这个问题萦绕在我心里好多天了, 现在有了一个不完美但也算不错的答案, calibre.
calibre的安装按照官网的download做就行了. 我用的是mac, 值得一提的是ebook-convert路径是/Applications/calibre.app/Contents/MacOS/, 可以添加在PATH中
如何学习写recipe?
- 这篇博客虽然由于隔了好多年, 内容有些地方不适用了, 具体来说是parse_index的格式, 但是大体还是可以学习一下. 命令行工具这个博客也讲了, 不赘述.
- github repo中有大量例子, 不过我读都没读.
- API
- 我写的几个recipe, 最基本用法.
recipe的一个例子讲解
下面我就结合我写的一个例子说说如果要构建一个recipe需要改些什么位置
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'rcore tutorial'.title() # 封面没有图片就会用这个字符串
description = ''
no_stylesheets = True # 与css相关, 见到的例子总是True, 不知意思
# cover_url = 'https://cmake.org/wp-content/uploads/2019/05/Cmake-logo-header.png' # 如果有图片, 设置这个, 可以是file:///本地文件
dic = dict(name="div", attrs={'itemprop': "articleBody"})
remove_tags_after = dic # 字典或者list, 表示在这个tag以后的都不会要, 这样就可以保留主体信息
remove_tags_before = dic # 同上
# remove_tags = [dict(name='footer')]
def parse_index(self):
# 此函数必须实现, 返回类型是, 一个列表, 每个列表元素代表一个章节, 每个章节是一个元组, 元组的成员是0. 本章标题字符串, 1. 一个列表, 元素是一个章的一个小节, 这个小节是一个字典
index_url = 'https://rcore-os.github.io/rCore-Tutorial-Book-v3/chapter0/index.html'
soup = self.index_to_soup(index_url) # index_to_soup是得到一个网页的beautifulsoup object
chapters = [] # 返回, 元素是(string,[字典])
for chapter in soup.find(name='div', attrs={ 'class': 'wy-menu'}).findAll(name='li', attrs={'class': 'toctree-l1'}):
chap_name = chapter.string
sections = [] # [字典]
tmp = 'index.html' if chapter.a['href'] == '#' else chapter.a['href']
chapter_index_url = 'https://rcore-os.github.io/rCore-Tutorial-Book-v3/chapter0/'+tmp
sub_soup = self.index_to_soup(chapter_index_url)
chapter_url_prefix = chapter_index_url.rsplit('index.html')[0]
try:
for section in sub_soup.find(name='div', attrs={ 'class': 'toctree-wrapper'}).findAll(name='li', attrs={'class': 'toctree-l1'}):
a = { 'title': section.a.string, 'url': chapter_url_prefix + section.a['href'], 'date':None, 'description':None, 'content':None }
sections.append(a)
chapters.append((chap_name, sections))
except:
# import pdb;pdb.set_trace()
pass
return chapters
需要改title, remove_tags_after, remove_tags_before, parse_index的实现.
关于parse_index怎么实现, 首先是看上面的例子, 再看看BeautifulSoup最简单的一些用法就可以了.
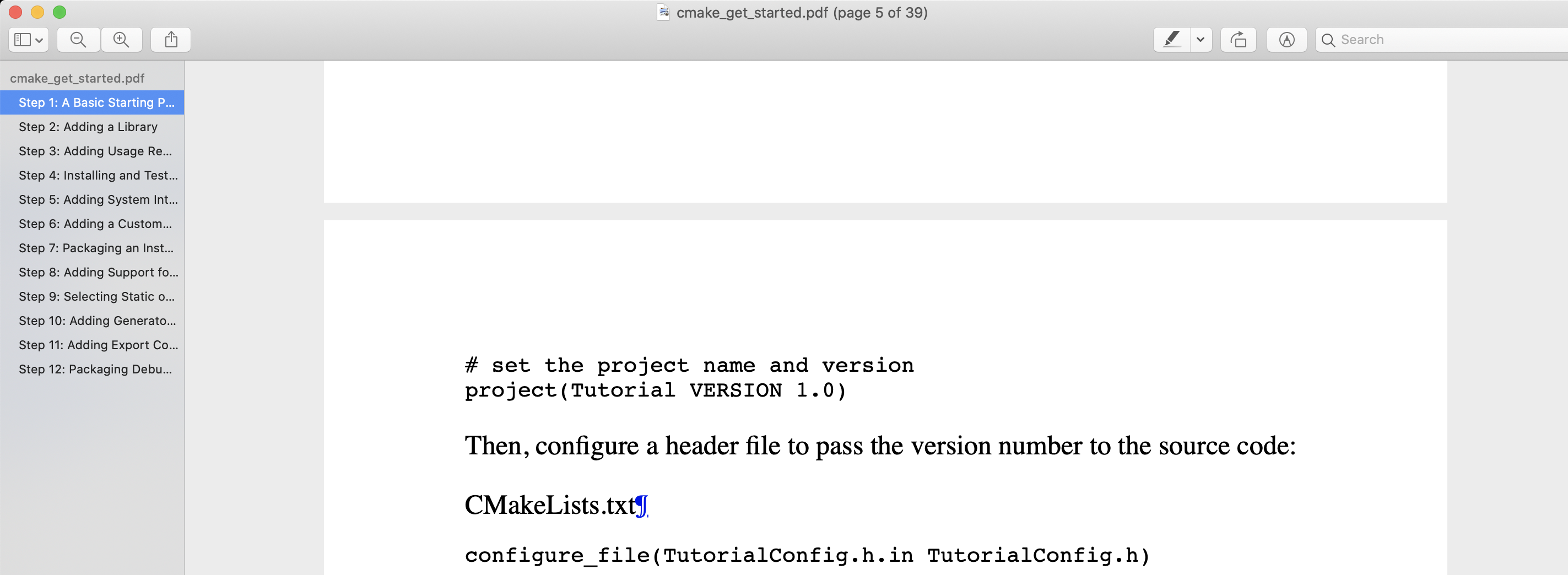
最后放点效果图:
这是cmake get started页制作的pdf的效果图.
