一、队列的概念
1.基本概念
队列(queue)又被称为队,也是一种保存数据元素的容器。队列时一种特殊的线性表,只允许在表的前端(front)进行删除操作,只允许在表的后端(rear)进行插入操作,进行删除操作的一端叫做对头,进行插入操作的一端称为队尾。
队列按照先进先出的原则(FIFO,First In First Out)存储数据,先存入的元素会先被取出来使用。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。
2.抽象数据描述
队列的基本操作和栈是类似的,只不过操作名称有些许不一样,下面是一个基本队列的抽象数据描述:
ADT Queue:
Queue(self) # 创建一个空队列
is_empty(self) # 判断队列是否为空
enqueue(self, elem) # 入队,向队列中插入一个元素
dequeue(self) # 出队,从队列中删除一个元素
peek(self) # 查看对头位置的元素
3.用 Python 实现
1 # 自定义队列
2 class MyQueue:
3 def __init__(self):
4 self.data = []
5
6 def is_empty(self):
7 return len(self.data) == 0
8
9 def enqueue(self, elem):
10 self.data.append(elem)
11
12 def dequeue(self):
13 if self.data:
14 ret, self.data = self.data[0], self.data[1:]
15 return ret
16 return None
17
18 def peek(self):
19 return self.data[0] if self.data else None
二、队列
1.顺序队列
顺序队列是队列的顺序存储结构,顺序队列实际上是运算受限的顺序表。和顺序表一样,顺序队列使用一个向量空间来存放当前队列中的元素。由于队列的队头和队尾的位置是变化的,设置两个指针front和rear分别指示队头元素和队尾元素的位置,它们的初值在初始化时都置为0。
2.循环队列
循环队列将向量空间想象为一个首尾相接的回环,在循环队列中,由于入队时队尾指针向前追赶队头指针,出队时队头指针追赶队尾指针,因而队空和队满时头尾指针均相等。
3.双端队列
双端队列是一种具有队列和栈的性质的数据结构。双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行。双端队列是限定插入和删除操作在表的两端进行的线性表。
4.优先级队列
在优先级队列中,会给每一个元素都分配一个数字用来标记其优先级,例如给其中最小的数字以最高的优先级,这样就可以在一个集合中访问优先级最高的元素并对其进行查找和删除操作了。
使用 Python 实现一个优先级队列,可以借助 Python 中的 heapq 模块来实现,heapq 是一个二叉堆的实现,其内部使用内置的 list 对象,对于列表中的每一个元素都满足 a[k] <= a[2 * k + 1] and a[k] <= a[2 * k + 2],因此其默认是一个最小堆,a[0] 是队列中最小的元素。下面是利用 heapq 模块实现的一个优先级队列代码示例:
1 # 自定义优先级队列
2 class PriorityQueue:
3 def __init__(self):
4 self.data = []
5 self.index = 0
6
7 def push(self, elem, priority):
8 """
9 入队,将元素插入到队列中
10 :param elem: 待插入元素
11 :param priority: 该元素的优先级
12 :return:
13 """
14 # priority 加上负号是因为 heapq 默认是最小堆
15 heapq.heappush(self.data, (-priority, self.index, elem))
16 self.index += 1
17
18 def pop(self):
19 """
20 出队,从队列中取出优先级最高的元素
21 :return:
22 """
23 return heapq.heappop(self.data)[-1]
24
25 def size(self):
26 """
27 获取队列中元素数量
28 :return:
29 """
30 return len(self.data)
31
32 def is_empty(self):
33 """
34 判断队列是否为空
35 :return:
36 """
37 return len(self.data) == 0
三、队列的应用
1.迷宫问题
1)问题描述
将一个迷宫映射成一个由0和1组成的二维矩阵,迷宫里的空位置用0来表示,障碍和边界用1来表示,最左上角为入口,最右下角为出口,求是否能从迷宫中走出来?
2)问题分析
首先在算法初始时,可行的位置用0标识,不可行的位置用1标识,但在搜索路径的过程中需要将已经走过的位置给标记上,这里可以用数字2来标记,在后面的搜索过程中碰到2也就不会重复搜索了。
当到达一个位置时,需要确定该位置的可行方向,而除了边界点,每个位置都有四个可行的方向需要探索,例如对于坐标点(i,j),其四个相邻位置如下图:
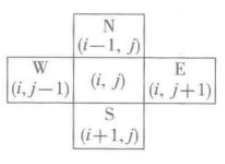
为了能够方便的计算相邻位置,可以用一个列表来记录:
DIR = [(0, 1), (1, 0), (0, -1), (-1, 0)]
对于任何一个位置(i,j),都可以分别加上 DIR[0]、DIR[1]、DIR[2]、DIR[3],就能得到相邻位置了。
为了使算法变得简单,这里可以先定义两个辅助用的函数,一个用于标记走过的点,一个用于判断输入的位置是否可以通行,具体代码如下:
1 def mark(maze, pos): 2 """ 3 将迷宫中已经走过的位置进行标记,设置为2 4 :param maze: 迷宫 5 :param pos: 位置 6 :return: 7 """ 8 maze[pos[0]][pos[1]] = 2 9 10 11 def passable(maze, pos): 12 """ 13 检车迷宫中指定位置是否能走 14 :param maze: 迷宫 15 :param pos: 位置 16 :return: 17 """ 18 if pos[0] < len(maze) and pos[1] < len(maze[0]): 19 return maze[pos[0]][pos[1]] == 0 20 return False
3)递归算法求解
在使用递归算法求解的过程中,对于每一个位置,都有如下的算法过程:
- 标记当前位置;
- 检查当前位置是否为出口,如果则表明找到路径,算法结束,不是则进行下一步;
- 遍历该位置的相邻位置,使用递归调用自身;
- 如果相邻位置都不可行,表明无法从迷宫中走出来,算法结束。
递归算法的核心函数代码如下:
1 def solution(maze, pos, end): 2 """ 3 递归算法的核心函数 4 :param maze: 迷宫,二维矩阵 5 :param pos: 当前位置 6 :param end: 出口 7 :return: 8 """ 9 mark(maze, pos) 10 if pos == end: 11 print(pos) 12 return True 13 for i in range(4): 14 next_pos = pos[0] + DIR[i][0], pos[1] + DIR[i][1] 15 if passable(maze, next_pos): 16 if solution(maze, next_pos, end): 17 print(pos) 18 return True 19 return False
4)使用队列求解
基于队列的求解算法还是使用之前的表示方法和辅助函数,但算法过程有变化。
首先将入口标记为已经到过并入队,然后当队列里还有未探索的位置时,取出一个位置并检查该位置的相邻位置,当相邻位置可行时,如果这个位置就是出口则结束算法,否则加入到队列中,当整个队列中的元素都被取出来后,队列为空,表示未找到从迷宫中走出来的路径,结束算法。使用队列求解迷宫问题的算法代码如下:
1 def queue_solution(maze): 2 """ 3 使用队列求解迷宫问题 4 :param maze: 迷宫,二维矩阵 5 :return: 6 """ 7 start, end = (0, 0), (len(maze) - 1, len(maze[0]) - 1) 8 q = MyQueue() 9 mark(maze, start) 10 q.enqueue(start) 11 while not q.is_empty(): 12 pos = q.dequeue() 13 for i in range(4): 14 next_pos = pos[0] + DIR[i][0], pos[1] + DIR[i][1] 15 if passable(maze, next_pos): 16 if next_pos == end: 17 print("Find Path!") 18 return True 19 mark(maze, next_pos) 20 q.enqueue(next_pos) 21 print("No Path!") 22 return False
2.生产者消费者模式
所谓生产者消费者模式,简而言之就是两个线程,一个扮演生产者,负责产生数据,另一个扮演消费者,不断获取这些数据并进行处理。而只有生产者和消费者,还算不上生产者消费者模式,还需要有一个缓冲区位于两者之间,生产者把数据放入缓冲区,消费者从缓冲区中取出数据。使用生产者消费者模式有几个好处:解耦,支持并发等。
在编写爬虫爬取数据时,就可以使用该模式,一个模块不断获取 URL,另一个模块就负责发送请求和解析数据,而在其中就可以使用队列作为缓冲区,将待爬取的 URL 都存放在这个队列中,然后爬取模块再从中取出 URL 进行爬取,直至队列为空。这里可以参考我以前写过的一篇博客:https://www.cnblogs.com/TM0831/p/10510319.html。