深度学习(deep learning)是机器学习下的分支
它试图使用包含复杂结构或由多重非线性变换 构成的多个处理层对数据进行高层抽象的算法。
深度学习是机器学习中一种基于对数据进行表征学习的方法。
观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。
而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。
深度学习的好处是用非监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
至今已有数种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和递归神经网络已被应用计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
神经网络,一种启发自生物学的优美的编程范式,能够从观测到的数据中进行学习
图像分类
图像分类问题,输入图像从固定的一组分类中分配一个标签的任务。这是计算机视觉的核心问题之一,尽管它的简单性,有各种各样的实际应用。此外,正如我们将在后面看到的,许多其他看似不同的计算机视觉任务(如对象检测,分割)可以减少到图像分类。
图像分类模型需要单个图像,并将概率分配给4个标签{cat,dog,hat,mug}。如图所示,请记住,对于计算机,图像被表示为数字的一个大的3维数组。在这个例子中,猫图像是248像素宽,400像素高,并且有三个颜色通道红色,绿色,蓝色(或简称RGB)。因此,该图像由248 x 400 x 3数字组成,总共297,600个数字。每个数字是一个整数,范围从0(黑色)到255(白色)。我们的任务是把这个四分之一的数字转成一个单一的标签,如“猫”。

由于识别视觉概念(例如猫)的这个任务对于人类来说相对微不足道,所以值得从计算机视觉算法的角度考虑所涉及的挑战。
数据驱动的方法
我们可以如何编写一个可以将图像分类到不同类别的算法?
与编写一个算法(例如排序数字列表)不同的是,如何编写用于识别图像中的猫的算法是不明显的。
数据驱动是通过移动互联网或者其他的相关软件为手段采集海量的数据,将数据进行组织形成信息,之后对相关的信息进行整合和提炼,在数据的基础上经过训练和拟合形成自动化的决策模型。
人工神经网络
神经网络方面的研究很早就已出现,今天“神经网络”已是一个相当大的、多学科交叉的学科领域。神经网络中最基本的成分是神经元模型。
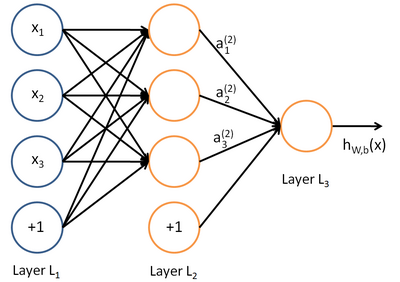
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。
感知器
为了理解神经网络,我们应该先理解神经网络的组成单元——神经元。神经元也叫做感知器。还记得之前的线性回归模型中权重的作用吗?每一个输入值与对应权重的乘积之和得到的数据或通过激活函数来进行判别。下面我们看一下感知器:
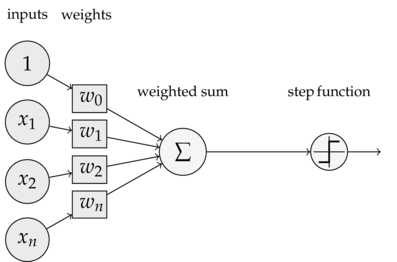
可以看到,一个感知器有如下组成部分:
-
输入权值,一个感知器可以有多个输入:
-

-
每个输入上有一个权值:
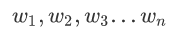
-
激活函数,感知器的激活函数有许多选择

其中z为权重数据积之和
-
输出:

我们了解过sigmoid函数是这样,在之前的线性回归中它对于 二类分类 问题非常擅长。所以在后续的多分类问题中,我们会用到其它的激活函数。
如果是高维空间中,感知器模型寻找的就是一个超平面,能够把所有的二元类别分割开。感知器模型的前提是:数据是线性可分的。
损失函数:
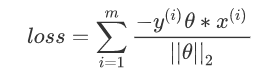
因为此时分子和分母中都包含了θ值,当分子扩大N倍的时候,分母也会随之扩大,也就是说分子和分母之间存在倍数关系,所以可以固定分子或者分母为1,然后求另一个即分子或者分母的倒数的最小化作为损失函数,简化后的损失函数为(分母为1):
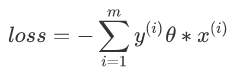
然后使用梯度下降法对该损失函数求解,不过这里由于m是分类错误的样本集合,不是固定的,所以我们不能使用批量梯度下降法(BGD)求解,只能使用随机梯度下降或者小批量来做
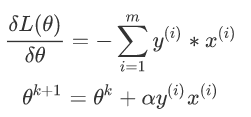
神经网络定义
定义:在机器学习和认知科学领域,人工神经网络(artificialneural network,缩写ANN),简称神经网络(:neural network,缩写NN)或类神经网络,是一种模仿生物神经网络的结构和功能的计算模型,用于对函数进行估计或近似。
基础神经网络:单层感知器,线性神经网络,BP神经网络,Hopfield神经网络等
进阶神经网络:玻尔兹曼机,受限玻尔兹曼机,递归神经网络等
深度神经网络:深度置信网络,卷积神经网络,循环神经网络,LSTM网络等
杰弗里·埃弗里斯特·辛顿 (英语:GeoffreyEverest Hinton)(1947年12月6日-)是一位英国出生的计算机学家和心理学家,以其在神经网络方面的贡献闻名。辛顿是反向传播算法的发明人之一,也是深度学习的积极推动者。
那么我们继续往后看,神经网络是啥?
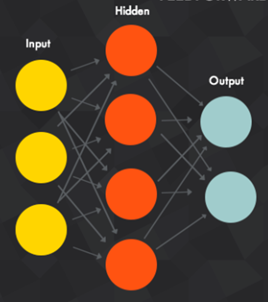
神经网络其实就是按照一定规则连接起来的多个神经元。
-
输入向量的维度和输入层神经元个数相同
-
每个连接都有权值
-
第N层的神经元与第N-1层的所有神经元连接,也叫 全连接
-
上图网络中最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,可以有多个输出层。我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
-
同一层的神经元之间没有连接
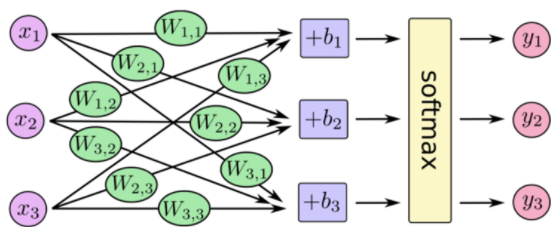
那么我们以下面的例子来看一看,图上已经标注了各种输入、权重信息。

对于每一个样本来说,我们可以得到输入值x_1,x_2,x_3,也就是节点1,2,3的输入值,那么对于隐层每一个神经元来说都对应有一个偏置项b,它和权重一起才是一个完整的线性组合

这样得出隐层的输出,也就是输出层的输入值.
矩阵表示

同样,对于输出层来说我们已经得到了隐层的值,可以通过同样的操作得到输出层的值。那么重要的一点是,分类问题的类别个数决定了你的输出层的神经元个数。
SoftMax回归
首先看公式:
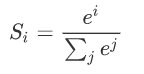

损失函数:
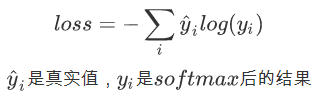
下面是一个简单的两层神经网络的推导:
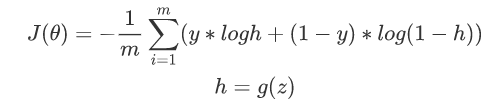
这里g(z)是一个激活函数,我们使用sigmoid函数:
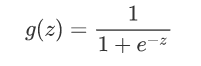
分析两层的神经网络:.
前向传播:
-
输入:
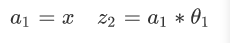
-
隐藏:
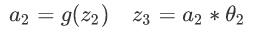
-
输出:
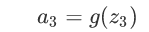
后向传播:
更新θ1和θ2:

神经网络的训练
我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数。
前向传播
神经网络的训练类似于之前线性回归中的训练优化过程。前面我们已经提到过梯度下降的意义,我们可以分为这么几步:
-
计算结果误差
-
通过梯度下降找到误差最小
-
更新权重以及偏置项
这样我们可以得出每一个参数在进行一次计算结果之后,通过特定的数学理论优化误差后会得出一个变化率α
反向传播
就是说通过误差最小得到新的权重等信息,然后更新整个网络参数。通常我们会指定学习的速率λ(超参数),通过 变化率和学习速率 率乘积,得出各个权重以及偏置项在一次训练之后变化多少,以提供给第二次训练使用。

tensorflow神经网络接口的实现
tf.train.GradientDescentOptimizer
在使用梯度下降时候,一般需要指定学习速率
tf.train.GradientDescentOptimizer(0.5)
方法
init
构造一个新的梯度下降优化器
__init__( learning_rate, use_locking=False, name='GradientDescent' )
-
learning_rate tensor或者浮点值,用于学习速率
minimize
添加操作以更新最小化loss,这种方法简单结合调用compute_gradients()和 apply_gradients()(这两个方法也是梯度下降优化器的方法)。如果要在应用它们之前处理梯度,则调用compute_gradients()和apply_gradients()显式而不是使用此函数。
minimize( loss, global_step=None, var_list=None, gate_gradients=GATE_OP, aggregation_method=None, colocate_gradients_with_ops=False, name=None, grad_loss=None )
-
loss 损失值,变量值
-
global_step 变量,在每次更新之后加1