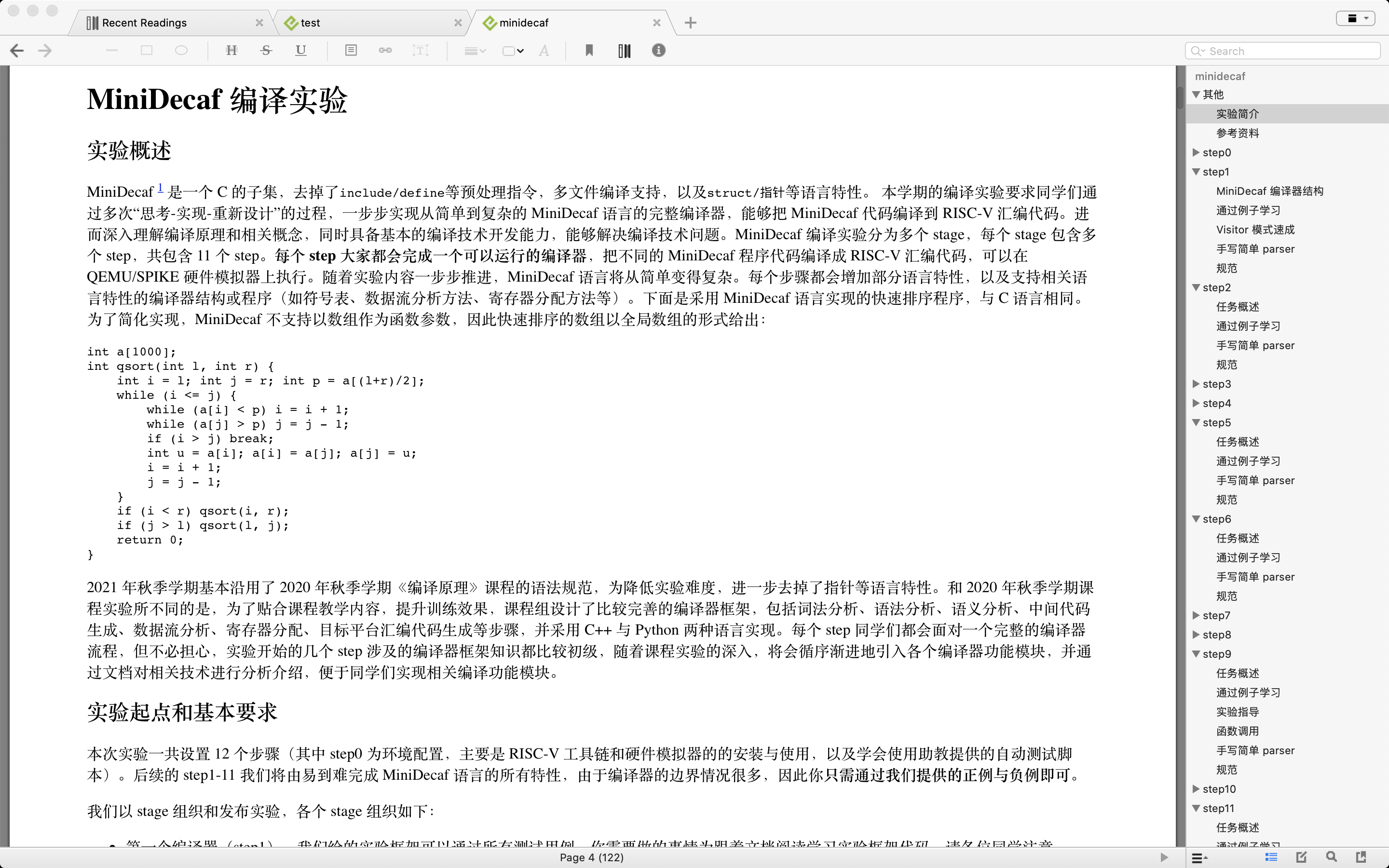
这是minidecaf制作的epub的效果图.
生成效果图的源代码在上面的github链接.