前面我们已经学习了单细胞转录组分析的:使用Cell Ranger得到表达矩阵和doublet检测,今天我们开始Seurat标准流程的学习。这一部分的内容,网上有很多帖子,基本上都是把Seurat官网PBMC的例子重复一遍,这回我换一个数据集,细胞类型更多,同时也会加入一些实际分析中很有用的技巧。
1. 导入数据,创建Seurat对象
library(Seurat)
library(tidyverse)
testdf=read.table("test_20210105.txt",header = T,row.names = 1)
test.seu=CreateSeuratObject(counts = testdf)
看一下长什么样子
> test.seu
An object of class Seurat
33538 features across 6746 samples within 1 assay
Active assay: RNA (33538 features)
#①1 assay表示有一套数据,假如用Seurat里面的函数去过批次效应,
#这里会有2个assay,另外一个是去批次(整合)之后的;
#②cell hashing的tag表达矩阵生成Seurat对象,这时的assay为"HTO",不叫"RNA";
#其他情况类似
测试数据有33538个基因,6746个细胞。除此之外,还要关注一下另外两层信息:test.seu@meta.data这个数据框用来存储元数据,每一个细胞都有多个属性;test.seu[["RNA"]]@counts这个稀疏矩阵用来存储原始UMI表达矩阵。
> head(test.seu@meta.data)
orig.ident nCount_RNA nFeature_RNA
A_AAACCCAAGGGTCACA A 3714 1151
A_AAACCCAAGTATAACG A 1855 816
A_AAACCCAGTCTCTCAC A 1530 823
A_AAACCCAGTGAGTCAG A 11145 1087
A_AAACCCAGTGGCACTC A 2289 834
A_AAACGAAAGCCAGAGT A 3714 990
#我这里CB的前面人为加上了样本来源,用下划线连接,orig.ident是自动识别得到的
> test.seu[["RNA"]]@counts[1:4,1:4]
4 x 4 sparse Matrix of class "dgCMatrix"
A_AAACCCAAGGGTCACA A_AAACCCAAGTATAACG A_AAACCCAGTCTCTCAC A_AAACCCAGTGAGTCAG
MIR1302-2HG . . . .
FAM138A . . . .
OR4F5 . . . .
AL627309.1 . . . .
2. 简单过滤
接下来,我们根据每个细胞内部线粒体基因表达占比、检测到的基因数、检测的UMI总数这三个方面来对细胞进行简单的过滤。
先计算细胞内线粒体基因表达占比,类似的核糖体基因(大多为RP开头)也能这样计算,还要注意不要将线粒体基因的MT-写成了MT,不然就把别的基因也算进去了:
