一、页面分析
首先打开猫眼电影,然后点击一个正在热播的电影(比如:毒液)。打开开发者工具,点击左上角的箭头,然后用鼠标点击网页上的票价,可以看到源码中显示的不是数字,而是某些根本看不懂的字符,这是因为使用了font-face定义字符集,并通过unicode去映射展示,所以我们在网页上看到的是数字,但是在源码中看到的却是别的字符。

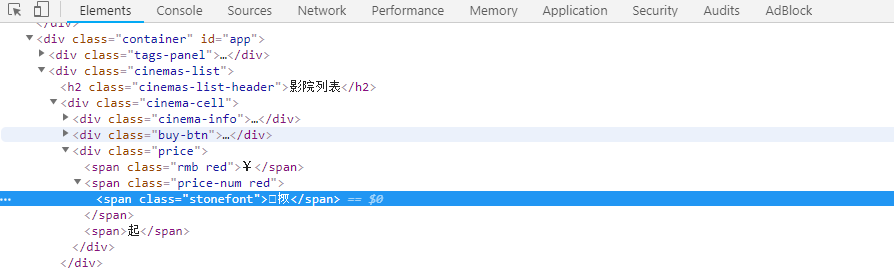
碰到这些根本看不懂的字符怎么办呢?不慌,右键选择查看网页源代码,然后找到相应的位置(如下图)。那么是不是“”映射出来就是28呢?

通过查看源码,可以找到如下内容, 而当我们访问这里面的链接的时候,就可以下载相应的字体文件,关于font-face可以点击这里查看了解:

当我下载好字体文件后,满心欢喜的双击想要点开的时候,却发现无法打开(T_T)。查阅资料之后知道了一个叫做FontCreator的软件,用这个软件可以打开我们下载的字体文件,没有安装这个软件的可以进入官网https://www.high-logic.com/下载安装,如果下载得很慢的可以用百度云下载(链接:https://pan.baidu.com/s/1ImxwPhKdzZo2g4bIjiGCZw ,提取码:m0yf )。下载好之后打开软件,看到如下界面,选择Use Evaluation Version,这个软件我们可以免费使用三十天。
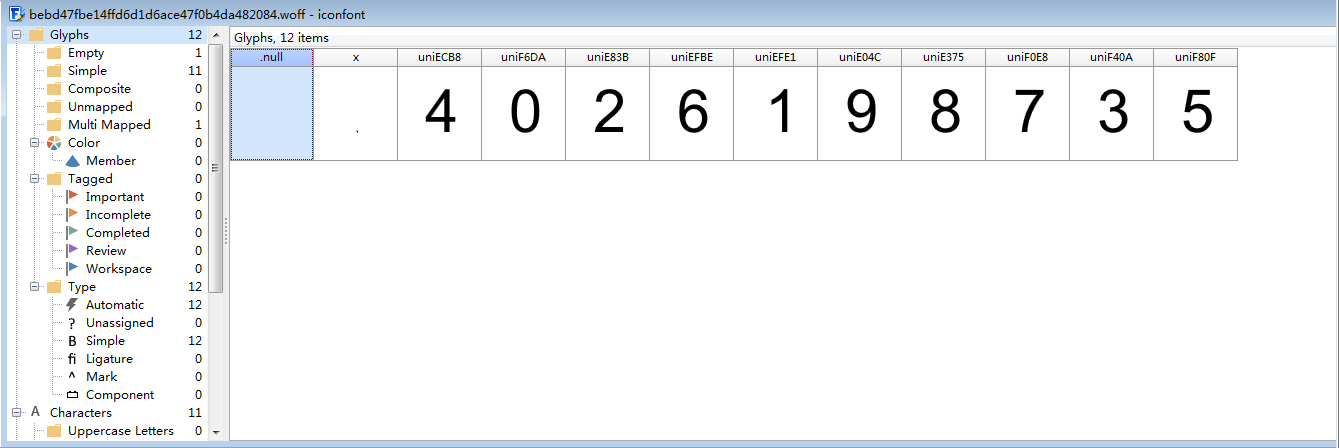
打开软件后,再打开我们下载的字体文件,可以看到数字2和8分别对应的是uniE83B和uniE375,和前面看到的编码是一致的。
那么我们下载好字符集之后,只要将其中的字符编码和数字对应的信息提取出来,再把网页源码中的字符编码替换掉,就能得到我们想要的数据了。这里要用到一个三方库fontTools,利用fontTools可以获取每一个字符对象,这个对象你可以简单的理解为保存着这个字符的形状信息,而且编码可以作为这个对象的id,具有一一对应的关系。不过这里还有一个问题,就是网页每次使用的字符集是随机变化的,我们也就无法使用一个固定的字符集去做到反爬。
解决思路如下:先保存一个字体文件(比如base.woff),然后解析其数字和编码的对应关系,然后爬取的时候把新的字体文件下载下来(比如online.woff),网页中的一个数字的编码(比如ABCD),我们先通过编码ABCD找到这个字符在online.woff中的对象,并且把它和base.woff中的对象逐个对比,直到找到相同的对象,然后获取这个对象在base.woff中的编码,再通过编码确认是哪个数字。
二、主要代码
解析下载的字体文件,由于字体文件中有多余的字符,需要舍弃掉。
1 # 解析字体库 2 def parse_ttf(font_name): 3 """ 4 :param font_name: 字体文件名 5 :return: 字符-数字字典 6 """ 7 base_nums = ['3', '0', '1', '6', '4', '2', '5', '8', '9', '7'] 8 base_fonts = ['uniEB84', 'uniF8CA', 'uniEB66', 'uniE9DB', 'uniE03C', 9 'uniF778', 'uniE590', 'uniED12', 'uniEA5E', 'uniE172'] 10 font1 = TTFont('base.woff') # 本地保存的字体文件 11 font2 = TTFont(font_name) # 网上下载的字体文件 12 13 uni_list = font2.getGlyphNames()[1:-1] # 去掉头尾的多余字符 14 temp = {} 15 # 解析字体库 16 for i in range(10): 17 uni2 = font2['glyf'][uni_list[i]] 18 for j in range(10): 19 uni1 = font1['glyf'][base_fonts[j]] 20 if uni2 == uni1: 21 temp["&#x" + uni_list[i][3:].lower() + ";"] = base_nums[j] 22 return temp
解析网页源码,把其中的编码替换成数字,这里选择把网页源码保存下来,这样的话编码就不会改变,也就能正确的解析。
1 # 解析网页得到数字信息 2 def get_nums(font_dict): 3 """ 4 :param font_dict: 字符-数字字典 5 :return: 由评分、评分人数、票房和票价组成的列表 6 """ 7 num_list = [] 8 with open('html', 'r', encoding='utf-8') as f: 9 for line in f.readlines(): 10 lst = re.findall('(&#x.*?)<', line) 11 if lst: 12 num = lst[0] 13 for i in font_dict.keys(): 14 if i in num: 15 num = num.replace(i, font_dict[i]) 16 num_list.append(num) 17 return num_list
三、运行结果

完整代码已上传到GitHub!