1、博客目前在学习爬虫课程,使用正则表达式来爬取网页的图片信息
2、下面我们一起来回归下Python中的正则使用方式/方法
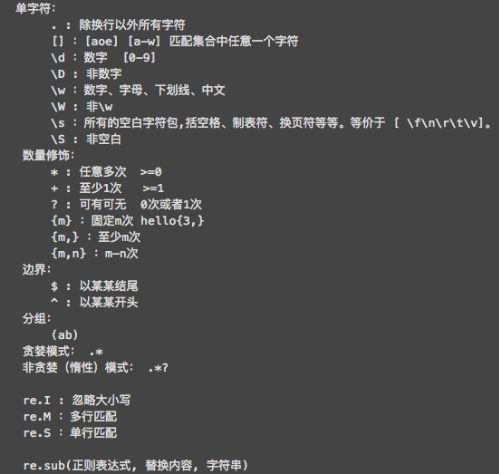
3、糗事百科图片爬取源码如下:
import requests
import re
import os
if __name__ == '__main__':
# headers请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
# 新建文件夹用来存储糗事图片
if not os.path.exists('./qiushiLibs'):
os.makedirs('./qiushiLibs')
# Url进行封装循环分页爬取
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for page in range(1,2):
new_url = format(url%page)
# 调用get请求获取text字符串
page_source = requests.get(url=new_url,headers=headers).text
# 正则表达式:使用到非贪婪模式
ER = r'<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 返回list数组
img_src_list = re.findall(ER,page_source,re.S)
for src in img_src_list:
# 遍历拼接图片URL
src = 'https:'+src
# 下载图片新建请求
# 以二进制流的方式存储
img_content = requests.get(url=src,headers=headers).content
# print(img_content)
# 生成图片的名称
imgName = src.split('/')[-1]
# 图片路径
imgPath = './qiushiLibs/'+imgName
# 持久化存储
with open(imgPath,'wb') as fp:
fp.write(img_content)
print(imgName,'下载成功!!!')