数据分析离不开数据的支持,为了分析唯品会,特地采集唯品会数据。
采集入口为手机端,在火狐浏览器下ctrl+shift+M进入手机模式,并点击触屏模式,进入唯品会网站m.vip.com,刷新网页。
点击右上角的搜索:

点击品牌:

这时候打开火狐的firebug,随便进入一个店铺,这时候系统会向唯品会发送一个post,可以在firebug里面找到这个post如下图:
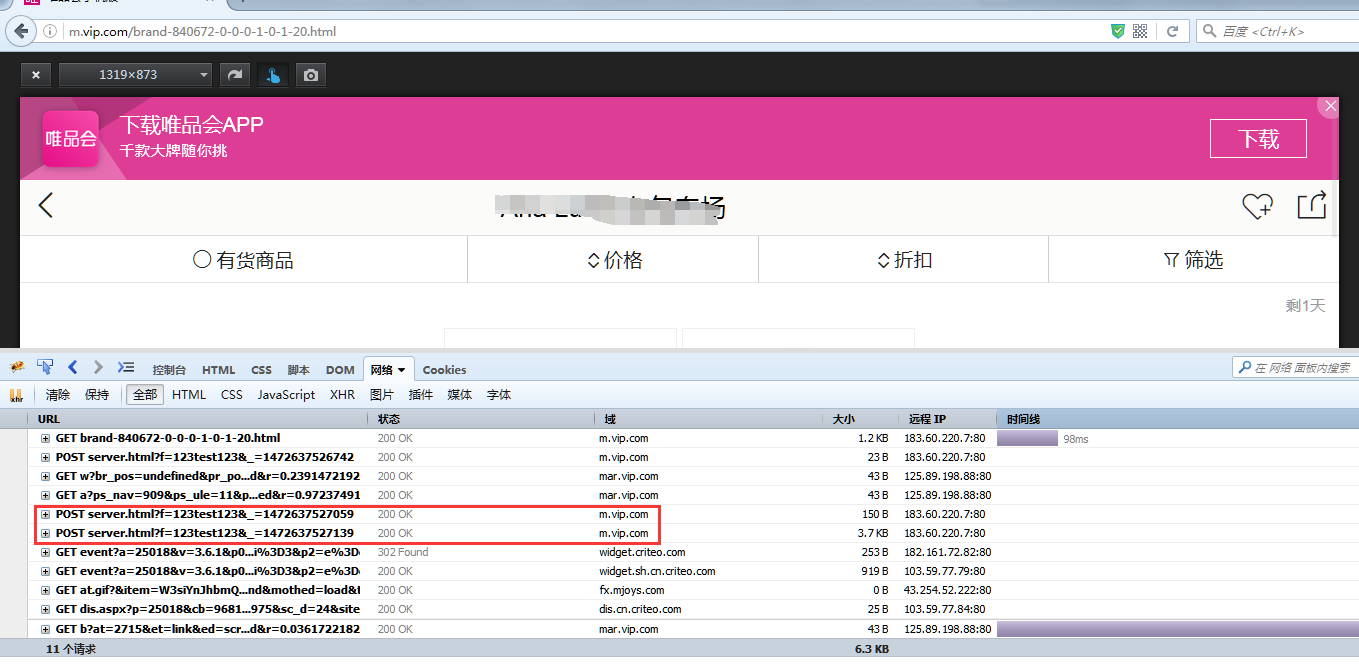
点开+号,选择post:

可以看到框起来的部分就是发送的post。由于唯品会这里属于异步瀑布流加载,我们下拉页面,观察下一个post,看一下翻页功能是哪一个。最终得到的页面如下:

可以看到np变成了3,其实老爬虫都会知道,np一般是代表翻页的,那么我们的程序可以写个翻页的代码:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 # 抓取的页数 4 try: 5 np = int(input("请输入抓取的页数:(默认10页):")) 6 if np == 0: 7 np = 10 8 except: 9 np = 10
接下来看到在页面首部有如下选项:

一个一个点击,比如有货商品,观察发送的post:

可以看到这个:
filter_stock:1
所以写下:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 # 是否包含售罄商品 4 try: 5 filter_stock = int(input("看全部商品请按0,只看有货请按1(默认看全部商品):")) 6 if filter_stock == 1: 7 filter_stock = 1 8 else: 9 filter_stock = 0 10 except: 11 filter_stock = 0
其他的价格排序和折扣排序也是这样子观察,最后得到:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 # 价格的排序方式 4 sort = input("综合排序请按0,价格升序请按1,降序请按2,折扣升序请按3,降序请按4(默认综合排序):") 5 try: 6 if sort == "1": 7 sort = "1" 8 elif sort == "2": 9 sort = "2" 10 elif sort == "3": 11 sort = "3" 12 elif sort == "4": 13 sort = "4" 14 else: 15 sort = "0" 16 except: 17 sort = "0"
翻页筛选搞定,下面看不同店铺之间哪里不一样,退到这个页面:

以此点开不同的专场,可以发现代表专场的post是这个:
brand-838319-0-0-0-1-0-1-20.html
其中838319是专场的id,在地址栏可以看得到的
而不同的商品种类的id也是不一样:
"id":1472638528843,
这个id暂时没有发现有什么规律,不过按照道理来说唯品会的商品类目也就那么几十种,做个穷举就行了。
最终的postdata构造完毕:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 postdata = {"method": "getGoodsList", 4 "params": { 5 "page": brandid, 6 "np": numbers, 7 "ep": 20, 8 "cat_id": "0", 9 "sort": sort, 10 "filter_stock": filter_stock, 11 "filter_size": "0", 12 "show": 0, 13 "query": ""}, 14 "id": 1472634230417, 15 "jsonrpc": "2.0"}
构造网址:
url = "http://m.vip.com/server.html"
上面为思路,搞定,下面是代码。
-----------------------------我是快乐的分割线--------------------------------
如果看过:
python3抓取异步百度瀑布流动态图片(二)get、json下载代码讲解
你就会知道这个也是要用上面解析头:
1 def postget(url, postdata): 2 # 制作头部 3 header = { 4 'User-Agent': 'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5', 5 'Referer': 'http://m.vip.com/', 6 'Host': 'm.vip.com', 7 'Accept': 'application/json', 8 'Accept-Encoding': 'gzip, deflate', 9 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 10 'Connection': 'keep-alive', 11 'Content-Type': 'application/json' 12 } 13 # post参数 14 res = requests.post(url=url, headers=header, json=postdata) 15 # ('UTF-8')('unicode_escape')('gbk','ignore') 16 resdata = res.content 17 return resdata
利用这个解析头将解析出来的东西保存为json:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 # 解析得到json 4 data = postget(url, postdata) 5 # 将抓到的储存到json里面 6 savepath = r"../json/" 7 file = open(savepath + str(numbers) + '.json', 'wb') 8 file.write(data) 9 file.close()
读取json,并采集自己需要的东西:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 # 读取json 4 checkpath = r"../json/" 5 files = listfiles(checkpath, '.json') 6 for filename in files: 7 try: 8 doc = open(filename, 'rb') 9 doccontent = doccontent = doc.read().decode('unicode_escape', 'ignore') 10 doccontent = doccontent.replace(' ', '').replace(' ', '').replace('<spanclass="salebg2">0.8</span>折起', '') 11 except Exception as err: 12 print(err) 13 pass 14 15 jsondata = json.loads(doccontent) 16 # 里面的格式为 17 # [{"method":"getClassifyList","result":{"products":[ 18 for item in jsondata: 19 onefile = item['result'] 20 21 towfile = onefile["products"] 22 for item in towfile: 23 # 共有的项目是专场id、专场名字 24 itemlist = [item["brand_id"], item["brand_name"]] 25 # 货号 26 itemlist.append(item['merchandise_sn']) 27 # 商品id 28 itemlist.append(item['product_id']) 29 # 商品名字 30 itemlist.append(item['product_name']) 31 # 图片网址 32 itemlist.append(item['small_image']) 33 # 卖价 34 itemlist.append(item['vipshop_price']) 35 # 折扣 36 itemlist.append(item['discount']) 37 # 吊牌价 38 itemlist.append(item['market_price']) 39 # sku_id 40 itemlist.append(item['sku_id']) 41 # spu_id 42 itemlist.append(item['v_spu_id'])
将其写入excel:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 4 # 创建一个Excel文件 5 workbook = xlsxwriter.Workbook('../excel/' + today + '.xlsx') 6 # 创建一个工作表 7 worksheet = workbook.add_worksheet() 8 # 记录第一行 9 first = ['商品种类id', '品牌名字', '专场id', '专场名字', '商品id', '商品名字', '图片网址', '卖价', '折扣', '吊牌价', 'sku_id', '优惠'] 10 # 写入excel的行数 11 num = 1 12 13 # 写入第一行 14 for m in range(0, len(first)): 15 worksheet.write(0, m, first[m]) 16 try: 17 worksheet.write(num, m, itemlist[m]) 18 except Exception as err: 19 worksheet.write(num, m, "") 20 print(err) 21 num = num + 1
顺便下载点图片:
1 # !/usr/bin/python3.4 2 # -*- coding: utf-8 -*- 3 4 pic = urllib.request.urlopen(item['small_image']) 5 picno = time.strftime('%H%M%S', time.localtime()) 6 filenamep = "../image/" + picno + '-' + validateTitle(item["merchandise_sn"] + '-' + item['product_name']) 7 filenamepp = filenamep + '.jpg' 8 filess = open(filenamepp, 'wb') 9 filess.write(pic.read()) 10 filess.close() 11 print("下载图片" + str(item['small_image'])) 12 time.sleep(1)
全部搞定,效果图:
