存储引擎是针对数据表所说的
MyISAM存储引擎:非聚集的,索引文件和数据是分离的
MYI文件和MYD文件
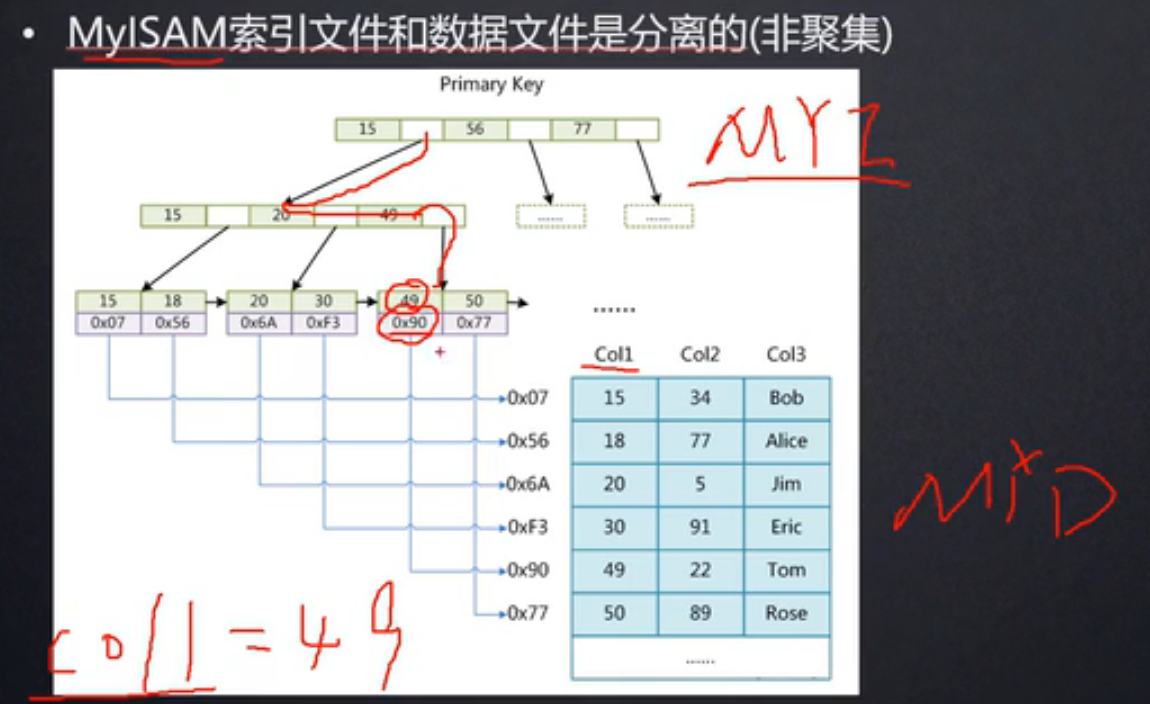
查找时,MYI查找行所在文件的磁盘文件地址--》定位到MYD文件中的某行元素
MYI文件找到索引,按照地址(第三层的data存放MYD文件标识)找到MYD中的文件对应的数据
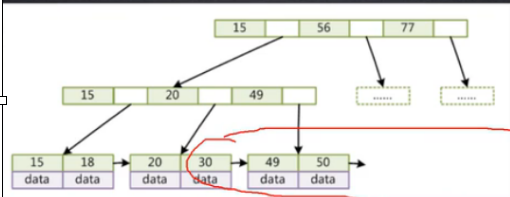
InnoDB存储引擎(聚集)
聚集的意思就是叶子结点包含了完整的数据记录,又叫聚簇索引
ibd文件既是数据文件,也是索引文件,就用B+树的数据结构维护
InnoDB必须要有主键,没有主键表的结构就不能组织起来
整型主键的好处:整形比较起来比字符串快得多,所以查数据也就更快
自增的好处:主键自增,那么意味着每一级从左到右基本上是递增的,在叶子结点上,相邻两个节点之间有双向指针,所以,在sql范围查找时很方便
例如查找>20的数据:
MyISAM VS InnoDB
MyISAM 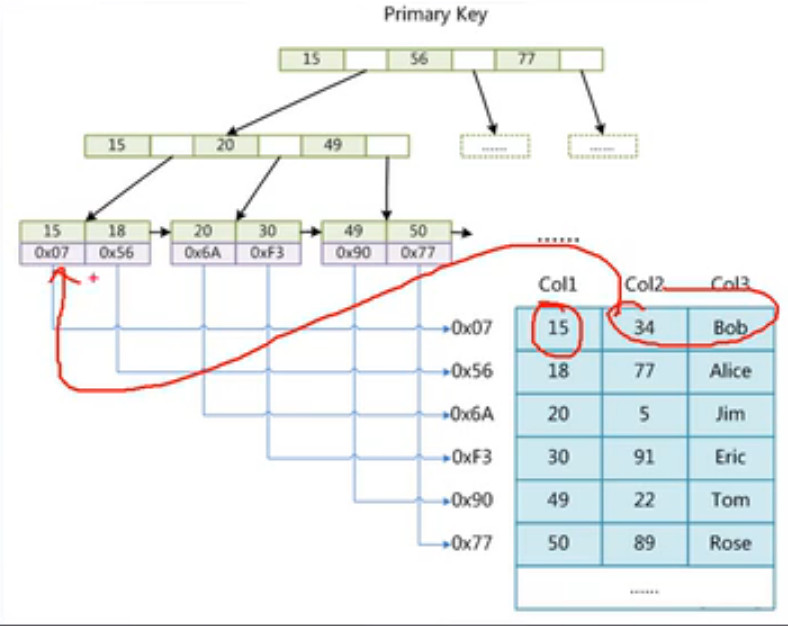 InnoDB
InnoDB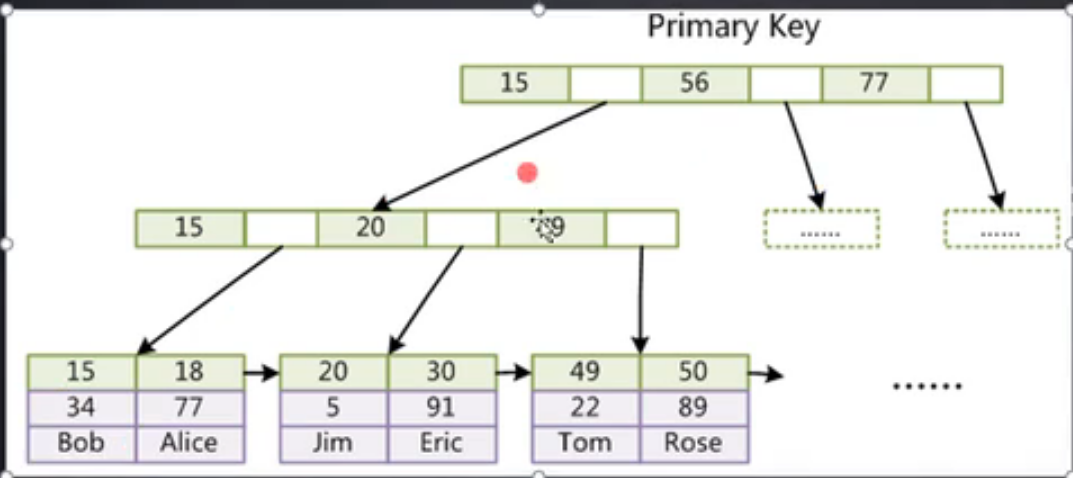
为什么非主键索引结构叶子结点存储主键值(一致性和节省存储空间)
使用自增主键作为InnoDB表的主键会存在一个问题?
Mysql中innodb_page_size = 16kb,选择BIGINT作为主键占用8b,地址也占8b 16kb/(8+8)b = 1000个元素,也就是1001阶的B+Tree树结构,那么每次新增新增一条记录都是在最右边的数据中插入新的数据,当插入1001个元素时,发生列变生成一个新的根节点,而此时的左子节点包含的元素个数是(1001-1)/2=500,此后不会再发生改变,因为每次插入的数据都是在整棵树的最右侧,以此类推会发现会有近乎一半的节点空间是浪费的。下图是以7阶的B+Tree示例:

如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+树
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,ID 的值为 500,再到 ID 索引树搜索一次。这个过程称回表
也就是说,基于非主键索引的查询需要多扫描一棵索引树,因此,我们在应用中应该尽量使用主键查询。