在刷题/比赛时经常会遇到判重的问题,那么这次就来讲一讲字符串上的判重问题。
▎哈希是什么
判重我们通常会想到什么?小编首先想到的是桶排序,这种排序正是用了哈希的方法,其实把哈希理解为一堆桶更合适。
比如说现在给你一堆数字,让你判断一共有几种数字(也就是重复出现的不算): 1 5 4 1 1 3 5 6 。以哈希的思想来解决就是这样的:
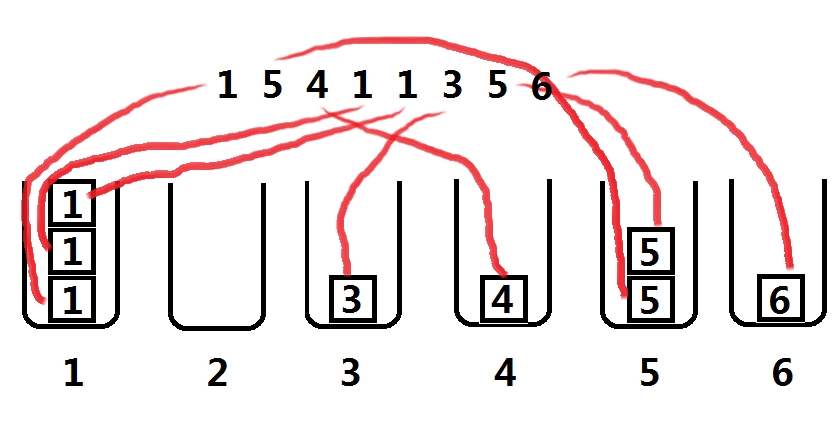
放若干个桶,每个桶代表一种数,遇到相应的数字就放进去,判断几种数字就转换成了判断有几个有东西的桶就可以了。
那么,接下来思考一个问题:怎么存这些桶?要存这些桶只要用绝对不可能重复出现的量来代表桶的序号,例如……数组下标!我们可以利用数组下标来当做桶,每个桶里面东西的个数就是对应数组元素的值。比如说用一个叫做a的数组来存这些桶,当遇到数字3时,只要将a[ 3 ] ++;就可以了。
其实这就是哈希,所以说理解成一堆桶更形象。
▎字符串下的哈希
看到这里,你一定会想,字符串哈希有什么好讲的?不也是一个道理吗?当然不行!仔细想想,数组下标怎么存储成字符串呢?数组下标都是整数的啊!
此时出路就很敞亮了,我们可以把字符串转换成整数处理!
还记得吗?在最开始学习时还学过ASCII码,我们可以通过强制转换替换成整数。
可是问题又来了,如何用ASCII表示字符串?例如AB,其中A的ASCII码是65,B的ASCII码是66。
1)用加的:AB表示为65+66=131。反例:BA表示为66+65=131,可AB和BA不一样;
2)用减的、乘的、除的,似乎都同上,表示出的值都不唯一;
3)放在一起:AB表示为6566,这样的确举不出什么反例了,但是数字的值变大了,同时也区分不回去了,6566究竟是6和566呢?还是6,56和6呢?似乎不知道原来的字符串长什么样了。
自然而然,我们便想到了转进制,这样不易发生问题。那么取什么样的进制会不发生或少发生问题呢?我们往往会取27,233,19260817等等,具体会视情况而定。(稍后会有例题讲解)。
有时会超出unsigned long long的范围,那该怎么办呢?那么我们就要用取模的方法了,通常会模一个很大的质数,模多少可以看看题后的数据规模是多大。
有些时候会发生一些情况,比如3%2=1,5%2=1(打个比方,一般模数不会这么小),所以两个数取模后当成了一个数来处理,这便叫做哈希冲突,在做题时要减少这种冲突的产生。
▎例题——【模板】字符串哈希
题目描述
如题,给定N个字符串(第i个字符串长度为Mi,字符串内包含数字、大小写字母,大小写敏感),请求出N个字符串中共有多少个不同的字符串。
输入输出格式
输入格式:
第一行包含一个整数N,为字符串的个数。
接下来N行每行包含一个字符串,为所提供的字符串。
输出格式:
输出包含一行,包含一个整数,为不同的字符串个数。
输入输出样例
说明
时空限制:1000ms,128M
数据规模:
对于30%的数据:N<=10,Mi≈6,Mmax<=15;
对于70%的数据:N<=1000,Mi≈100,Mmax<=150
对于100%的数据:N<=10000,Mi≈1000,Mmax<=1500
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
这道题完全是模板题,直接套思路就好了。
▎Code speaks louder than words!
话不多说,直接上代码(详见注释)
1 #include<iostream> 2 #include<algorithm> 3 using namespace std; 4 string s;int n;int hash[10000],mod=19270817,k=30,ans=1; 5 int Hash(string str) 6 { 7 int len=str.length(); 8 int value=0; 9 for(int i=0;i<len;i++) 10 value=value*k+((int)str[i]-96);//转进制 11 return value;//这里其实也可以模一下,不过数据规模没有那么大 12 } 13 int main() 14 { 15 cin>>n; 16 for(int i=1;i<=n;i++) 17 { 18 cin>>s; 19 hash[i]=Hash(s);//存储每个字符串转换后的哈希值 20 } 21 sort(hash+1,hash+n+1);//排序,目的是为了排除相同哈希值的字符串 22 for(int i=2;i<=n;i++) 23 if(hash[i]!=hash[i-1]) ans++;//如果哈希值不同,那么两个字符串就不一样 24 cout<<ans; 25 return 0; 26 }
▎map是啥?
说来对于这种题来说还有一大利器——map。简单介绍一下:
1)头文件:#include<map>
2)定义:map< 类型 , 类型 > 变量名;
第一个类型是数组下标的类型,第二个变量是数组值的类型
3)用处:map定义出来的东西可以理解为数组下标为任意的数组,这恰恰起到了刚才那道题最开始思路的效果
4)举个栗子:比如说要定义一个数组下标是字符串的整型数组s,可以这么写map< string , int > s;
怎么解刚才那道题?直接普通哈希就可以了,就不写注释了。
1 #include<iostream> 2 #include<map> 3 using namespace std; 4 map<string,int>s;string str[100000];int n,ans; 5 int main() 6 { 7 cin>>n; 8 for(int i=1;i<=n;i++) 9 { 10 cin>>str[i]; 11 s[str[i]]=1; 12 } 13 for(int i=1;i<=n;i++) 14 { 15 if(s[str[i]]==1) 16 { 17 ans++; 18 s[str[i]]=0; 19 } 20 } 21 cout<<ans; 22 return 0; 23 }
▎为什么放着map不用而用前一种方法
map看起来好用,就像数组一样,其实map只是单单的映射,简单来说就是暴力查询,时间复杂度可想而知,这速度很慢,有时是可以AC题目的,但有时是满足不了题目的要求的时间的,所以还是老老实实用字符串下的哈希吧。