test.seu[["percent.mt"]] <- PercentageFeatureSet(test.seu, pattern = "^MT-") #正则表达式,表示以MT-开头;test.seu[["percent.mt"]]这种写法会在meta.data矩阵加上一列
这里我已经根据预先设定好的阈值过滤了,代码如下
test.seu <- subset(test.seu, subset = nCount_RNA > 1000 &
nFeature_RNA < 5000 &
percent.mt < 30 &
nFeature_RNA > 600)
过滤之后的数值分布如下,用到VlnPlot()函数,该绘图函数里面的feature参数可以是meta.data矩阵的某一列,也可以是某一个基因,很多文章都用这种图展示marker gene
VlnPlot(test.seu,features = c("nCount_RNA", "nFeature_RNA", "percent.mt"),pt.size = 0)

nFeature_RNA/nCount_RNA不能太小(空液滴),不能太大(doublet、测序技术限制), 而且阈值设定要综合多个样本来看,像下面这样
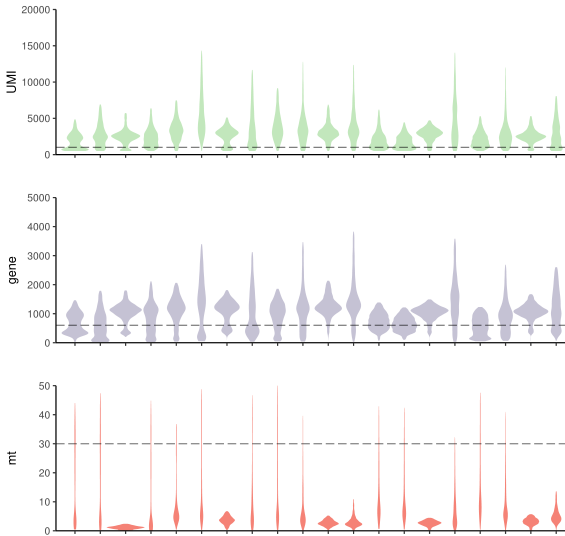
一般在CD45阴性的细胞中percent.mt的阈值大一些,50%也看过几次了
3. LogNormalize,消除文库大小的影响
如何标准化:LogNormalize: Feature counts for each cell are divided by the total counts for that cell and multiplied by the scale.factor. This is then natural-log transformed using log1p.(先相除,再求对数)
test.seu <- NormalizeData(test.seu, normalization.method = "LogNormalize", scale.factor = 10000)
标准化之后的矩阵存储在test.seu[["RNA"]]@data
> test.seu[["RNA"]]@data[1:4,1:4]
4 x 4 sparse Matrix of class "dgCMatrix"
A_AAACCCAAGGGTCACA A_AAACCCAAGTATAACG A_AAACCCAGTCTCTCAC A_AAACCCAGTGAGTCAG
MIR1302-2HG . . . .
FAM138A . . . .
OR4F5 . . . .
AL627309.1 . . . .
4. 找Variable基因
因为单细胞表达矩阵很稀疏(很多0),选high variable基因的目的可以找到包含信息最多的基因(很多基因的表达差不多都是0),同时极大提升软件运行速度
test.seu <- FindVariableFeatures(test.seu, selection.method = "vst", nfeatures = 2000)
