一、Rebalance 过程,如下图:
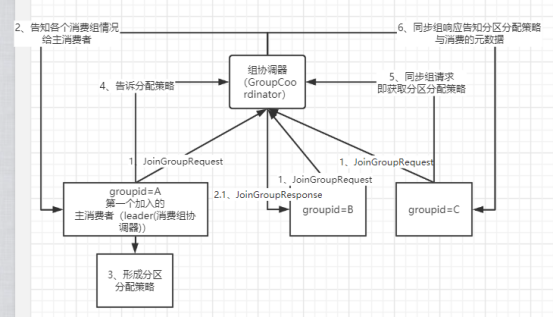
a、确定组协调器
每个 consumer group 都会选择一个 broker 作为自己的组协调器 coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者 rebalance。consumer group 中的每个 consumer 启动时会向 kafka 集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器 GroupCoordinator,并跟其建立网络连接。
组协调器选择方式:通过如下公式可以选出 consumer 消费的 offset 要提交到__consumer_offsets 的哪个分区,这个分区 leader 对应的 broker 就是这个 consumer group 的 coordinator;公式:hash(consumer group id) % __consumer_offsets主题的分区数。
b、加入消费组
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。然后 GroupCoordinator 从一个 consumer group 中选择第一个加入 group 的 consumer 作为leader (消费组协调器即主消费者),把 consumer group 情况发送给这个 leader,接着这个 leader 会负责制定分区方案(由于 rebalance 等策略有客户端配置决定,因此分区方案需要 consumer 来制定,以消费组协调器的配置为准)。
c、同步组信息
consumer leader 通过给 GroupCoordinator 发送分区分配策略信息,接着 GroupCoordinator 就把分区方案通过同步组响应下发给各个 consumer,他们会根据指定分区的 leader broker 进行网络连接以及消息消费。
二、发送重平衡因素
l 消费者订阅的主题集合中任意一个主题的分区数量发生变化。
l 创建或删除一个主题。
l 消费组中已经存在的一个消费者成员挂掉了。
l 个新的消费者成员加入已经存在的消费组中。
l 消费者调用unsubscribe()取消订阅。
三、重平衡分析
发送重平衡因素中只有一个符合为消费组中已经存在的一个消费者成员挂掉了,即协调器认为消费组已经挂掉;使之重平衡。
服务端大量类似日志:
[2021-07-07 17:35:56,773] INFO [GroupCoordinator 148]: Member consumer-23-78dabd92-8e45-46ab-91d6-9511a7834476 in group test21 has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2021-07-07 17:36:06,777] INFO [GroupCoordinator 148]: Stabilized group test21 generation 70 (__consumer_offsets-19) (kafka.coordinator.group.GroupCoordinator)
[2021-07-07 17:36:08,231] INFO [GroupCoordinator 148]: Assignment received from leader for group test21 for generation 70 (kafka.coordinator.group.GroupCoordinator)
[2021-07-07 17:36:14,828] INFO [GroupCoordinator 148]: Preparing to rebalance group test21 with old generation 70 (__consumer_offsets-19) (kafka.coordinator.group.GroupCoordinator)
说明:消费组consumer-23-78dabd92-8e45-46ab-91d6-9511a7834476已不在,接着发生重平衡。
客户端日志:
2021-07-08 11:59:41 DEBUG [id0-21-C-1] o.a.k.c.c.i.AbstractCoordinator - [Consumer clientId=consumer-22, groupId=test21] Attempt to heartbeat failed for since member id consumer-22-db2702c4-248f-4421-b62f-3f88ce99b814 is not valid.
2021-07-08 11:59:41 DEBUG [id0-19-C-1] o.a.k.c.c.i.AbstractCoordinator - [Consumer clientId=consumer-20, groupId=test21] Attempt to heartbeat failed for since member id consumer-20-0e0cef93-43b9-486f-8a96-dc37396238d9 is not valid.
2021-07-08 11:59:41 DEBUG [id0-15-C-1] o.a.k.c.c.i.AbstractCoordinator - [Consumer clientId=consumer-16, groupId=test21] Attempt to heartbeat failed for since member id consumer-16-3433ff33-fa30-4ef3-9f61-6b91caef7107 is not valid.
2021-07-08 11:59:41 INFO [id0-15-C-1] o.a.k.c.c.i.ConsumerCoordinator - [Consumer clientId=consumer-16, groupId=test21] Revoking previously assigned partitions [tests1-0]
2021-07-08 11:59:41 INFO [id0-15-C-1] o.s.k.l.KafkaMessageListenerContainer - partitions revoked: [tests1-0]
2021-07-08 11:59:41 DEBUG [id0-15-C-1] o.a.k.c.c.i.AbstractCoordinator - [Consumer clientId=consumer-16, groupId=test21] Disabling heartbeat thread
2021-07-08 11:59:41 INFO [id0-15-C-1] o.a.k.c.c.i.AbstractCoordinator - [Consumer clientId=consumer-16, groupId=test21] (Re-)joining group
说明:其日志意思大致为心跳连接失败。
接着就会出现重平衡。
四、解决方案
1、增加session.time.out时长,消费者连接至消息队列会话超时时间增加。
2、配置hosts文件ip与hostname的映射。
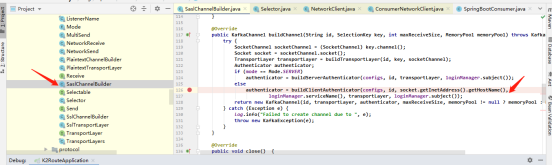
在kafka源码中有获取hostname的方法,此方法使用频繁,配置hosts文件调用断点处基本是秒过 ,但是如果没有配置hosts文件则大约超过5s的时间,差距巨大。
客户端和 服务端的请求处理器,都使用了选择器模式( KafkaChannel )即上图的方法。
即发送心跳的请求也会通过KafkaChannel 来发送,如果KafkaChannel 卡相应慢,则会影响与协调器之间的心跳,间接会导致重平衡。