此次的目标是爬取网易云音乐上指定歌曲所有评论并生成词云
具体步骤:
一:实现JS加密
找到这个ajax接口没什么难度,问题在于传递的数据,是通过js加密得到的,因此需要查看js代码。
通过断掉调试可以找到数据是由core_8556f33641851a422ec534e33e6fa5a4.js?8556f33641851a422ec534e33e6fa5a4.js里的window.asrsea函数加密的。

通过进一步的查找,可以找到下面这个函数:
function() {
// 生成长度为16的随机字符串
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
// 实现AES加密
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
// 实现RSA加密
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
// 得到加密后的结果
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
}()
因此我们需要用Python实现上面四个函数。第一个生成随机字符串的函数没难度,实现的代码如下:
1 # 生成随机字符串 2 def generate_random_string(length): 3 string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" 4 # 初始化随机字符串 5 random_string = "" 6 # 生成一个长度为length的随机字符串 7 for i in range(length): 8 random_string += string[int(floor(random() * len(string)))] 9 return random_string
第二个是实现AES加密的函数,而用AES加密需要使用Crypto这个库。如果没有安装这个库的话,需要先安装pycrypto库,然后再安装Crypto库。在成功安装之后,如果import的时候没有Crypto而只有crypto,先打开Python安装目录下的Libsite-packagescrypto文件夹,如果里面有Cipher文件夹,就返回到Libsite-packages目录下把crypto重命名为Crypto,然后应该就可以成功导入了。
由于AES加密的明文长度必须是16的倍数,因此我们需要对明文进行必要的填充,以满足它的长度是16的倍数,AES加密的模式是AES.MODE_CBC,初始化向量iv='0102030405060708′。
实现AES加密的代码如下:
1 # AES加密 2 def aes_encrypt(msg, key): 3 # 如果不是16的倍数则进行填充 4 padding = 16 - len(msg) % 16 5 # 这里使用padding对应的单字符进行填充 6 msg += padding * chr(padding) 7 # 用来加密或者解密的初始向量(必须是16位) 8 iv = '0102030405060708' 9 # AES加密 10 cipher = AES.new(key, AES.MODE_CBC, iv) 11 # 加密后得到的是bytes类型的数据 12 encrypt_bytes = cipher.encrypt(msg) 13 # 使用Base64进行编码,返回byte字符串 14 encode_string = base64.b64encode(encrypt_bytes) 15 # 对byte字符串按utf-8进行解码 16 encrypt_text = encode_string.decode('utf-8') 17 # 返回结果 18 return encrypt_text
第三个是实现RSA加密的函数,在RSA加密中,明文和密文都是数字,RSA的密文是对代表明文的数字的E次方求mod N 的结果,RSA加密后得到的字符串长为256,这里不够长我们用x字符填充。
实现RSA加密的代码如下:
1 # RSA加密 2 def rsa_encrypt(random_string, key, f): 3 # 随机字符串逆序排列 4 string = random_string[::-1] 5 # 将随机字符串转换成byte类型数据 6 text = bytes(string, 'utf-8') 7 # RSA加密 8 sec_key = int(codecs.encode(text, encoding='hex'), 16) ** int(key, 16) % int(f, 16) 9 # 返回结果 10 return format(sec_key, 'x').zfill(256)
第四个函数是得到两个加密参数的函数,传入的四个参数,第一个参数JSON.stringify(i3x)是以下内容,其中offset和limit参数是必须要有的,offset的值是(页数-1)*20,limit的值是20
'{"offset":'+str(offset)+',"total":"True","limit":"20","csrf_token":""}'
第二个参数,第三个参数和第四个参数的值都是根据Zj4n.emj得到的:

encText的值是通过两次AES加密得到的,encSecKey是通过RSA加密得到的,实现的具体代码如下:
1 # 获取参数 2 def get_params(page): 3 # 偏移量 4 offset = (page - 1) * 20 5 # offset和limit是必选参数,其他参数是可选的 6 msg = '{"offset":' + str(offset) + ',"total":"True","limit":"20","csrf_token":""}' 7 key = '0CoJUm6Qyw8W8jud' 8 f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a87' 9 '6aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9' 10 'd05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b' 11 '8e289dc6935b3ece0462db0a22b8e7' 12 e = '010001' 13 # 生成长度为16的随机字符串 14 i = generate_random_string(16) 15 # 第一次AES加密 16 enc_text = aes_encrypt(msg, key) 17 # 第二次AES加密之后得到params的值 18 encText = aes_encrypt(enc_text, i) 19 # RSA加密之后得到encSecKey的值 20 encSecKey = rsa_encrypt(i, e, f) 21 return encText, encSecKey
二、解析并保存评论
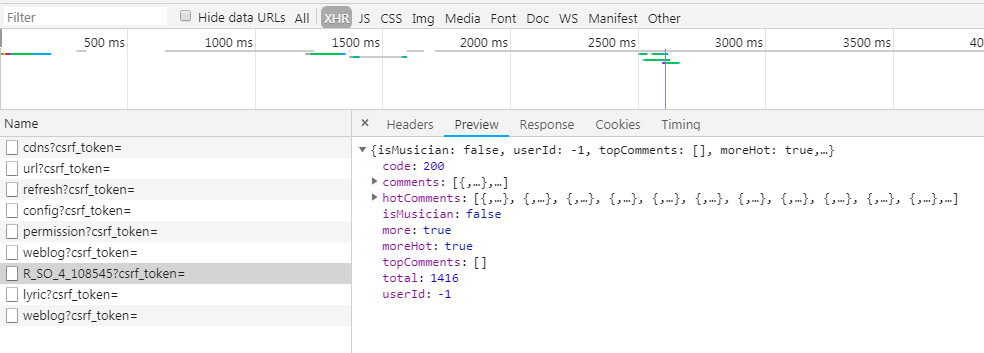
通过查看preview的信息可以发现用户名和评论内容都是保存在json格式的数据里的

因此解析起来会很容易,直接提取nickname和content就好了。对于得到的数据,都保存在以歌名为文件名的txt文件中。实现的代码如下:
1 # 爬取评论内容 2 def get_comments(data): 3 # data=[song_id,song_name,page_num] 4 url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(data[0]) + '?csrf_token=' 5 # 得到两个加密参数 6 text, key = get_params(data[2]) 7 # 发送post请求 8 res = requests.post(url, headers=headers, data={"params": text, "encSecKey": key}) 9 if res.status_code == 200: 10 print("正在爬取第{}页的评论".format(data[2])) 11 # 解析 12 comments = res.json()['comments'] 13 # 存储 14 with open(data[1] + '.txt', 'a', encoding="utf-8") as f: 15 for i in comments: 16 f.write(i['content'] + " ") 17 else: 18 print("爬取失败!")
三、生成词云
在进行这一步之前,需要先安装好jieba和wordcloud两个模块,jieba模块是一个用于中文分词的模块,wordcloud模块是一个用于生成词云的模块,可以自行了解学习。
这部分就不赘述了,具体代码如下:
1 # 生成词云 2 def make_cloud(txt_name): 3 with open(txt_name + ".txt", 'r', encoding="utf-8") as f: 4 txt = f.read() 5 # 结巴分词 6 text = ''.join(jieba.cut(txt)) 7 # 定义一个词云 8 wc = WordCloud( 9 font_path="font.ttf", 10 width=1200, 11 height=800, 12 max_words=100, 13 max_font_size=200, 14 min_font_size=10 15 ) 16 # 生成词云 17 wc.generate(text) 18 # 保存为图片 19 wc.to_file(txt_name + ".png")
最后生成的词云如下:

完整代码已经上传到GitHub!