What is TRANSFORMER?
今天学一下变形金刚,transformer是一个很有用的模型,尤其会为我们后面学习BERT model打好基础。文章如有不当之处,请不吝赐教。下面来看一下这个神奇的工具吧。
李宏毅老师transformer课程:https://www.youtube.com/watch?v=ugWDIIOHtPA
用CNN代替RNN
Seq2Seq模型是一个很常用的东西,它能处理的问题类型很广泛,包括翻译、命名体识别等NLP领域的火热话题。这里有一篇关于Seq2Seq的教程,希望能够帮助不是很熟悉Seq2Seq的朋友,下文假设大家已经都比较清楚Seq2Seq model了,至少比我要强。
应该说Seq2Seq模型很不错,但是我们还是有不满意的地方。哪里不满意呢?
其实很多人都很注意模型是否能够在数据并行、计算并行的条件下工作,能够得到一个高效的训练方法。RNN就暴露了一个很显然的问题,那就是它并不能并行计算。那我们看看有没有什么其他的方案可以替代它呢?CNN行不行呢?当然可以,要不然这段标题就没有意义了。
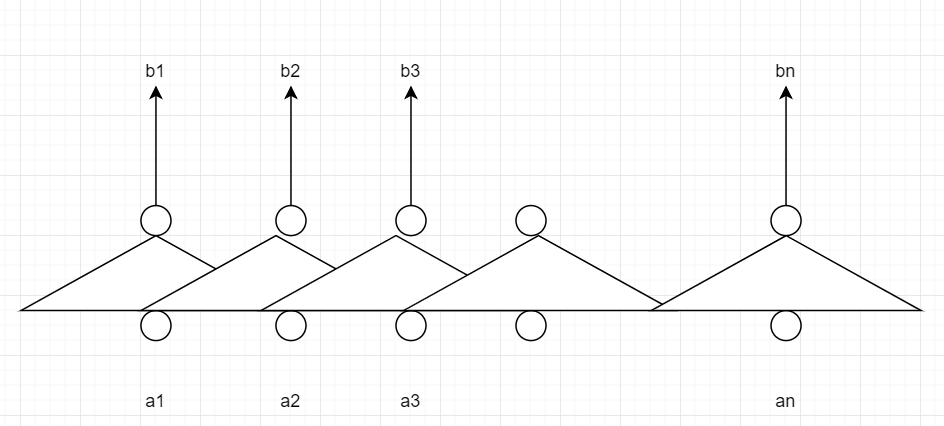
纯手绘图,有点丑请见谅。
在图中象征性的画了几个CNN,用(a_1, a_2, .. a_n)作3个一起的inner product,得到第一层之后的节点,用第一层的输出继续CNN,以此类推我们可以得到(b_1, b_2, ..b_n)。可以看出,虽然一次CNN计算只能考虑附近的三个点的输入,但是多几层就可以考虑整个序列,能起到和bi-RNN类似的效果,更重要的是,你在计算下一层的部分节点时候不需要本层所有节点都算完,计算第(i)个节点不需要算出本层的第(i - 1)个节点,这让我们的并行成为了可能。
缺点
上面提到的这个做法的缺陷也很明显,就是你必须要加很多层CNN,才可以达到查看整个序列的信息的目的。为了做出改进,有了下面的self-attention。
Self-Attention
我们先给Self-Attention layer一个概念性的定义。
自注意力机制最早来源于Google的一篇论文,这篇论文的名字估计很多人听过,叫'Attention Is All You Need',文中阐述了这个模型的工作原理。总体的来讲,他也是一个Sequential Model,适合处理序列性问题。从论文标题我们就可以看出,文章告诉我们,不再需要RNN,不需要CNN,这个模型也可以input一个sequence,output一个sequence,并且能像bi-directional RNN一样,输出是看过整个输入的,而且还可以parallel!
How to do attention
假设我们的输入还是最原始的one-hot vector,首先通过embedding。即:
然后我们有三个矩阵(q,k,v),分别再得到(q^i, k^i, v^i):
attention
然后我们做的一件事情,就是对于每一个(query)去和别的(key)作attention。我们得到attention后的结果。
其中一种可以选用的attention做法,也是paper中的做法:
其中(d)是(q,k)的维度,为了保证dot product的结果不会大到超出我们的预期,可以直观的感受一下这一部分的作用。当然,其他的运算方法也是可以的,在'attention is all you need'中并没有对运算方法的不同对模型效率的影响做评估。
对上面的结果作softmax:
我们这样就计算出了注意力下的各个(x_j)对(x_i)的重要性。
计算output
得到的注意力权重已经是看过整个序列之后的结果了,只要我们的(v^i)也是正确的,我们有理由得到:
在这个计算过程中,大家看的出来,两个点不过距离多远,只要注意力足够,我们都能保证一定的关联度。
Matrix计算
现在我们看看整个过程是怎么parallel的。
attention过程:
上面的一连串运算都是矩阵乘法,可以使用GPU加速。
变种:Multi-Head self-attention
所谓Multi-Head Self-Attention呢,就是在原来(q)的基础上,我们继续分:
(k,v)也如此做,这样就得到了多个(b),最后再做结合并降维就可以了。
引入多个head的好处是,不同的注意力头可能会注意不同的地方,Google的论文中提到,他们各司其职,可能有的比较注意附近的点,有的比较注意离得远的。
位置信息
如果你还记得,上面说self-attention的这种做法是远处和进出一视同仁,并不考虑各种顺序关系。我们知道这肯定是不合理的,为了让它考虑位置信息,我们再加上position的内容。
做法是用一个包含位置内容的向量(e^i)来表示,这个(e^i)并不是学习出来的,而是人为规定的。
其实这个位置信息更直观的添加方法是在(x^i)那里concat一个表示位置的one-hot对吧?不用担心,实际上道理上是都可行的,而且论文中已经证明了后者做法效果不会比前者更好。
In this work, we use sine and cosine functions of different frequencies:
[P E(pos,2i) = sin(pos/10000^{2i/d_{model} })\ P E(pos,2i+1) = cos(pos/10000^{2i/d_{model} } ) ]where pos is the position and i is the dimension.
