在一个公司内部的Hadoop Yarn集群,肯定会被多个业务、多个用户同时使用,共享Yarn的资源,如果不做资源的管理与规划,那么整个Yarn的资源很容易被某一个用户提交的Application占满,其它任务只能等待,这种当然很不合理,我们希望每个业务都有属于自己的特定资源来运行MapReduce任务,Hadoop中提供的公平调度器–Fair Scheduler,就可以满足这种需求。
Fair Scheduler将整个Yarn的可用资源划分成多个资源池,每个资源池中可以配置最小和最大的可用资源(内存和CPU)、最大可同时运行Application数量、权重、以及可以提交和管理Application的用户等。
Fair Scheduler除了需要在yarn-site.xml文件中启用和配置之外,还需要一个XML文件fair-scheduler.xml来配置资源池以及配额,而该XML中每个资源池的配额可以动态更新,之后使用命令:yarn rmadmin –refreshQueues 来使得其生效即可,不用重启Yarn集群。
需要注意的是:动态更新只支持修改资源池配额,如果是新增或减少资源池,则需要重启Yarn集群。
1.1. 编辑yarn-site.xml
yarn集群主节点中yarn-site.xml添加以下配置
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim yarn-site.xml
<!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 默认提交到default队列 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 如果提交一个任务没有到任何的队列,是否允许创建一个新的队列,设置false不允许 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property><!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 默认提交到default队列 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 如果提交一个任务没有到任何的队列,是否允许创建一个新的队列,设置false不允许 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
1.2. 添加fair-scheduler.xml配置文件
yarn主节点执行以下命令,添加faie-scheduler.xml的配置文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim fair-scheduler.xml
详细见附件资料。
1.3. scp分发配置文件、重启yarn集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
scp yarn-site.xmlfair-scheduler.xml node02:$PWD
scp yarn-site.xmlfair-scheduler.xml node03:$PWD
stop-yarn.sh
start-yarn.sh
1.4. 创建普通用户hadoop
node-1执行以下命令添加普通用户
useradd hadoop
passwd hadoop
1.5. 赋予hadoop用户权限
修改hdfs上面tmp文件夹的权限,不然普通用户执行任务的时候会抛出权限不足的异常。以下命令在root用户下执行。
groupadd supergroup
usermod -a -G supergroup hadoop 修改用户所属的附加群主
su - root -s /bin/bash -c "hdfs dfsadmin -refreshUserToGroupsMappings"
刷新用户组信息
1.6. 使用hadoop用户提交程序
su hadoop
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar pi 10 20
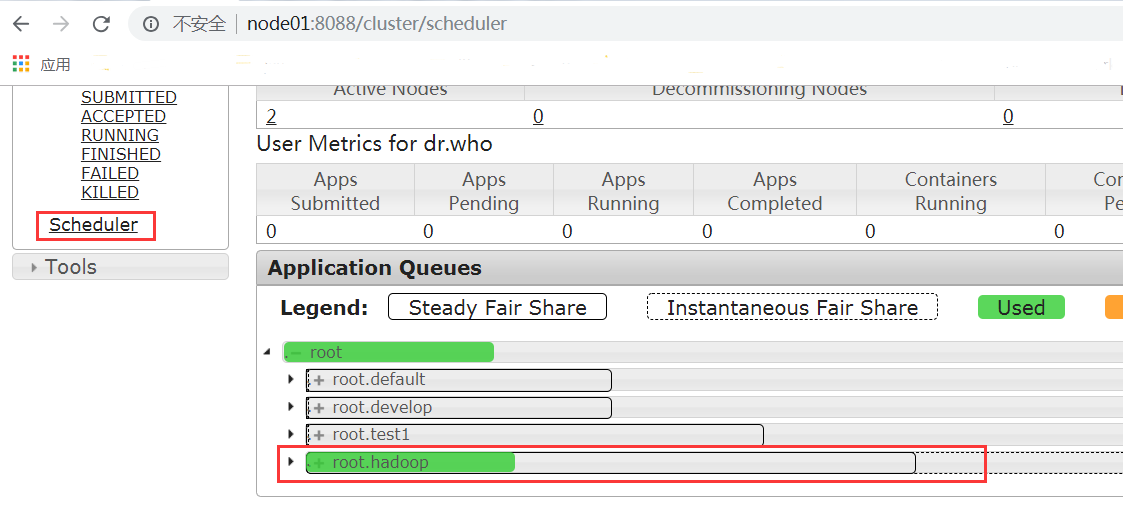
1.7. 浏览器查看结果
http://node01:8088/cluster/scheduler
浏览器界面访问,查看Scheduler,可以清晰的看到任务提交到了hadoop队列里面去了。