这些基因存储在VariableFeatures(test.seu),有时候可能需要人为指定high variable基因,可以这样:
VariableFeatures(test.seu)="specific genes"
5. scale表达矩阵
(基于前面得到的data矩阵)
这一步之后,所有基因的表达值的分布就差不多了,不然表达值不在一个数量级,对后续降维聚类影响挺大。新的矩阵存储在test.seu[["RNA"]]@scale.data里面。
test.seu <- ScaleData(test.seu, features = rownames(test.seu))
默认只对上一步选出来的基因scale,这里调整为所有基因,是为了方便以后画热图(画热图一般会用scale之后的z-score)
6. 降维聚类
(基于前面得到的high variable基因的scale矩阵)
test.seu <- RunPCA(test.seu, npcs = 50, verbose = FALSE)
test.seu <- FindNeighbors(test.seu, dims = 1:30)
test.seu <- FindClusters(test.seu, resolution = 0.5)
test.seu <- RunUMAP(test.seu, dims = 1:30)
test.seu <- RunTSNE(test.seu, dims = 1:30)
Run开头的函数降维,Find开头的函数聚类,一般就这几步,相对固定。PCA将原来2000维的数据降到50维,dims参数表示使用多少个主成分(一般20左右就可以了,多几个少几个对结果影响不大),resolution参数表达聚类的分辨率,这个值大于0,一般都是在0-1范围里面调整,越大得到的cluster越多,这个值可以反复调整,并不会改变降维的结果(也就是tsne、umap图的二维坐标)。
这一步之后的数据是这样的
> test.seu
An object of class Seurat
33538 features across 6746 samples within 1 assay
Active assay: RNA (33538 features)
3 dimensional reductions calculated: pca, umap, tsne
# 几种降维方式都会呈现出来
聚类之后test.seu@meta.data多了两列,RNA_snn_res.0.5记录了你用的分辨率,最终的聚类结果保存在seurat_clusters中
> head(test.seu@meta.data)
orig.ident nCount_RNA nFeature_RNA percent.mt RNA_snn_res.0.5
A_AAACCCAAGGGTCACA A 3714 1151 9.585353 8
A_AAACCCAAGTATAACG A 1855 816 12.776280 0
A_AAACCCAGTCTCTCAC A 1530 823 14.248366 12
A_AAACCCAGTGAGTCAG A 11145 1087 2.853297 4
A_AAACCCAGTGGCACTC A 2289 834 15.640017 3
A_AAACGAAAGCCAGAGT A 3714 990 5.654281 0
seurat_clusters
A_AAACCCAAGGGTCACA 8
A_AAACCCAAGTATAACG 0
A_AAACCCAGTCTCTCAC 12
A_AAACCCAGTGAGTCAG 4
A_AAACCCAGTGGCACTC 3
A_AAACGAAAGCCAGAGT 0
7. tsne/umap展示结果
library(cowplot)
test.seu$patient=str_replace(test.seu$orig.ident,"_.*$","")
p1 <- DimPlot(test.seu, reduction = "tsne", group.by = "patient", pt.size=0.5)
p2 <- DimPlot(test.seu, reduction = "tsne", group.by = "ident", pt.size=0.5, label = TRUE,repel = TRUE) #后面两个参数用来添加文本标签
p3 <- DimPlot(test.seu, reduction = "umap", group.by = "patient", pt.size=0.5)
p4 <- DimPlot(test.seu, reduction = "umap", group.by = "ident", pt.size=0.5, label = TRUE,repel = TRUE)
fig_tsne <- plot_grid(p1, p2, labels = c('patient','ident'),align = "v",ncol = 2)
ggsave(filename = "tsne.pdf", plot = fig_tsne, device = 'pdf', width = 30, height = 15, units = 'cm')
fig_umap <- plot_grid(p3, p4, labels = c('patient','ident'),align = "v",ncol = 2)
ggsave(filename = "umap.pdf", plot = fig_umap, device = 'pdf', width = 30, height = 15, units = 'cm')
ident表示每个细胞的标签,聚类之后就是聚类的结果,在一些特定场景可以更换。
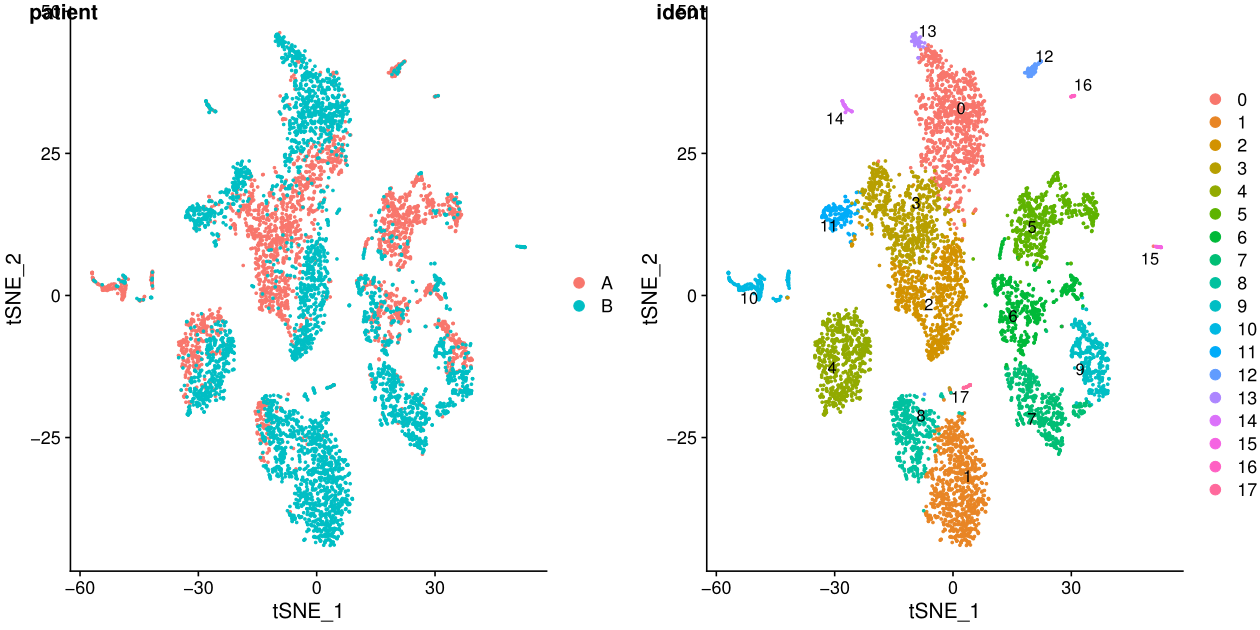
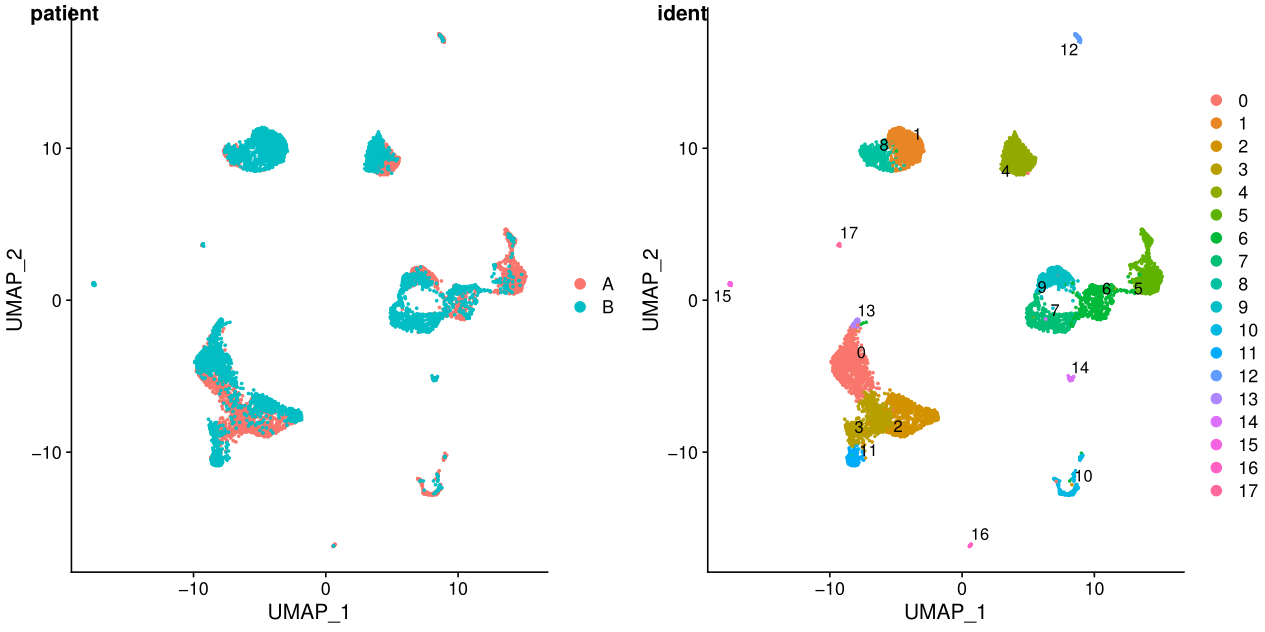
在umap图中,cluster之间的距离更明显
从上面的图可以看出不同样本其实是有批次效应的,下一讲我会介绍两种去批次效应的方法。
因水平有限,有错误的地方,欢迎批评指正!