Seq2Seq with Attention
现在回忆一下你熟悉的Seq2Seq模型,其中的encoder和decoder,不管是有没有attention,我们都用上面讲的self-attention layer代替。下面是来自Google AI Blog的动画:
![]()
一个做翻译任务的transformer的完整结构图如下:
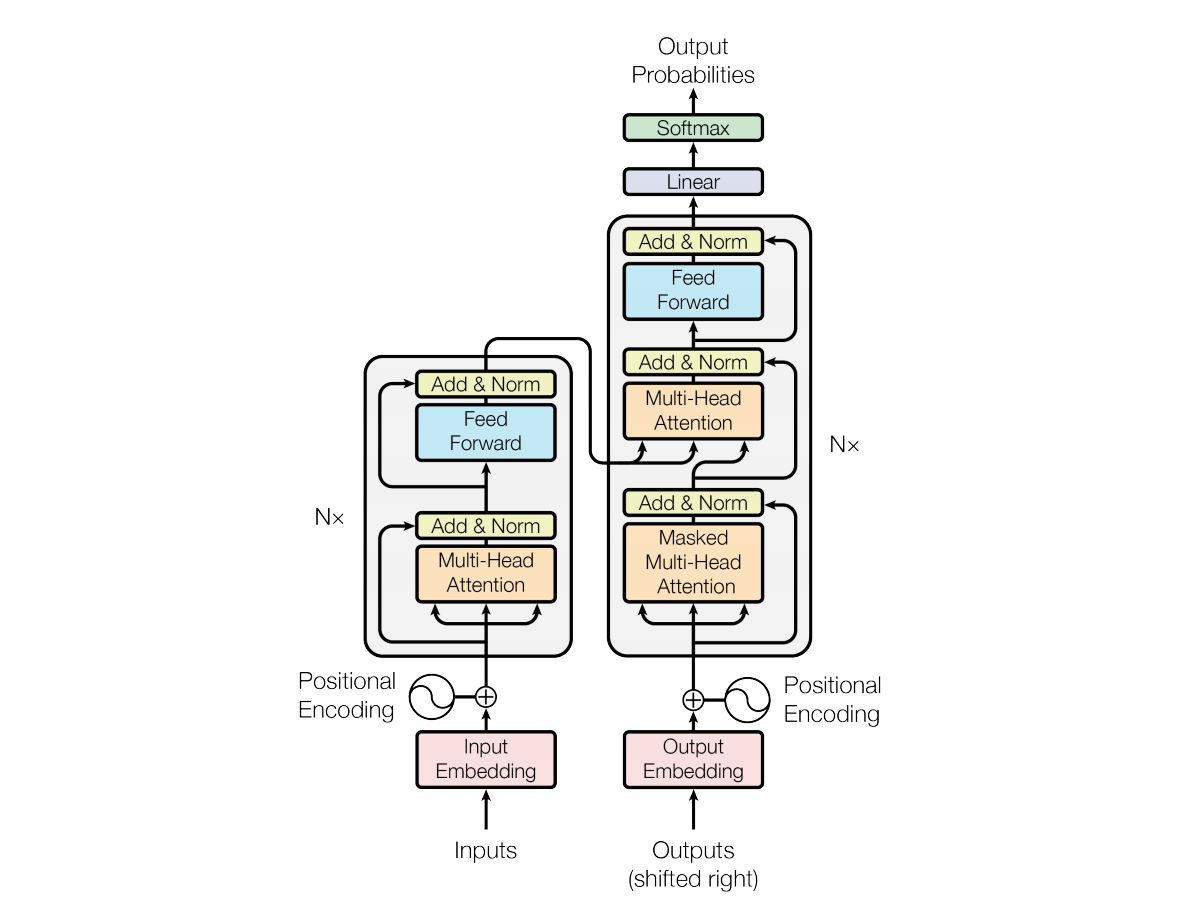
encoder
首先inputs做Embedding,然后用包含位置信息的Positional Encoding加到Embeded input中去,作为整个encoder的输入。
encoder由(N)个sublayers组成,每个sublayer又有一个Multi-Head Attention layer和Feed Forward layer组成,其中的Add是把输入和输出加在一起,Norm是做了一次layer Normalization。
decoder
decoder相比encoder,多了一层Masked Multi-Head Attention。解码时,所有的已经预测出的结果和输入的Context Vector都会参与Attention,因为只计算已经得到的output的key,所以要这遮住一部分。
应用
基本上所有Seq2Seq用的东西,Transformer都可以应用。可以用它替代RNN,并且能够实现更好的效果。比如文章摘要自动生成,不管输入还是输出,在数量级上都比RNN的应用阶段提升了不少。
Universal Transformers,更加扩展了transformer的应用范围,弥补了其缺点。