php -
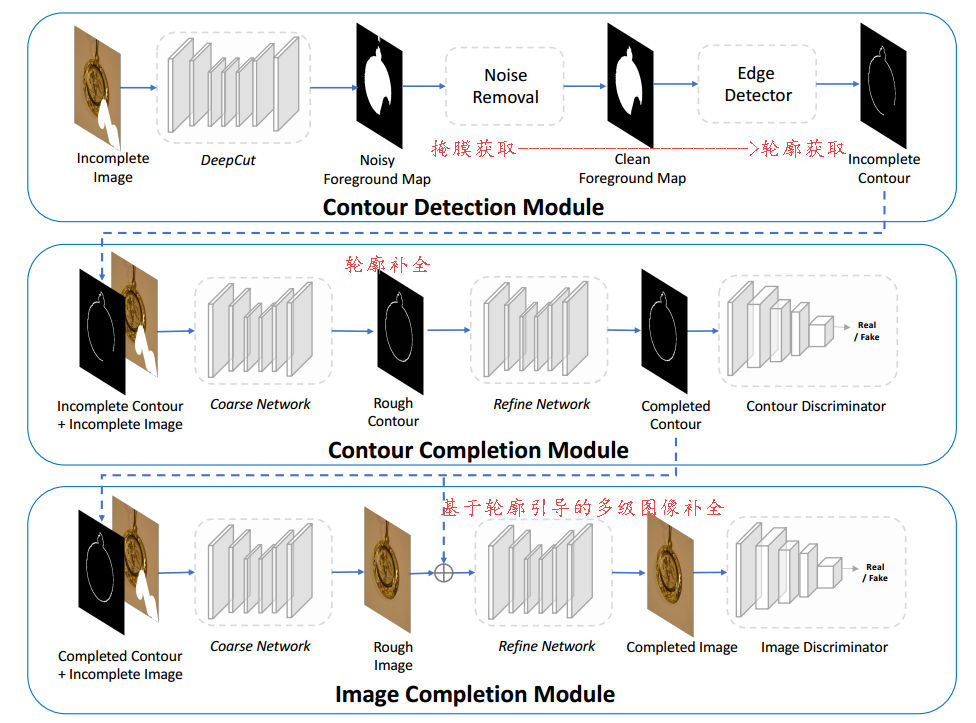
能够前景的图像补全方法,克服了缺失区域横跨前景背景的限制。首先预测前景的轮廓,随后利用这一轮廓引导图像补全的过程。这一过程使得网络可以分别预测结果和内容补全,轮廓补全后加上内容补全更好的提高了修补后图像的质量。(from 罗彻斯特大学 adobe)
网络的架构分为三个步骤,首先利用检测掩膜获取轮廓,随后对轮廓补全,最后在引导图像补全:
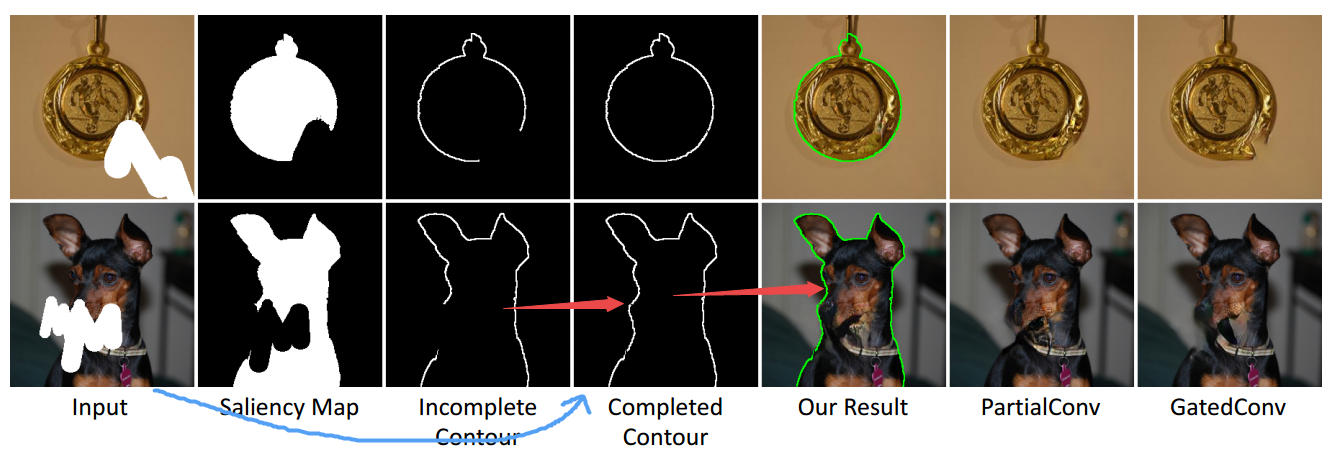
得到的一些结果:
前景轮廓引导的作用:
相关方法: GatedConv[26],PartialConv[16], ContextAttention[27], and Global&Local[12], Patch Match[5].GatedConv [26]
