1 写在前边的话
网上找了很多tensorflow的教程,大多是以demo展开的,有人觉得挺好,但是我总觉得不太系统,特别是对于初学者来说不友好,所以打算出一个tensorflow的简单教程,从TensorFlow的计算模型、数据模型和运行模型三个方面入手。如有错误,请指正!
2 TensorFlow计算模型——计算图
计算图是TensorFlow中最基本的一个概念,TensorF low中的所有计算都会被转化为计算图上的节点,而节点之间的边描述了计算之间的依赖关系,那么什么是依赖关系呢?如果一个运算的输入依赖于另一个运算的输出,那么这两个运算有依赖关系。这样说可能会有点抽象,下边举个例子体会一下:
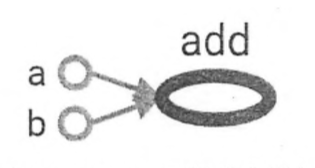
在上图中,a和b这两个常量不依赖任何其他计算。而add计算则依赖读取两个常量的取值。于是可以看到有一条从a到add的边和一条从b到add的边。因为没有任何计算依赖add的结果,于是代表加法的节点add没有任何指向其他节点的边。所有TensorFlow的程序都可以通过类似的计算图的形式来表示,这就是TensorFlow的基本计算模型。
2.1 计算图的使用
TensorFlow 程序一般可以分为两个阶段。在第一个阶段需要定义计算图中所有的计算。第二个阶段为执行计算,这个阶段将在Tensorflow的运行模型进行介绍。以下代码给出了计算定义阶段的样例。
import tensorflow as tf
a = tf.constant([1.0,2.0], name="a")
b = tf.constant([2.0,3.0], name="b")
result = a +b
在Python中一般会采用“import tensorflow as tf”的形式来载入TensorFlow,这样可以使用“tf”来代替“tensorflow”作为模块名称,使得整个程序更加简洁。这是TensorFlow中非常常用的技巧。在这个过程中,TensorFlow会自动将定义的计算转化为计算图上的节点。在TensorFlow程序中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图。以下代码示意了如何获取默认计算图以及如何查看一个运算所属的计算图。
#通过a.graph可以查看张量所属的计算图。因为没有特意指定,所以这个计算图应该等于
#当前默认的计算图。所以下面这个操作输出值为True。
print(a.graph is tf.get default_graph())
除了使用默认的计算图,TensorFlow支持通过tf.Graph函数来生成新的计算图。不同计算图上的张量和运算都不会共享。以下代码示意了如何在不同计算图上定义和使用变量。
import tensorflow as tf
g1=tf.Graph()
with gl.as default():
#在计算图g1中定义变量“v”,并设置初始值为0。
v=tf.get_variable(
"v",initializer=tf.zeros_initializer(shape=[1]))
g2=tf.Graph()
with g2.as default():
#在计算图g2中定义变量“v”,并设置初始值为1。
v=tf.get variable(
"v",initializer=tf.ones_initializer(shape=[1]))
#在计算图g1中读取变量“v”的取值。
with tf.Session(graph=g1)as sess:
tf.initialize all variables().run()
with tf.variable scope("",reuse=True):
#在计算图g1中,变量“v”的取值应该为0,所以下面这行会输出[0.]。
print(sess.run(tf.get_variable("v")))
#在计算图g2中读取变量“v”的取值。
with tf.Session(graph=g2)as sess:
tf.initialize all variables().run()
with tf.variable scope("",reuse=True):
#在计算图g2中,变量“v”的取值应该为1,所以下面这行会输出[1.]。
print(sess.run(tf.get_variable("v")))
上面的代码产生了两个计算图,每个计算图中定义了一个名字为“v”的变量。在计算图g1中,将v初始化为0;在计算图g2中,将v初始化为1。可以看到当运行不同计算图时,变量v的值也是不一样的。TensorFlow中的计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算的机制。计算图可以通过tf.Graph.device函数来指定运行计算的设备。这为TensorFlow使用GPU提供了机制。下面的程序可以将加法计算跑在GPU上。
g=tf.Graph()
#指定计算运行的设备。
with g.device('/gpu:0'):
result=a +b
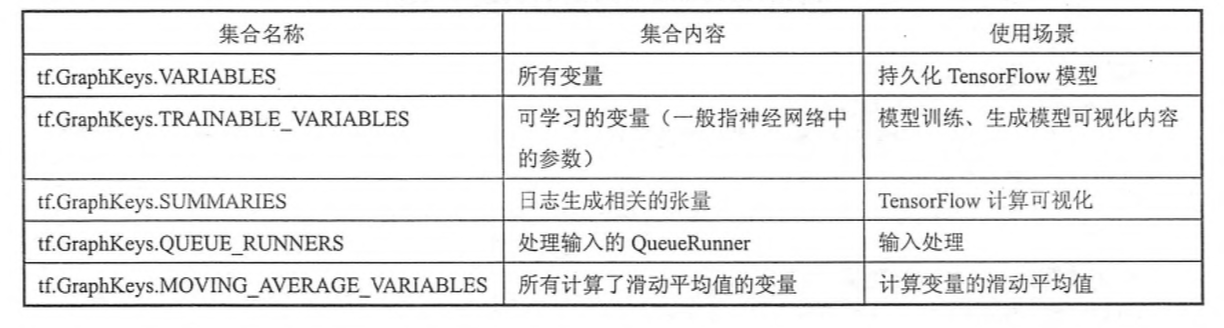
具体使用GPU的方法以后我会重新整理一篇博文详述。有效地整理TensorFlow程序中的资源也是计算图的一个重要功能。在一个计算图中,可以通过集合(collection)来管理不同类别的资源。比如通过tf.add to collection函数可以将资源加入一个或多个集合中,然后通过tf.get_collection获取一个集合里面的所有资源。这里的资源可以是张量、变量或者运行TensorFlow 程度所需要的队列资源,等等。为了方便使用,TensorFlow也自动管理了一些最常用的集合,下表总结了最常用的几个自动维护的集合。
3 TensorFlow数据模型——张量
上节介绍了使用计算图的模型来描述TensorFlow中的计算。这一个节将介绍TensorFlow中另外一个基础概念——张量。张量是TensorFlow管理数据的形式,在3.1小节中将介绍张量的一些基本属性。然后在3.2小节中将介绍如何通过张量来保存和获取TensorFlow 计算的结果。
3.1 张量的概念
从TensorFlow的名字就可以看出张量(tensor)是一个很重要的概念。在TensorFlow程序中,所有的数据都通过张量的形式来表示。从功能的角度上看,张量可以被简单理解为多维数组。其中零阶张量表示标量(scalar),也就是一个数;第一阶张量为向量(vector),也就是一个一维数组;第n阶张量可以理解为一个n维数组。但张量在TensorFlow中的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。还是以向量加法为例,当运行如下代码时,并不会得到加法的结果,而会得到对结果的一个引用。
import tensorflow as tf
#tf.constant是一个计算,这个计算的结果为一个张量,保存在变量a中。
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([2.0,3.0],name="b")
result=tf.add(a,b,name="add")
print result
输出为:
Tensor("add:0",shape=(2,),dtype=float32)
从上面的代码可以看出TensorFlow中的张量和NumPy中的数组不同,TensorFlow计算的结果不是一个具体的数字,而且一个张量的结构。从上面代码的运行结果可以看出,一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)。
张量的第一个属性名字不仅是一个张量的唯一标识符,它同样也给出了这个张量是如何计算出来的。在第2节中介绍了TensorFlow的计算都可以通过计算图的模型来建立,而计算图上的每一个节点代表了一个计算,计算的结果就保存在张量之中。所以张量和计算图上节点所代表的计算结果是对应的。这样张量的命名就可以通过“node:src output”的形式来给出。其中node为节点的名称,src_output表示当前张量来自节点的第几个输出。比如上面代码打出来的“add:0”就说明了result这个张量是计算节点“add”输出的第一个结果(编号从0开始)。
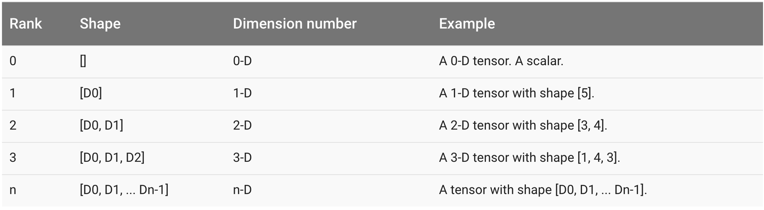
张量的第二个属性是张量的维度(shape)。这个属性描述了一个张量的维度信息。比如上面样例中shape=(2,)说明了张量result是一个一维数组,这个数组的长度为2。其他维度的表示见下图:
张量的第三个属性是类型(type),每一个张量会有一个唯一的类型。TensorFlow会对参与运算的所有张量进行类型的检查,当发现类型不匹配时会报错。比如运行下面这段程序时就会得到类型不匹配的错误:
import tensorflow as tf
a=tf. constant([1,2], name="a")
b=tf. constant([2.0,3.0], name="b")
result=a+b
这段程序和上面的样例基本一模一样,唯一不同的是把其中一个加数的小数点去掉了。这会使得加数a的类型为整数而加数b的类型为实数,这样程序会报类型不匹配的错误:
ValueError:Tensor conversion requested dtype int32 for Tensor with dtype float32:'Tensor("b:0",shape=(2,),dtype=float32)'
如果将第一个加数指定成实数类型“a=tf.constant([1,2],name="a",dtype=tf.float32)",那么两个加数的类型相同就不会报错了。如果不指定类型,TensorFlow会给出默认的类型,比如不带小数点的数会被默认为int32,带小数点的会默认为float32。因为使用默认类型有可能会导致潜在的类型不匹配问题,所以一般建议通过指定dtype来明确指出变量或者常量的类型。TensorFlow支持14种不同的类型,主要包括了实数(tf.float32、tf.float64)、整数(tfint8、tfint16、tf.int32、tf.int64、tf.uint8)、布尔型(tf.bool)和复数(tf.complex64,tf.complex128)。
3.2 张量的使用
和TensorFlow的计算模型相比,TensorFlow的数据模型相对比较简单。张量使用主要可以总结为两大类。
第一类用途是对中间计算结果的引用。当一个计算包含很多中间结果时,使用张量可以大大提高代码的可读性。以下为使用张量和不使用张量记录中间结果来完成向量相加的功能的代码对比。
#使用张量记录中间结果
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([2.0,3.0],name="b")
result=a+b
#直接计算向量的和,这样可读性会比较差。
result=tf.constant([1.0,2.0],name="a")+
tf.constant([2.0,3.0],name="b")
从上面的样例程序可以看到a和b其实就是对常量生成这个运算结果的引用,这样在做加法时就可以直接使用这两个变量,而不需要再去生成这些常量。当计算的复杂度增加时(比如在构建深层神经网络时)通过张量来引用计算的中间结果可以使代码的可阅读性大大提升。同时通过张量来存储中间结果,这样可以方便获取中间结果。比如在卷积神经网络中,卷积层或者池化层有可能改变张量的维度,通过result.get_shape函数来获取结果张量的维度信息可以免去人工计算的麻烦。
使用张量的第二类情况是当计算图构造完成之后,张量可以用来获得计算结果,也就是得到真实的数字。虽然张量本身没有存储具体的数字,但是通过下面的小节中介绍的会话(session),就可以得到这些具体的数字。比如在上述代码中,可以使用tf.SessionO.run(result)语句来得到计算结果。
4 TensorFlow运行模型——会话
前面的两节介绍了TensorFlow是如何组织数据和运算的。本节将介绍如何使用TensorFlow中的会话(session)来执行定义好的运算。会话拥有并管理TensorFlow程序运行时的所有资源。当所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄漏的问题。TensorFlow中使用会话的模式一般有两种,第一种模式需要明确调用会话生成函数和关闭会话函数,这种模式的代码流程如下。
#创建一个会话。
sess=tf.Session()
#使用这个创建好的会话来得到关心的运算的结果。比如可以调用 sess.run(result),
#来得到第3节样例中张量result的取值。
sess.run(...)
#关闭会话使得本次运行中使用到的资源可以被释放。
sess.close()
使用这种模式时,在所有计算完成之后,需要明确调用Session.close函数来关闭会话并释放资源。然而,当程序因为异常而退出时,关闭会话的函数可能就不会被执行从而导致资源泄漏。为了解决异常退出时资源释放的问题,TensorFlow可以通过Python的上下文管理器来使用会话。以下代码展示了如何使用这种模式。
#创建一个会话,并通过Python中的上下文管理器来管理这个会话。
with tf.Session()as sess:
#使用这创建好的会话来计算关心的结果。
sess.run(..…)
#不需要再调用“Session.close()”函数来关闭会话,
#当上下文退出时会话关闭和资源释放也自动完成了。
通过Python上下文管理器的机制,只要将所有的计算放在“with”的内部就可以。当上下文管理器退出时候会自动释放所有资源。这样既解决了因为异常退出时资源释放的问题,同时也解决了忘记调用Session.close函数而产生的资源泄。
第2节介绍过TensorFlow会自动生成一个默认的计算图,如果没有特殊指定,运算会自动加入这个计算图中。TensorFlow中的会话也有类似的机制,但TensorFlow不会自动生成默认的会话,而是需要手动指定。当默认的会话被指定之后可以通过tf.Tensor.eval函数来计算一个张量的取值。以下代码展示了通过设定默认会话计算张量的取值。
sess=tf.Session()
with sess. as default():
print(result. eval())
以下代码也可以完成相同的功能:
sess=tf.Session()
#下面的两个命令有相同的功能。
print(sess.run(result))
print(result.eval(session=sess))
在交互式环境下(比如Python脚本或者Jupyter的编辑器下),通过设置默认会话的方式来获取张量的取值更加方便。所以TensorFlow提供了一种在交互式环境下直接构建默认会话的函数。这个函数就是tf.InteractiveSession。使用这个函数会自动将生成的会话注册为默认会话。以下代码展示了tf.InteractiveSession函数的用法。
sess=tf.InteractiveSession()
print(result.eval())
sess.close()
通过tf.InteractiveSession函数可以省去将产生的会话注册为默认会话的过程。无论使用哪种方法都可以通过ConfigProto Protocol Buffer来配置需要生成的会话。下面给出了通过ConfigProto配置会话的方法:
config=tf. ConfigProto(allow soft placement=True, log_device _placement=True)
sess1=tf. InteractiveSession(config=config)
sess2=tf. Session(config=config)
通过ConfigProto可以配置类似并行的线程数、GPU分配策略、运算超时时间等参数。在这些参数中,最常用的有两个,第一个是allow_softplacement,这是一个布尔型的参数,当它为True的时候,在以下任意一个条件成立的时候,GPU上的运算可以放到CPU上进行:
- 运算无法在GPU上执行。
- 没有GPU资源(比如运算被指定在第二个GPU上运行,但是机器只有一个GPU)。
- 运算输入包含对CPU计算结果的引用。
这个参数的默认值为False,但是为了使得代码的可移植性更强,在有GPU的环境下这个参数一般会被设置为True。不同的GPU驱动版本可能对计算的支持有略微的区别,通过将allow_soft placement参数设为True,当某些运算无法被当前GPU支持时,可以自动调整到CPU上,而不是报错。类似的,通过将这个参数设置为True可以让程序在拥有不同数量的GPU机器上顺利运行。
第二个使用得比较多的配置参数是log device placement。这也是一个布尔型的参数,当它为True时日志中将会记录每个节点被安排在了哪个设备上以方便调试。而在生产环境中将这个参数设置为False可以减少日志量。