一、前言简述
因为最近微信读书出了网页版,加上自己也在闲暇的时候看了两本书,不禁好奇什么样的书更受欢迎,哪位作者又更受读者喜欢呢?话不多说,爬一下就能有个了解了。
二、页面分析
首先打开微信读书:https://weread.qq.com/,往下拉之后可以看到有榜单推荐,而且显示总共有25个榜单,有的榜单只有几百本,有的榜单却有几万本书。
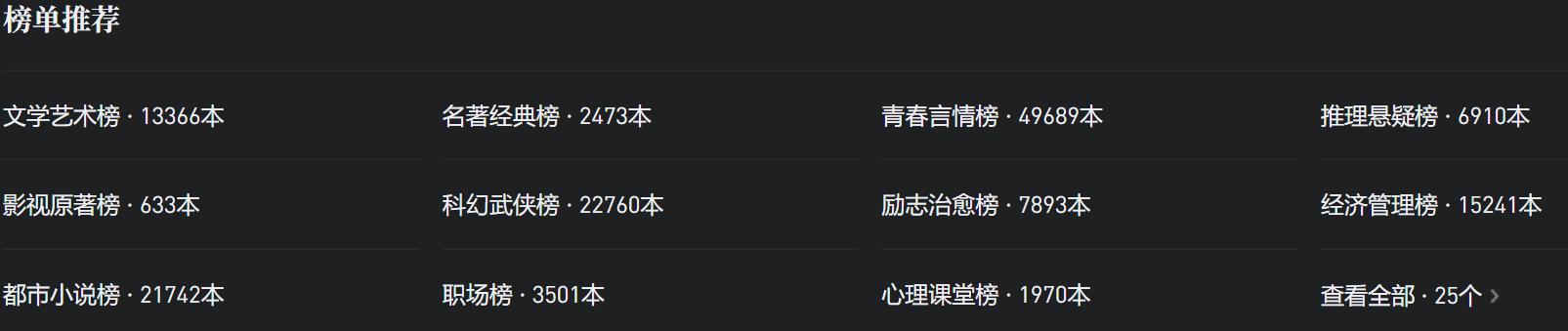
打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。

更关键的是,要获取这些书籍信息,只需要得到分类 ID 和参数 maxIndex。不过测试发现,每个分类只会返回50个页面的内容,也就是最多一千条书本信息。那么,如果只有这25个类别的榜单,能得到的数据还是有点少的,所以要怎么得到更多的数据呢?
细心的人可以发现右侧还能选择类别!如下图:
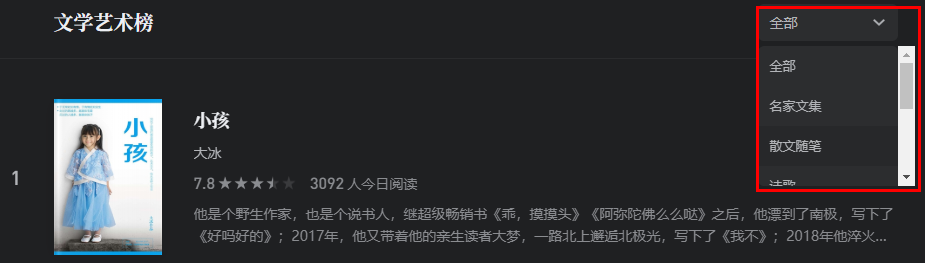
不过,查看这些元素发现里面是没有显示 URL 的,如下图:
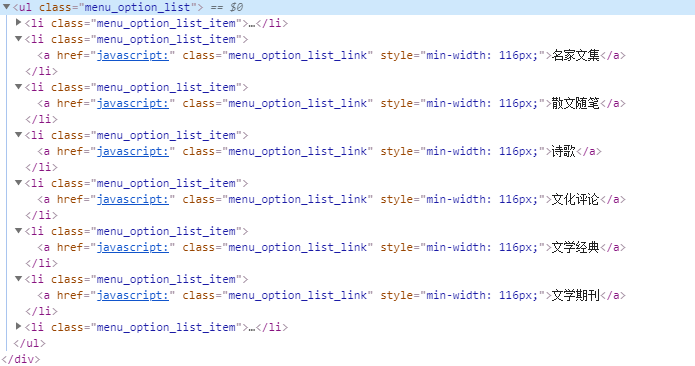
但是这也不表示没有办法了,全局搜索一下就能找到了,如下图:

CategoryId 就是这个分类的 ID,也就是 URL 中“bookListInCategory/”后面的内容。至于 maxIndex,可以先设为0,然后发送请求得到这一分类的书本总数“totalCount”,然后根据这个书本总数是否超过一千来设置页数,就能得到这一分类下能够爬取到的所有 URL 了。
三、爬取步骤
前面经过分析已经知道只要拿到书本分类 ID,就能发送请求得到书本总数,也就能构造该分类下的所有页面的 URL 了。那要怎么得到所有分类呢?前面全局搜索的时候已经搜到了书本分类的 CategoryId 等信息,如下图:
所以只需先请求页面然后用正则匹配 CategoryId 就行了!然后对每个分类发送一次请求,用于获取书本总数,并构造这一分类下的所有 URL。这一部分代码如下:
1 def prepare(base_url="https://weread.qq.com/web/category/1700000") -> list: 2 """ 3 prepare for crawler 4 :param base_url: weread base url 5 :return: page url list 6 """ 7 def request(url) -> list: 8 """ 9 request function 10 :param url: url 11 :return: page url list 12 """ 13 page_urls = [] 14 try: 15 res = requests.get(url=url, headers=headers) 16 if res.status_code == 200: 17 count = res.json()["totalCount"] 18 cnt = 50 if count >= 1000 else count // 20 19 page_urls = [url + "?maxIndex={}".format(i * 20) for i in range(cnt)] 20 else: 21 logging.error("Error request!") 22 except Exception as e: 23 logging.error(e) 24 finally: 25 return page_urls 26 27 resp = requests.get(url=base_url, headers=headers) 28 # check status code 29 if resp.status_code == 200: 30 id_list = re.findall('"CategoryId":"(.+?)"', resp.text) 31 id_list = list(set([i for i in id_list if i[0].isdigit()])) 32 href_list = ["https://weread.qq.com/web/bookListInCategory/{}".format(i) for i in id_list] 33 result = [] 34 for href in href_list: 35 result += request(href) 36 logging.info("Url count: {}".format(len(result))) 37 return result 38 else: 39 logging.error("Prepare error!") 40 exit()
进行到这一步,后面就很简单了,就是获取请求结果并解析即可。程序运行时打印输出如下:
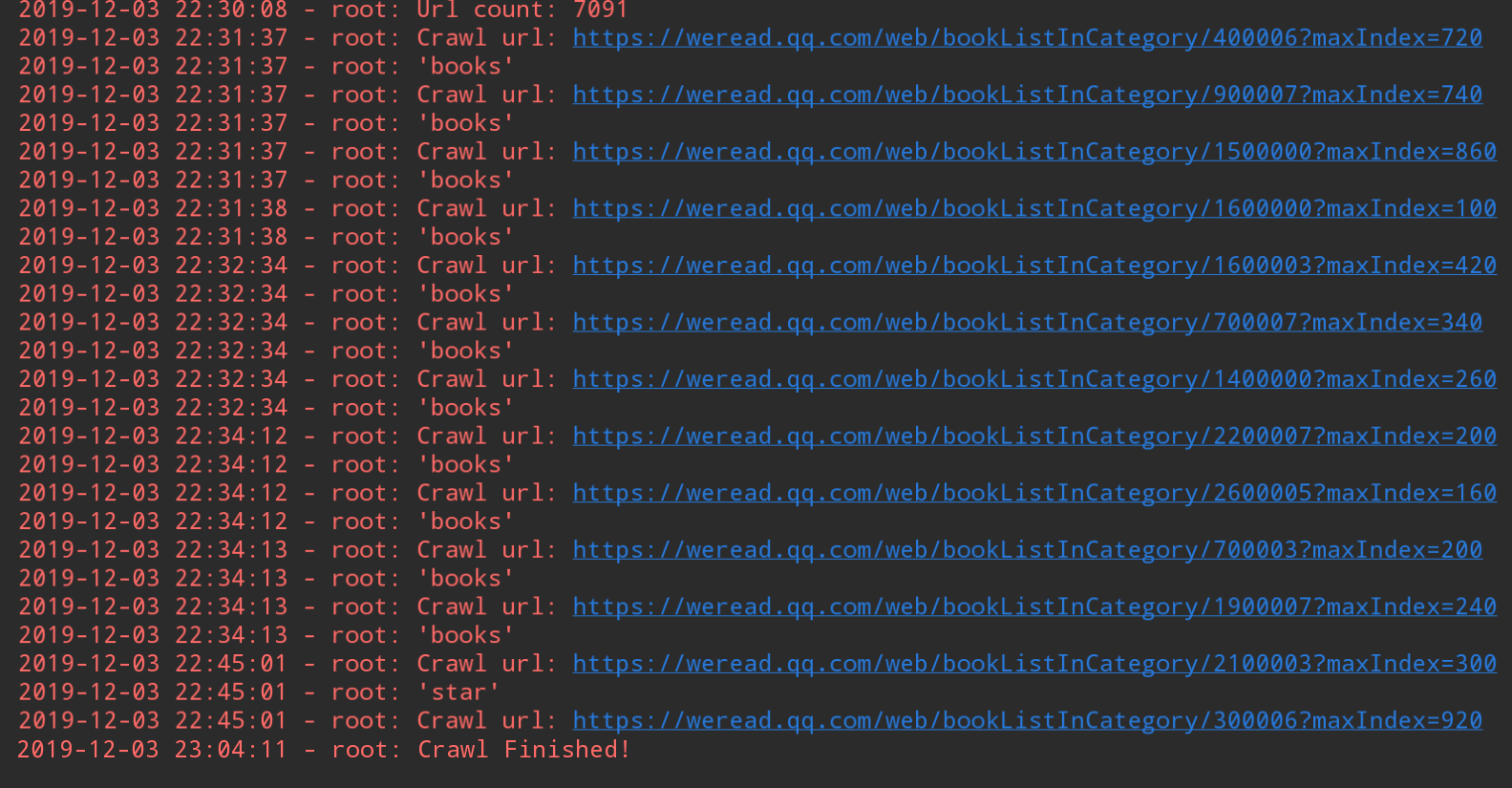
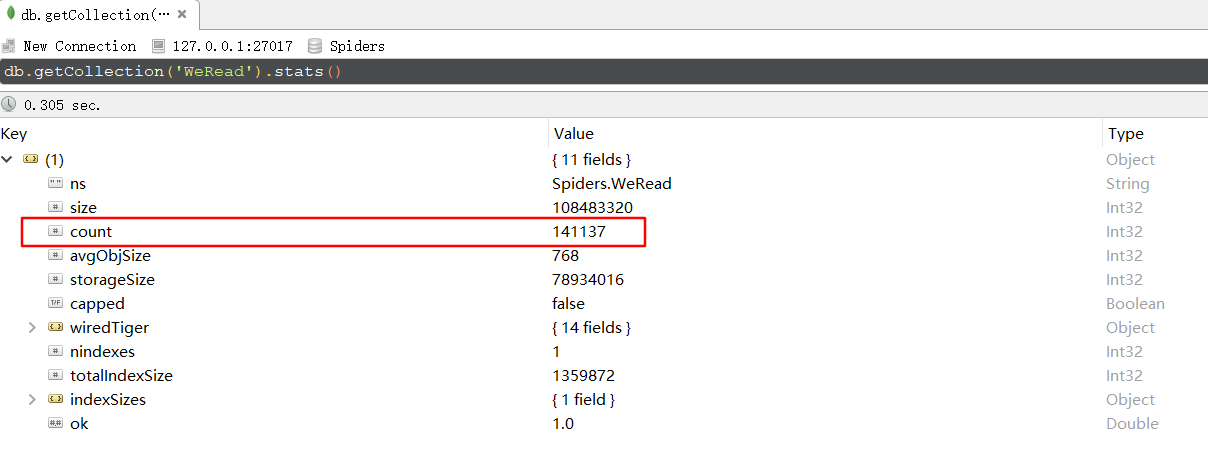
