本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称、推荐菜和评分信息。
一、页面分析
进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有15家店铺,而除了店铺的名称,还能看到店铺的地址、推荐菜、评分等信息,看起来都没什么问题。
打开开发者工具,然后选择查看一下评分,就发现事情没那么简单了(如下图)。这些评分的数字去哪儿了呢?
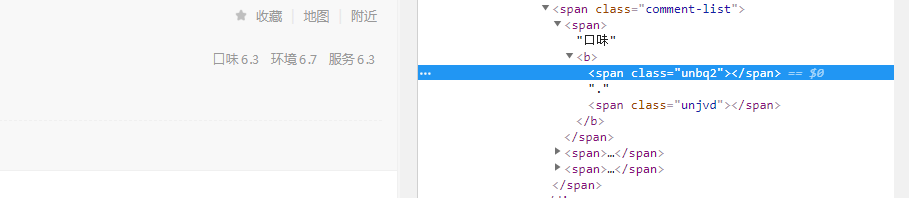
其实这些数字是SVG矢量图,SVG矢量图是基于可扩展标记语言,用于描述二维矢量图形的一种图形格式,通过使用不同的偏移量就能显示不同的字符,这样就能很巧妙地隐藏信息了,如果我们用xpath去解析网页得到的就是一个个""。这次爬虫的难点就在于如何得到这些评分的信息,既然我们能够知道它是怎么反爬的,那我们是不是就能想办法实现反反爬呢?先说下破解思路吧:首先要解析网页,找到这个网页使用的SVG矢量图,拿到这个矢量图后,如果我们能得到每个数字对应的偏移量,那就能将这些偏移量转化成图片中的数字了。
二、破解步骤
首先查看网页源码,既然使用的是SVG矢量图,那我们搜索一下svg会不会有惊喜呢?果然有惊喜:

把这个链接复制一下,然后打开这个链接,会看到有很多的class名称和background,这么多的数据,怎么知道有没有我们想要的东西呢?这时候搜索一下unbq2:

可以看到unbq2这个class对应的background为(-199.0px,-109.0px),但是我们还是没有办法得到具体的数字啊,怎么办呢?
我们再搜索一下svg会有什么结果呢?这一步会得到几个以.svg结尾的链接,将这些链接提取出来:
span[class^="ma"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/9e045e6574fb7ae10b5aae4ae4a0c444.svg);span[class^="yj"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39510b070120e6a5b7c8754ab729ee2e.svg);span[class^="dz"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/8eecf780b3c9ecefd5ad508502dd80a5.svg);span[class^="un"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39ecd4a57969825db02c38a01f4f34c6.svg);
可以看到以"un"开头的class使用的背景图片的链接就是//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39ecd4a57969825db02c38a01f4f34c6.svg

这就是我们要找的SVG矢量图了,现在的问题就在于如何将偏移量转化成对应的数字呢?首先把这些数字提取出来:
99851465728255648017534661485297040380627087820023
03763928255311814779807306445209731282368541175419
06266544999197136339
然后打开开发者工具,可以发现每个数字都有对应着一组x和y的值:

在前面的分析中我们知道数字6对应的偏移量是(-199.0px,-109.0px),然后我们也可以分析一下别的数字对应的偏移量,然后通过这些分析可以知道y方向上的偏移量只是为了确定这个class对应的数字在哪一行,而x方向的偏移量需要进行一下处理,具体方法为:
(x方向上的偏移量+7)/(-12)
比如(-199+7)/(-12)=16,这个16就表示对应的数字索引为16(第一个数字索引为0),然后y方向的偏移量对应的行数为3,最后从上面的数字中寻找第3行第17个数字--正好为6,也就是说unbq2这个class对应的数字就是6,这样我们就已经成功实现了反反爬。
三、爬取步骤
由于大众点评会对我们的UserAgent和Cookie进行检查,所以在爬取的时候要带上Cookie,而且如果一直用一个UserAgent也会被识别出来,所以得采用不同的UserAgent。这里我要分析一个第三方模块:fake_useragent,没有安装这个模块的可以使用pip命令进行安装。我们通过使用这个模块就能得到随机的UserAgent了,使用方法如下:
1 from fake_useragent import UserAgent
2
3 ua = UserAgent()
4 for i in range(3):
5 print(ua.random)
运行结果如下:

店铺名称和推荐菜的爬取相对简单,这里就不赘述了,主要说一下如何爬取店铺的评分信息。
在我们得到网页的源码之后,需要先把css文件的url提取出来:
# 提取css文件的url
css_url = "http:" + re.search('(//.+svgtextcss.+.css)', html).group()
然后将以"un"开头的class名称和对应的偏移量全部提取出来,以供后面使用:
css_res = requests.get(css_url)
# 这一步得到的列表内容为css中class的名字及其对应的偏移量
css_list = re.findall('(unw+){background:(.+)px (.+)px;', ' '.join(css_res.text.split('}')))
这里还要对得到的数据进行一下处理,因为y方向上的偏移量并不参与计算,最终得到的y_dict中的键是y方向上的偏移量,值是y方向上的偏移量对应的行数:
# 过滤掉匹配错误的内容,并对y方向上的偏移量初步处理
css_list = [[i[0], i[1], abs(float(i[2]))] for i in css_list if len(i[0]) == 5]
# y_list表示在y方向上的偏移量,完成排序和去重
y_list = [i[2] for i in css_list]
y_list = sorted(list(set(y_list)))
# 生成一个字典
y_dict = {y_list[i]: i for i in range(len(y_list))}
然后我们要提取以”un“开头的class所对应svg图片的url,并访问这个url,将图片中的数字都提取出来:
# 提取svg图片的url
svg_url = "http:" + re.findall('class^="un".+(//.+svgtextcss.+.svg)', ' '.join(css_res.text.split('}')))[0]
svg_res = requests.get(svg_url)
# 得到svg图片中的所有数字
digits_list = re.findall('>(d+)<', svg_res.text)
进行到这一步,我们就已经得到了所有以un开头的class对应的偏移量和所有的数字了,然后我们就可以利用前面的计算方法将这些偏移量转变成对应的数字了,也就能得到每个店铺的评分信息了。
最终运行结果如下:

完整代码已上传到GitHub!