#coding=utf8 import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from xgboost import XGBClassifier titanic = pd.read_csv('./DataSets/Titanic/train.csv') X = titanic[['Pclass', 'Age', 'Sex']] y = titanic['Survived']
X['Age'].fillna(X['Age'].mean(), inplace=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33) vec = DictVectorizer(separator=False) X_train = vec.fit_transform(X_train.to_dict(orient='record')) #print X_train.to_dict(orient='record') X_test = vec.transform(X_test.to_dict(orient='record')) xgbc = XGBClassifier() xgbc.fit(X_train, y_train) print 'The accuracy of eXtreme Gradient Boosting Classifier on testing set:', xgbc.score(X_test, y_test)

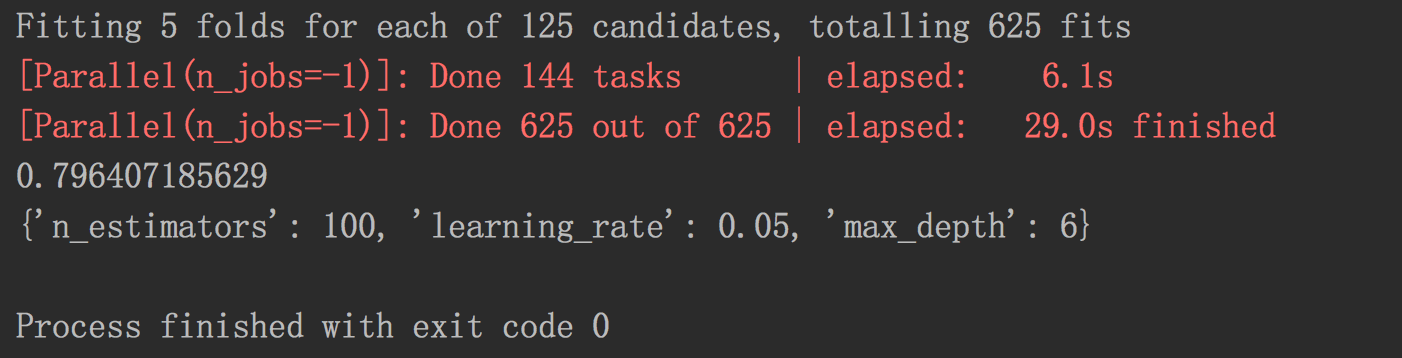
#coding=utf8 import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV titanic = pd.read_csv('./DataSets/Titanic/train.csv') X = titanic[['Pclass', 'Age', 'Sex']] y = titanic['Survived'] X['Age'].fillna(X['Age'].mean(), inplace=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33) vec = DictVectorizer(separator=False) X_train = vec.fit_transform(X_train.to_dict(orient='record')) #print X_train.to_dict(orient='record') X_test = vec.transform(X_test.to_dict(orient='record')) xgbc = XGBClassifier() params = {'max_depth':range(2, 7), 'n_estimators':range(100, 1100, 200), 'learning_rate':[0.05, 0.1, 0.25, 0.5, 1.0]} gs = GridSearchCV(xgbc, params, n_jobs=-1, cv=5, verbose=1) gs.fit(X_train, y_train) #print 'The accuracy of eXtreme Gradient Boosting Classifier on testing set:', gs.score(X_test, y_test) print gs.best_score_ print gs.best_params_