可以看到总链接数有7091条,那么爬到的书本信息有多少条呢?因为我用的是 MongoDB 保存的,所以打开 Robot3T 查看,总共有141137条,结果如下图:
四、绘图分析
熟悉 Python 的都知道,matplotlib 是 Python 中用的最多的 2D 图形绘图库。不过我在这推荐一个好用的第三方库:pyecharts,这是一个用于生成 Echarts 图表的类库,生成的图表更加精巧,可视化效果更好,不过需要注意的是 pyecharts 的0.5版本和1.0版本使用方法是不同的。下面就是使用这个库生成的横向柱状图了,分别表示评分前十的书籍、阅读量前十的书籍和总阅读量前十的作者:
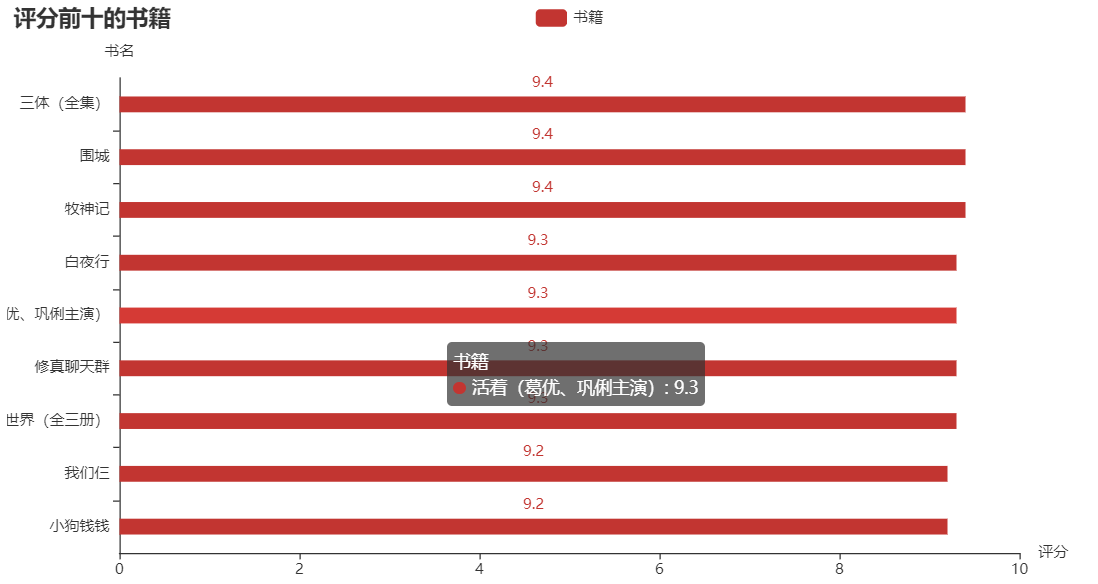
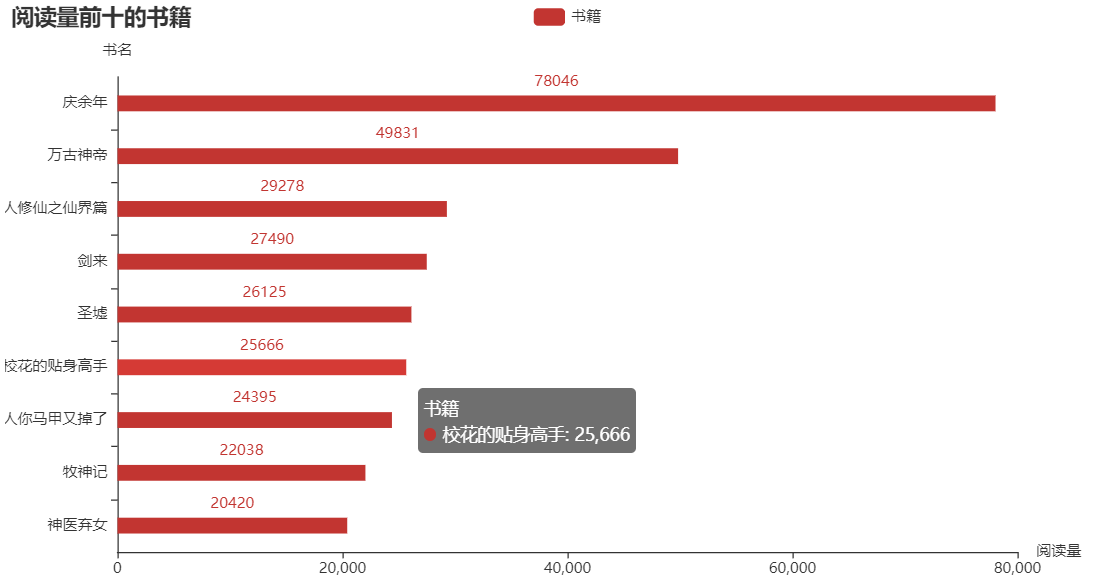
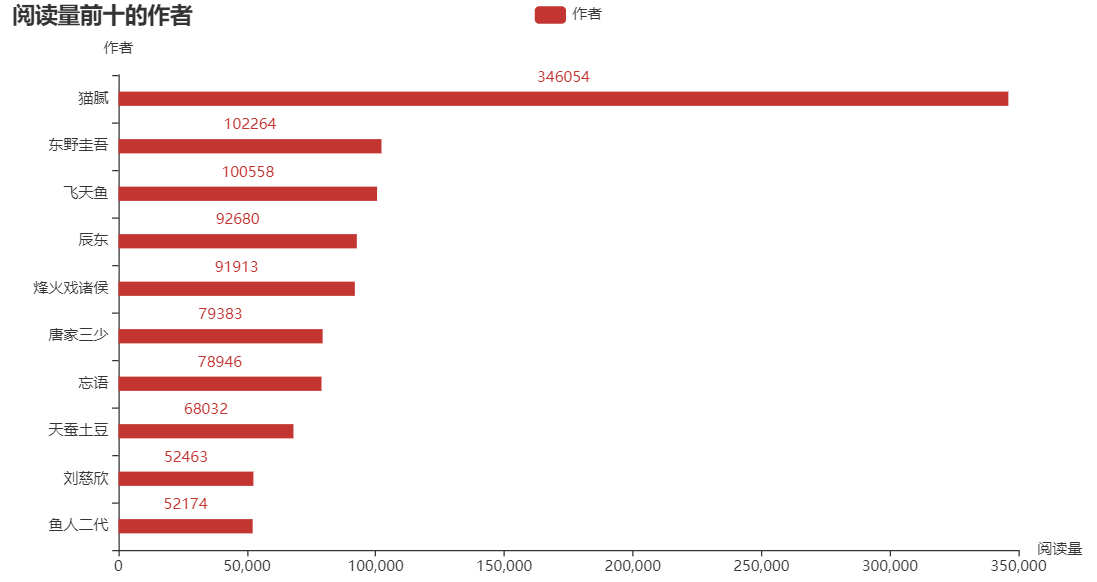
可以发现评分高的书籍阅读量却不一定高,阅读量更多的往往是一些网络小说。为什么好像现在名著都不怎么讨喜,而网络小说却能让更多人着迷呢?个人猜想是小说里的世界可能更加能够满足现在年轻人的幻想吧,现实生活疲惫不堪,就会更加迷恋小说中的“世外桃源”吧。
完整代码已上传到 GitHub!