#coding=utf8 # 导入numpy工具包。 import numpy as np # 导入pandas用于数据分析。 import pandas as pd from sklearn.metrics import classification_report # 从sklearn.decomposition导入PCA。 from sklearn.decomposition import PCA # 从互联网读入手写体图片识别任务的训练数据,存储在变量digits_train中。 digits_train = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tra', header=None) # 从互联网读入手写体图片识别任务的测试数据,存储在变量digits_test中。 digits_test = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tes', header=None) # 对训练数据、测试数据进行特征向量(图片像素)与分类目标的分隔。 X_train = digits_train[np.arange(64)] y_train = digits_train[64] X_test = digits_test[np.arange(64)] y_test = digits_test[64] # 导入基于线性核的支持向量机分类器。 from sklearn.svm import LinearSVC # 使用默认配置初始化LinearSVC,对原始64维像素特征的训练数据进行建模,并在测试数据上做出预测,存储在y_predict中。 svc = LinearSVC() svc.fit(X_train, y_train) y_predict = svc.predict(X_test) # 使用PCA将原64维的图像数据压缩到20个维度。 estimator = PCA(n_components=20) # 利用训练特征决定(fit)20个正交维度的方向,并转化(transform)原训练特征。 pca_X_train = estimator.fit_transform(X_train) # 测试特征也按照上述的20个正交维度方向进行转化(transform)。 pca_X_test = estimator.transform(X_test) # 使用默认配置初始化LinearSVC,对压缩过后的20维特征的训练数据进行建模,并在测试数据上做出预测,存储在pca_y_predict中。 pca_svc = LinearSVC() pca_svc.fit(pca_X_train, y_train) pca_y_predict = pca_svc.predict(pca_X_test) # 对使用原始图像高维像素特征训练的支持向量机分类器的性能作出评估。 print svc.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=np.arange(10).astype(str)) # 对使用PCA压缩重建的低维图像特征训练的支持向量机分类器的性能作出评估。 print pca_svc.score(pca_X_test, y_test) print classification_report(y_test, pca_y_predict, target_names=np.arange(10).astype(str))
结果:
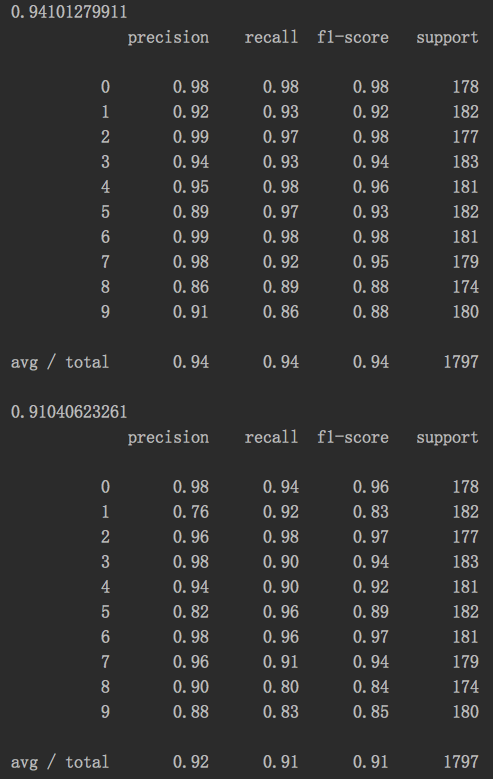
分析:虽然损失了%3的预测准确性,但是相比于原来的64维特征,使用PCA压缩并降低了68.75%的维度,能改节省大量的训练时间,在保持数据多样性的基础上,规避掉了大量特征冗余和噪声。