本文利用了显著性分割数据集MSRA-10K,annotated Flickr natural image dataset,利用边缘检测得到轮廓。
图像补全数据集:
利用掩膜的数据集:Places2 [28], Paris [22], or CelebFace [17]
带标记的数据集:BSD500 -
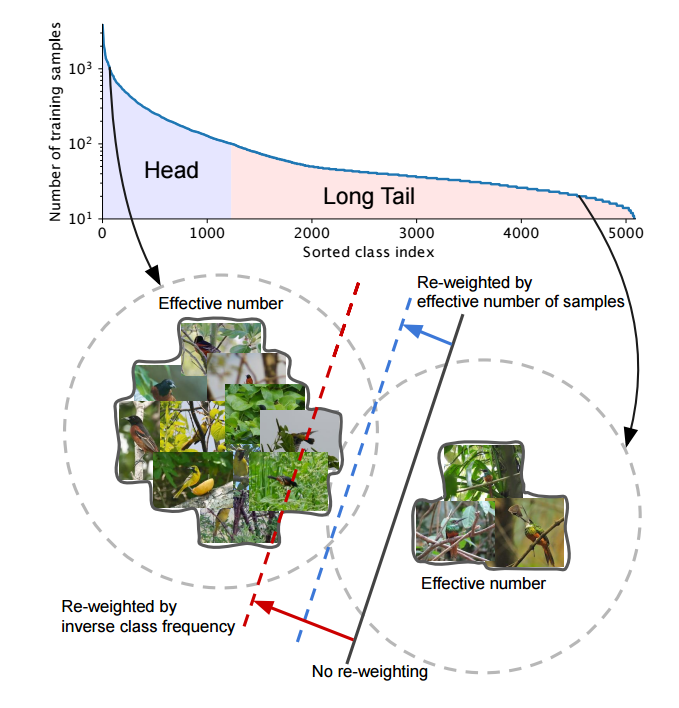
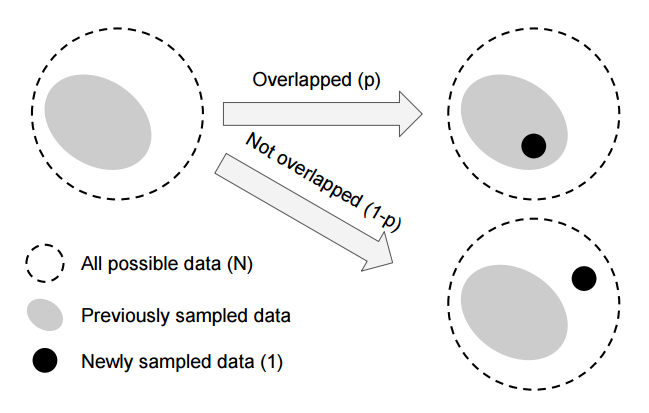
,为了处理数据集的长尾效应(类别数量不平衡),使用重采样和重赋权重的方法,随着采样数量的增加新数据带来的益处也会下降。本文引入一种新框架来评测数据重叠,利用小领域代替的单点度量。有效系数利用定义。基于此提出了更有效的采样策略。(from 康奈尔)


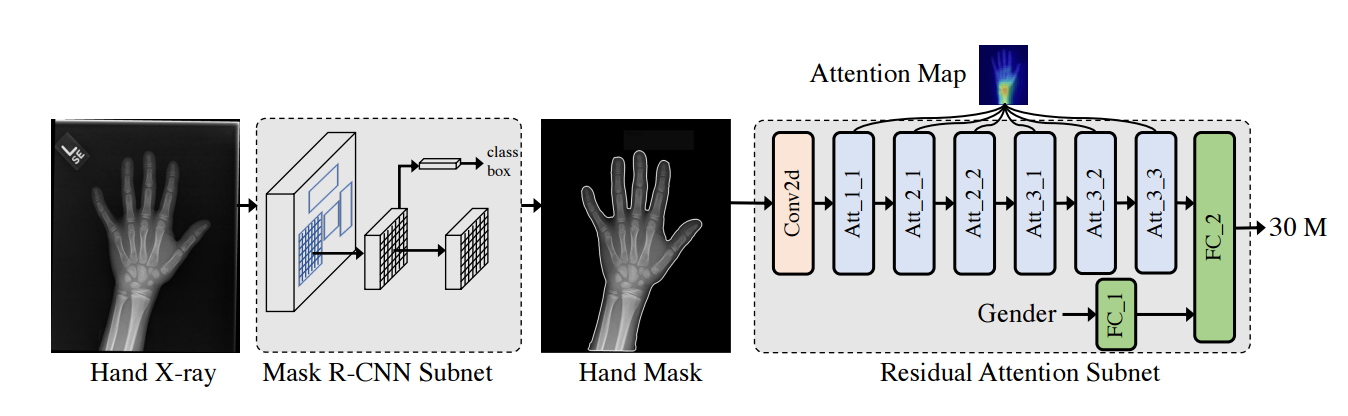
