框架介绍
文件分类
- 核心部分: 引擎、下载器、调度器
- 自定义部分: spider(自己建的爬虫文件)、管道(pipelines.py)
目录结构
firstSpider firstSpider spiders # 爬虫目录(写代码位置)负责存放继承自scrapy的爬虫类 __init__.py budejie.py # 自己建的爬虫文件,以后的爬虫代码写在这里 __init__.py items.py # 定义数据结构地方,负责数据模型的建立,类似于实体类 middlewares.py # 自己定义中间件地方(了解) pipelines.py # 管道文件,负责对spider返回数据的处理 settings.py # 项目配置文件,负责对整个爬虫的配置 scrapy.cfg # 基础配置
文件功能
- spiders/budejie.py代码分析:spiders目录下的budejie.py为主要的爬虫代码,包括了对页面的请求以及页面的处理
需要注意:
爬取页面时,返回的是这个页面的信息,但是这时候需要的是获取每个文章的地址继续访问,
就要用到了yield Request()这种用法,可以把获取到文章的url地址继续传递进来再次进行请求。
scrapy提供了response.css这种的css选择器以及response.xpath的xpath选择器方法,我们可以根据自己的需求获取我们想要的字段信息
- items.py代码分析:items.py里存放的是我们要爬取数据的字段信息
- pipelines.py代码分析:pipeline主要是对spiders中爬虫的返回的数据的处理,可以让写入到数据库,也可以让写入到文件。可以定义各种我们需要的pipeline,不同的pipeline是有一定的顺序的,需要的设置是在settings配置文件中,后面的数字表示的是优先级,数字越小优先级越高。
- settings.py代码分析:项目配置文件,负责对整个爬虫的配置


class ArticleSpider(scrapy.Spider): name = "Article" allowed_domains = ["blog.jobbole.com"] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): ''' 1.获取文章列表也中具体文章url,并交给scrapy进行下载后并进行解析 2.获取下一页的url并交给scrapy进行下载,下载完成后,交给parse :param response: :return: ''' #解析列表页中所有文章的url,并交给scrapy下载后进行解析 post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: #image_url是图片的地址 image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") #这里通过meta参数将图片的url传递进来,这里用parse.urljoin的好处是如果有域名我前面的response.url不生效 # 如果没有就会把response.url和post_url做拼接 yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":parse.urljoin(response.url,image_url)},callback=self.parse_detail) #提取下一页并交给scrapy下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=next_url,callback=self.parse) def parse_detail(self,response): ''' 获取文章的详细内容 :param response: :return: ''' article_item = JoBoleArticleItem() front_image_url = response.meta.get("front_image_url","") #文章封面图地址 title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first() create_date = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].strip().split()[0] tag_list = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/a/text()').extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tag =",".join(tag_list) praise_nums = response.xpath('//span[contains(@class,"vote-post-up")]/h10/text()').extract() if len(praise_nums) == 0: praise_nums = 0 else: praise_nums = int(praise_nums[0]) fav_nums = response.xpath('//span[contains(@class,"bookmark-btn")]/text()').extract()[0] match_re = re.match(".*(d+).*",fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums =response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] match_com = re.match(".*(d+).*",comment_nums) if match_com: comment_nums = int(match_com.group(1)) else: comment_nums=0 content = response.xpath('//div[@class="entry"]').extract()[0] article_item["url_object_id"] = get_md5(response.url) #这里对地址进行了md5变成定长 article_item["title"] = title article_item["url"] = response.url try: create_date = datetime.datetime.strptime(create_date,'%Y/%m/%d').date() except Exception as e: create_date = datetime.datetime.now().date() article_item["create_date"] = create_date article_item["front_image_url"] = [front_image_url] article_item["praise_nums"] = int(praise_nums) article_item["fav_nums"] = fav_nums article_item["comment_nums"] = comment_nums article_item["tag"] = tag article_item['content'] = content yield article_item
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for MyFristScrapy project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://docs.scrapy.org/en/latest/topics/settings.html 9 # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://docs.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'MyFristScrapy' # 爬虫项目名字 13 14 SPIDER_MODULES = ['MyFristScrapy.spiders'] # 爬虫的模版 15 16 NEWSPIDER_MODULE = 'MyFristScrapy.spiders' # 新爬虫模版 17 18 19 #通过在用户代理上标识您自己(和您的网站),负责任地爬行 # 设置user_agent 20 #USER_AGENT = 'MyFristScrapy (+http://www.yourdomain.com)' 21 22 # Obey robots.txt rules # robots协议是否遵守 23 ROBOTSTXT_OBEY = True 24 25 # 配置由Scrapy执行的最大并发请求(默认值:16). # 链接数量 26 #CONCURRENT_REQUESTS = 32 27 28 #为同一网站的请求配置延迟(默认值:0) # 下载时延 29 #见https://docs.scrapy.org/en/latest/topics/settings.html # download-delay 30 #参见自动油门设置和文档 31 #DOWNLOAD_DELAY = 3 32 33 # 下载延迟设定只适用于以下其中一项: 34 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 35 #CONCURRENT_REQUESTS_PER_IP = 16 36 37 # 禁用cookie(默认启用) 38 #COOKIES_ENABLED = False 39 40 # 禁用Telnet控制台(默认启用) 41 #TELNETCONSOLE_ENABLED = False 42 43 # 覆盖默认的请求头: 44 #DEFAULT_REQUEST_HEADERS = { 45 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 46 # 'Accept-Language': 'en', 47 #} 48 49 # 启用或禁用爬行器中间件 50 # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html 51 #SPIDER_MIDDLEWARES = { 52 # 'MyFristScrapy.middlewares.MyfristscrapySpiderMiddleware': 543, 53 #} 54 55 # 启用或禁用下载器中间件 56 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 57 #DOWNLOADER_MIDDLEWARES = { 58 # 'MyFristScrapy.middlewares.MyfristscrapyDownloaderMiddleware': 543, 59 #} 60 61 # 启用或禁用扩展 62 # See https://docs.scrapy.org/en/latest/topics/extensions.html 63 #EXTENSIONS = { 64 # 'scrapy.extensions.telnet.TelnetConsole': None, 65 #} 66 67 # Configure item pipelines 配置项管道 68 # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html 69 #ITEM_PIPELINES = { 70 # 'MyFristScrapy.pipelines.MyfristscrapyPipeline': 300, 71 #} 72 73 # Enable and configure the AutoThrottle extension (disabled by default) 74 # 