map方法:
map的方法
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
key:偏移量,一般为0,用不到
value:每行的值
context:可以记录输入的key和value
例如:context.write(new Text("hadoop"), new IntWritable(1));
此外context还会记录map运算的状态。10
1
map的方法
2
3
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
4
5
key:偏移量,一般为0,用不到
6
value:每行的值
7
context:可以记录输入的key和value
8
9
例如:context.write(new Text("hadoop"), new IntWritable(1));
10
此外context还会记录map运算的状态。
rediuce方法:
reduce的方法
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
reduce函数的输入也是一个key/value的形式,
不过它的value是一个迭代器的形式Iterable<IntWritable> values,
也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。1
reduce的方法
2
3
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
4
5
reduce函数的输入也是一个key/value的形式,
6
不过它的value是一个迭代器的形式Iterable<IntWritable> values,
7
8
也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。
job:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不赘述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,第四行是装载Combiner类。
第六行和第七行是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。x
1
Job job = new Job(conf, "word count");
2
job.setJarByClass(WordCount.class);
3
job.setMapperClass(TokenizerMapper.class);
4
job.setCombinerClass(IntSumReducer.class);
5
job.setReducerClass(IntSumReducer.class);
6
job.setOutputKeyClass(Text.class);
7
job.setOutputValueClass(IntWritable.class);
8
9
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不赘述了,一个是这个job的名称。
10
11
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
12
13
第三行和第五行就是装载map函数和reduce函数实现类了,第四行是装载Combiner类。
14
15
第六行和第七行是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
第一行就是构建输入的数据文件
第二行是构建输出的数据文件
最后一行如果job运行成功了,我们的程序就会正常退出。
FileInputFormat和FileOutputFormat可以设置输入输出文件路径,mapreduce计算时候,输入文件必须存在,要不直Mr任务直接退出。输出一般是一个文件夹,而且该文件夹不能存在。1
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
2
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
3
System.exit(job.waitForCompletion(true) ? 0 : 1);
4
5
第一行就是构建输入的数据文件
6
第二行是构建输出的数据文件
7
最后一行如果job运行成功了,我们的程序就会正常退出。
8
FileInputFormat和FileOutputFormat可以设置输入输出文件路径,mapreduce计算时候,输入文件必须存在,要不直Mr任务直接退出。输出一般是一个文件夹,而且该文件夹不能存在。
map端job:图示:
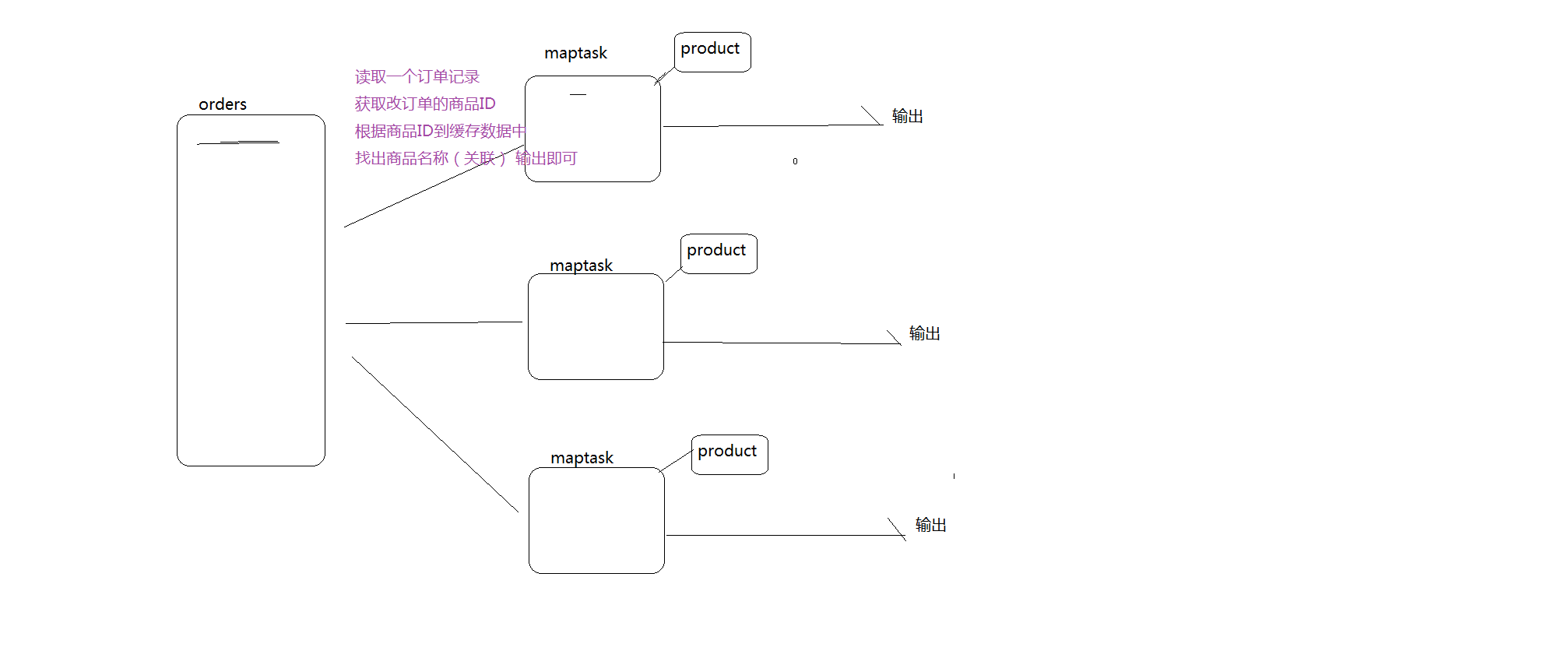
reduce端job:图示:
