软件测试的心理学和经济学
软件测试的原则
- 测试用例中一个必需部分是对预期输出或结果的定义
- 程序员应该避免测试自己编写的程序
- 编写软件的组织不应当测试自己编写的软件
- 应当彻底检查每个测试的执行结果
- 测试用例的编写不仅应当根据有效和预期的输入情况,而且应当根据无效和未预料到的输入情况。
等价类,场景,错误推测,正交。 - 检查程序是否“未做其应该做的”仅是测试的一半,测试的另一半是检查程序是否“做了其不应该做的”
- 避免测试用例用后即弃,除非软件本身是一个一次性的软件
- 计划测试工作时不应默许假定不会发现错误
测试,是为了发现错误而执行程序的过程!!! - 程序某部分可能存在更多错误的可能性与该部分已发现的错误的数量成正比
可能程序员在编写这段代码时心情不太好。哈哈~ - 软件测试是一项极富创造性,极具智力挑战性的工作
代码检查,走查,评审
代码检查与走查
走查:开发人员(3-4人,一个作者)
- 一旦发现错误,通常能在代码中精确定位,降低调试成本。
- 通常能发现30%-70%的逻辑设计和编码错误,但是无法发现高层次的设计错误(如需求分析阶段的错误)
代码检查
方法:组成一个小组(一个测试专家+一个协调人,不能是作者)阅读或直观检查特定程序;
协调人作用:
- 为代码检查分发材料,安排进程
- 在代码检查中起主导作用
- 记录发现的所有错误
- 确保所有错误随后得到改正
检查议程和注意事项
- 检查前几天协调人分发程序清单和设计规范给其他成员
- 检查时,由作者逐条语句讲述程序的逻辑结构。
- 检查时,每个参与者致力于发现错误而不是修正错误。
- 根据错误清单分析,归纳,用以提炼错误列表,以便提高代码检查的效率。
时间尽量在90-120分钟。时间越长效率越低
代码检查的衍生功效
- 程序员会得到编程风格,算法选择及编程技术等方面的反馈信息
- 其他参与者也可以通过接触程序员的错误和编程风格而痛殴贵阳受益匪浅
- 有助于在早期就发现程序中脆弱部分的方法之一
用于代码检查的错误列表
- 数据引用错误
- 变量未赋值,未初始化
- 数组引用,下标是否在规定的界限范围之内?
- 数组引用是否下标都是整数?
- 对于通过指针或引用变量的引用,当前引用的内存单元是否分配?
这就是所谓的“虚调用”(danglingreference)错误。当指针的生命期大于所引用内存单元的生命期时,错误就会发生。当指针引用了过程中的一个局部变量,而指针的值又被赋给一个输出参数或一个全局变量,过程返回(释放了引用的内存单元)结束,尔后程序试图使用指针的值时,这种错误就会发生。与前面检查错误的方法类似,应试图非正式地“证明”,对于每个使用指针值的引用,引用的内存单元都存在。
- 如果一个内存区域具有不同属性的别名,当通过别名进行引用时,内存区域内的数据值是否具有正确的属性?
在FORTRAN语言中对EQUIVALENCE语句使用,或COBOL语言中对REDEFINES语句使用的地方,都可能发生这种错误。例如,一个FORTRAN语言程序包含一个实型变量A和一个整型变量B,两者都通过使用EQUIVALENCE语句而成为同一内存区域的别名。如果程序先对A赋值,然后又引用变量B,由于机器可能会将内存中用浮点位表示的实数当做整数,在这种情况下错误就可能发生。
- 变量值的类型或属性是否与编译器预期的一致?
- 在使用的计算机上,当内存分配的单元小于内存可寻址的单元大小时,是否存在直接或间接的寻址错误?
- 当使用指针或引用变量时,被引用的内存的属性是否与编译器所预期的一致?
- 假如一个数据结构在多个过程或子程序中被引用,那么每个过程或子程序对该结构的定义是否都相同?
- 如果字符串有索引,当对数组进行索引操作或下标引用,字符串的边界取值是否有“仅差一个”(off-by-one)的错误?
"仅差一个"错误: 就是指某个变量的最大值和最小值可能会和正常值差1,或者循环多执行一次/少执行一次。 - 对于面向对象的语言,是否所有的继承需求都在实现类中得到了满足?
- 数据声明错误
- 是否所有的变量都进行了明确的声明?
- 如果变量所有的属性在声明中没有明确说明,那么默认的属性是否能被正确理解?
- 变量初始化是否正确?
- 是否每个变量都被赋予正确的长度和数据类型?
- 变量初始化是否与其存储空间的类型一致?
- 是否存在相似名称的变量?(容易混淆)
- 运算错误
- 是否存在不一致的数据类型的变量间的运算?
- 是否有混合模式的运算?
- 是否有相同数据类型,不同字节变量间的运算?
- 赋值语句的目标变量的数据类型是否小于右边表达式的数据类型或结果?
- 在表达式的运算中是否存在表达式向上或向下溢出的情况?
- 除法运算的除数是否可能为0?
- 如果计算机表达变量的基本方式是基于二进制的,那么运算结果是否不精确?
- 在特定场合,变量的值是否超出了有意义的范围?
- 对于包含一个以上操作符的表达式,赋值顺序和操作符的优先顺序是否正确?
- 整数的运算是否有使用不当的情况,尤其是除法?
- 比较错误
- 是否有不同数据类型的变量之间的比较运算?
- 是否有混合模式的比较运算,或不同长度的变量间的比较运算?
- 比较运算符是否正确?
- 每个布尔表达式所叙述的内容是否都正确?
- 布尔运算符的操作数是否是布尔类型的?比较运算符和布尔运算符是否错误的混在一起?
- 在二进制的计算机上,是否有用二进制表示的小数或浮点数的比较运算?
- 编译器计算布尔表达式的方式是否会对程序产生影响?
- 控制流程错误
- 如果有多条分支路径,索引变量的值是否会大于可能的分支数量?
- 是否所有的循环最终都终止了?
- 程序,模块或子程序是否最终都终止了?
- 由于实际情况没有满足循环的入口条件,循环体是否可能从未执行过?
- 如果循环同时由迭代变量和一个布尔条件控制,如果循环越界了.后果会如何?
- 是否存在"仅差一个"的错误?
- 是否每一组语句都有一个明确的while语句并且do语句也与其相应的与剧组对应?
- 是否存在不能穷尽的判断?
- 接口错误
- 调用模块参数数量是否正确?顺序是否正确?
- 实参属性(如数据类型与大小)是否匹配?
- 实参的量纲是否匹配?
- 如果调用了内置函数,实参的数量,属性,顺序是否正确?
- 如果模块或类有多个入口,是否引用了与当前入口无关的形参?
- 是否有子程序改变了某个原本仅为输入值的形参?
- 如果存在全局变量,在所有引用它们的模块中,他们的定义和属性是否相同?
- 常熟是否以实参形式传递过?
- 输入/输出错误
- 如果对文件明确声明过,其属性是否正确?
- 打开文件的语句中各项属性的设置是否正确?
- 格式规范是否与I/O语句中的信息相吻合?
- 是否有足够的可用内存空间,来保留程序将读取的文件?
- 是否所有的文件在使用之前都打开了?
- 是否所有的文件在使用之后都关闭了?
- 是否判断文件结束的条件,并正确处理?
- 对I/O出错情况处理是否正确?
- 任何打印或显示的文本信息是否存在拼写或语法错误?
- 程序是否正确处理了类似file not found 这样的错误?
- 其他检查
- 程序是否遗漏了某个功能?
代码走查
小组人员:
·一位极富经验的程序员;
·一位程序设计语言专家;
·一位程序员新手(可以给出新颖、不带偏见的观点);
·最终维护程序的人员;
·一位来自其他不同项目的人员;
·一位来自该软件编程小组的程序员。
与代码检查的区别: 代码走查的参与者使用了计算机,测试人员会准备一些测试用例(程序或模块中具有代表性的输入集及预期的输出集)来参与会议,在会议期间每个测试用例都在人们脑中推演.
桌面检查
由单人进行的代码检查或走查,对照错误列表检查程序推演测试数据.
- 效率慢
- 没意义,只比没有检查好
同行评审
根据程序整体质量,可维护性,可扩展性,易用性和清晰性对匿名程序进行评价的技术.该项技术的目的是为程序员提供自我评价的手段。
测试用例的设计
白盒测试
- 逻辑覆盖测试: 执行每一条语句,缺点: 可能有些条件(if a>1 or b>1)没有被执行,即使每条路径都执行了;
- 判定覆盖/分支覆盖: 使每一个判定至少有一个为真或为假的输出结果;
- 条件覆盖: 确保每一个判断中的每个条件的所有可能的结果至少执行一次.
- 多重条件覆盖准则: 将每个判定中的所有可能的条件结果的组合,以及所有的入口点都至少执行一次.
等价类划分
特性:
- 严格控制测试用例的增加,减少为达到"合理测试"的某些既定目标而必须设计的其他用例;
- 覆盖了大部分其他可能的测试用例.
步骤: 1. 确定等价类 2. 生成测试用例
确定等价类
思路: 选取每一个输入条件并将其划分为两个或更多的组.确定有效等价类(有效输入)及无效等价类(不正确的输入值)
指导原则:
- 输入条件规定取值范围(如,数量可以是1-999),有效等价类(1<数量<999),无效等价类(数量<1,数量>999)
- 输入条件规定了取值的个数(汽车可登记一至六名车主),有效等价类(1-6个车主),无效等价类(无车主,车主多于6个)
- 输入条件规定了一个集合,每个值进行不同处理(交通工具必须是公共汽车,卡车,出租车,火车,摩托车),有效等价类(公共汽车,卡车,出租车,火车,摩托车),无效等价类(拖车)
- 输入条件规定了"必须是"(首字符必须是字母),有效等价类(首字符是字母),无效等价类(首字符不是字母)
生成测试用例
- 为等价类设置编号
- 编写新的测试用例,尽可能多覆盖有效等价类
- 编写新的用例,覆盖一个且仅一个无效等价类
边界值分析
边界条件,是指输入和输出等价类中那些恰好处于边界、或超过边界、或在边界以下的状态.
通用指南:
- 输入/输出条件规定取值范围(如有效范围是-1.0至+1.0),边界值:-1.0,+1.0,-1.001,+1.001
- 输入/输出条件规定输入值的数量(文件可容纳1-255条记录),边界值:0,1,255,256
- 输入/输出条件规定为有序序列,则应该特别注意序列的第一一个和最后一个元素.
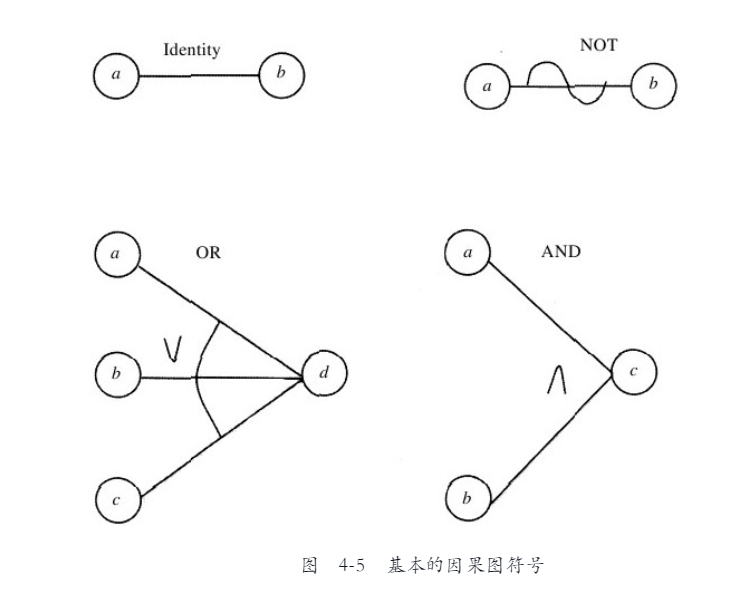
因果图分析
所谓"因" ,指一个明确的输入条件或输入条件的等价类;
所谓"果",指一个输出条件或系统转换;
因果图中的基本符号如图4-5所示。设想一下,每个结点的值为0或为1,0代表“不存在”状态,1代表“存在”状态。identity函数表示如果a等于1,则b也为1,否则b为0。NOT函数表示如果a等于1,则b为0;否则b为1。OR函数表示如果a或b或c等于1,则d为1;否则d为0。AND函数表示如果a和b都等于1,则c为1;否则c为0。后两个函数(OR和AND)允许存在任意数量的输入。
错误猜测
基于经验的推测
测试用例设计方法策略
- 输入条件组合的情况,优先使用因果图分析
- 任何情况都要使用边界值分析
- 为输入输出确定有效和无效等价类
- 错误猜测分析增加更多用例
- 逻辑覆盖(判定覆盖,条件覆盖,判定/条件覆盖,多重条件覆盖准则)