启用和配置自动油门扩展(默认情况下禁用) 75 # See https://docs.scrapy.org/en/latest/topics/autothrottle.html 76 #AUTOTHROTTLE_ENABLED = True 77 # The initial download delay 初始下载延迟 78 #AUTOTHROTTLE_START_DELAY = 5 79 # The maximum download delay to be set in case of high latencies 80 # 在高延迟情况下设置的最大下载延迟 81 #AUTOTHROTTLE_MAX_DELAY = 60 82 # The average number of requests Scrapy should be sending in parallel to 83 # each remote server 84 # 应该并行发送的平均请求数 85 # 每个远程服务器 86 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 87 # Enable showing throttling stats for every response received: 88 # 启用显示节流统计为每个收到的响应: 89 #AUTOTHROTTLE_DEBUG = False 90 91 # Enable and configure HTTP caching (disabled by default) 92 # 启用和配置HTTP缓存(默认情况下禁用) 93 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 94 #HTTPCACHE_ENABLED = True 95 #HTTPCACHE_EXPIRATION_SECS = 0 96 #HTTPCACHE_DIR = 'httpcache' 97 #HTTPCACHE_IGNORE_HTTP_CODES = [] 98 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
- middlewares.py中代码分析:自己定义中间件地方
引擎驱动过程
在 pycharm 中的 Terminal 中启动驱动 : scrape crawl budejie
以下步骤完成后,准备工作就做完了。spider开启
1 键入scrapy crawl xxx,驱动scrapy的引擎开始工作
2 引擎开启,然后加载scrapy底层的依赖包与依赖程序(如:lxml、twisted等),加载完以后,引擎就可以正常工作
3 引擎加载settings文件,从中读取settings中配置的组件信息,根据settings信息安排后面相关的工作
4 引擎加载扩展文件,进行功能的扩展等
5 加载当前开启的下载中间件
6 加载当前开启的爬虫中间件
7 加载管道组件
8 前7步都是准备阶段,准工作完成以后,这里开始根据命令中指定的爬虫名字xxx创建一个爬虫对象
9 引擎从爬虫对象的start_urls属性中提取出起始url,然后考察是否在allowed_domain中,如果在则将这个url放入到调度器的调度队列中,否则舍弃
10 调度器开始异步的对引擎放进来的url进行请求
(【注意】请求的时候调度器每出队一个url就会开启一个异步的高效的下载器,
下载器在下载的过程中会按照中间件的次序依次经过,
最后将一层层中间件以后的请求发个服务器)
11 当下载器下载完成一个url数据以后会回调爬虫对象中的parse这个方法,
并且将响应对象传递到response参数中(响应对象由下载器进入爬虫的过程会按照次序依次经过爬虫中间件)
12 爬虫对象接收到响应以后,解析并且把解析的数据返回(数据要可迭代)(如果在解析完一个数据以后还需要访问下一级页面,还需要在这里重新开启以下下载器)
13 如果管道开启,则每次迭代的数据会按照次序进入每一个管道,由管道进行后期的处理
14 所有的管道处理完成以后,爬虫就会被关闭掉,爬虫对象就会销毁,接着引擎就会关闭
Scrapy data flow(流程图)
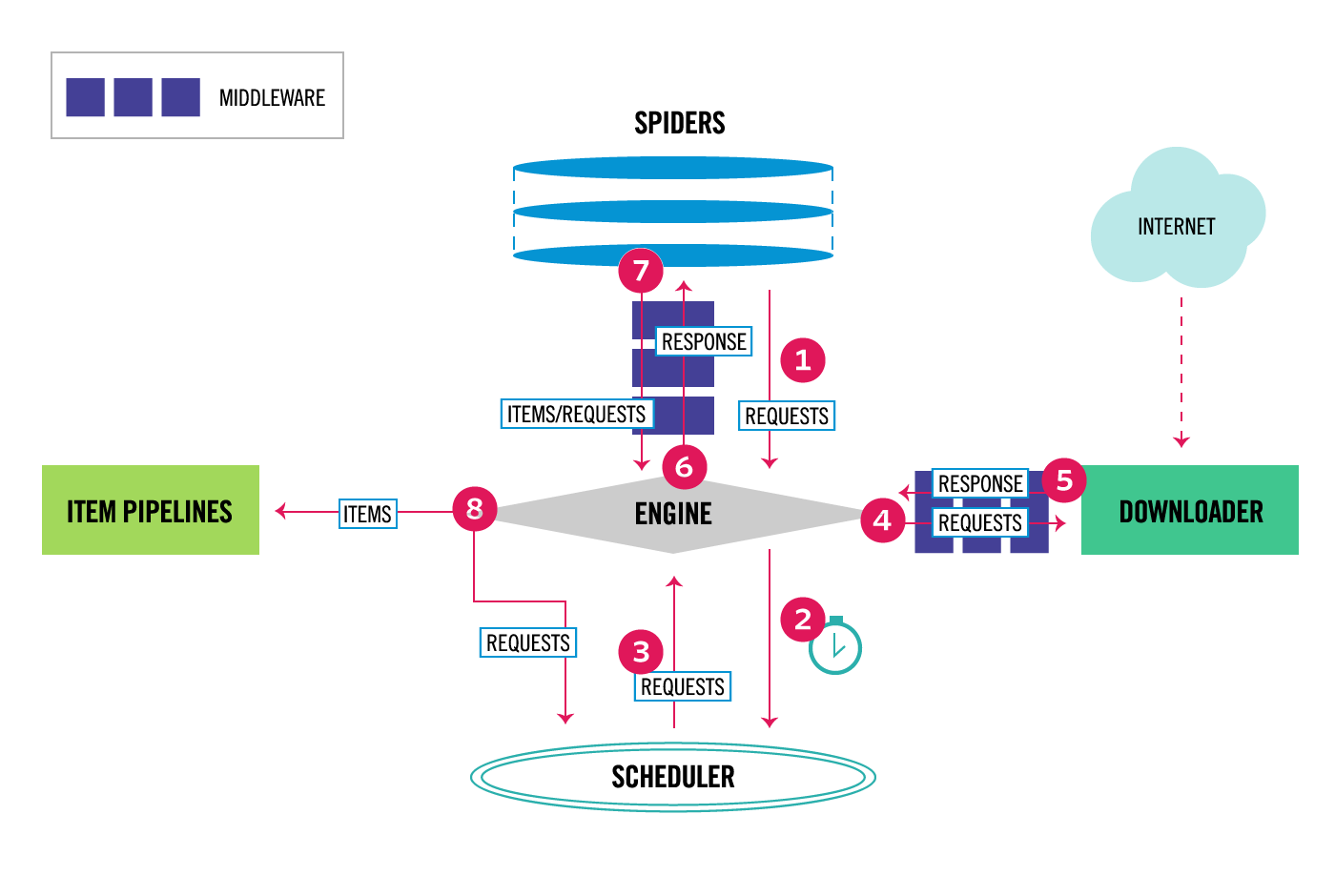
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍:
- 爬虫引擎(ENGINE) 爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
- 调度器(SCHEDULER) 调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
- 下载器(DOWNLOADER) 通过engine请求下载网络数据并将结果响应给engine。
- Spider Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
- 管道项目(item pipeline) 负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
- 下载中间件 下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
- spider中间件 spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
遗漏补充:
scrapy中的request中的meta可以将变量传到response中使用[源码分析知]。
req.meta['post'] = post ---> post = response.meta['post']
scrapy中的css解析是在源码中传变成xpath来进行解析的.
scrapy默认采用深度优先搜索去爬去数据
callback : 请求成功后 进行数据回调
errorback:请求出错后,进行数据回调
'//h3[contains(@class,"title")]/text()':h3属性中[contains]包含title字段