基于残差注意力的手部骨龄识别,基于maskRCNN和残差注意力的网络联合实现了7.38个月的预测误差(from 康奈尔)
数据集:RSNA pediatric bone age dataset
-
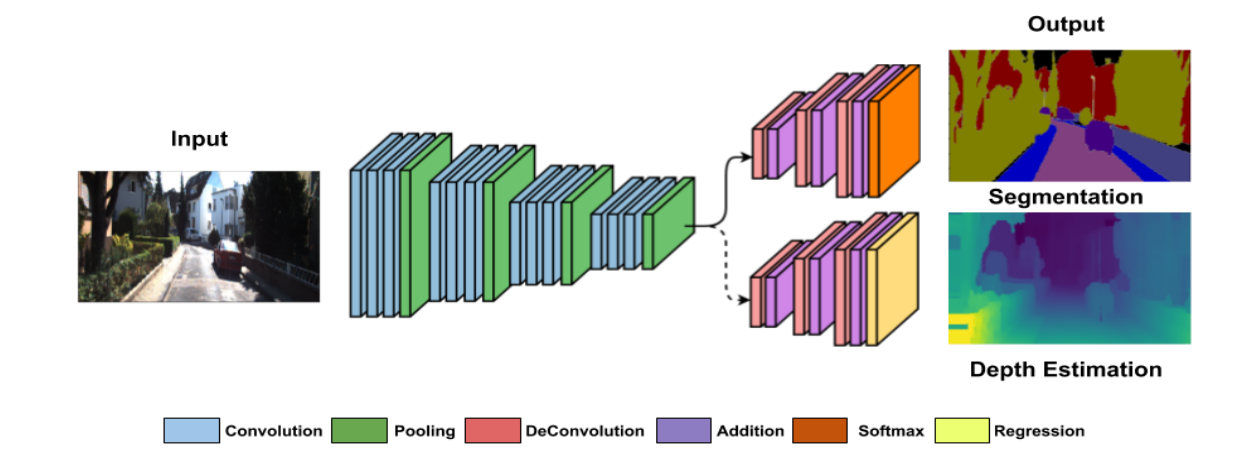
AuxNet基于辅助任务提高自动驾驶领域的语义分割性能,由于多任务学习可以提高每个任务的表现,所以研究人员引入了辅助任务来辅助语义分割任务。同时提出了自适应任务损失权重技术来解决多任务损失中的尺度问题。(from 法雷奥Valeo Troy)
数据集 KITTI, SYNTHIA合成 -
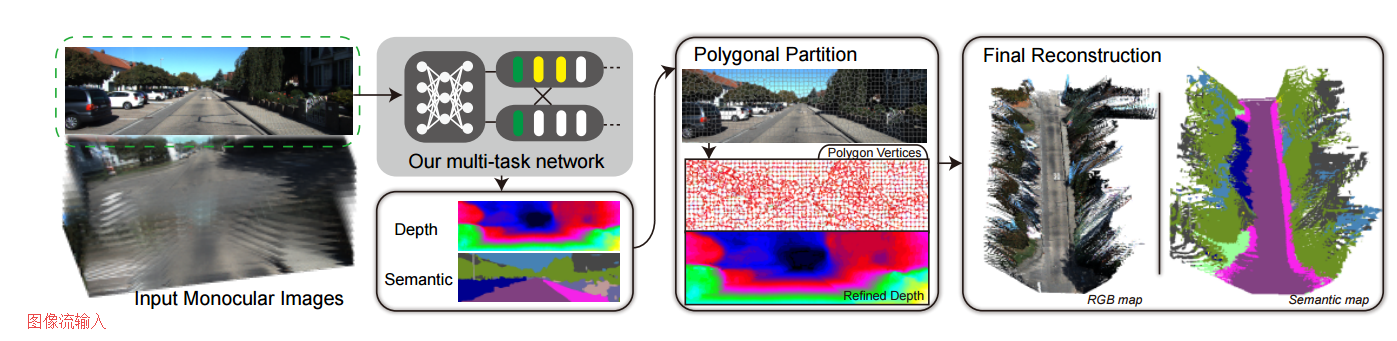
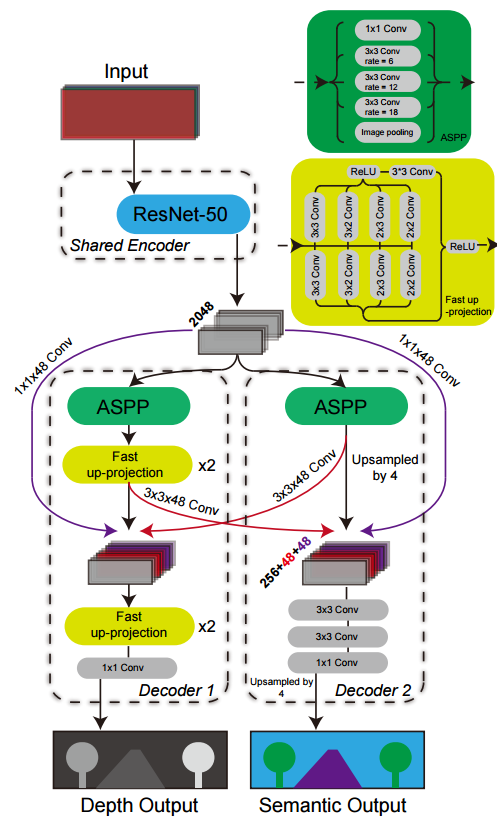
利用多任务网络实现单目语义地图构建,(from 中山大学)
其中获取深度图和语义图的网络架构如下:
数据集:Cityscape dataset -
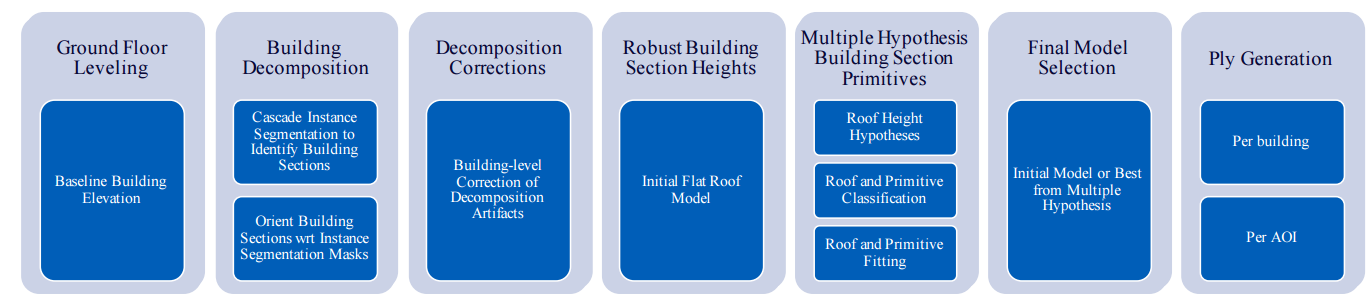
三维建筑建模、感知模拟和估计,对于三维数据在多边形网格模型下更紧凑的表示,并将合成数据用于训练从卫星图像到三维模型的过程。(from GE)
一些重建结果:
WorldView-3 satellite image dataset
相关工作,卫星影像到地图/建筑等:SpaceNet

src="https://player.vimeo.com/external/302241104.hd.mp4?s=d6ce1b077193a5cac8ac6f7db2c323a021da1515&profile_id=175&oauth2_token_id=57447761&tiny=0&auto=0">