Github项目地址:https://github.com/TTTIDE/personal-project
PSP表格如下:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 420 | 500 |
| Development | 开发 | 340 | 400 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 70 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 50 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 60 | 70 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
需求分析:
题目:
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
- 输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
...
思路分析:
刚拿到题目,当然是先分析题目,题目几个重要的点都已画出来,随后思考如何进行下一步。
上网查找资料,进行分析。
先解决用什么读文件,用什么进行单词统计,用什么方法进行筛选正确的单词出来。
针对每个问题有个大概的解决方法,再对每一部分进行完成。
再查找api文档,关于一些类方法的功能和调用。
流程图如下:
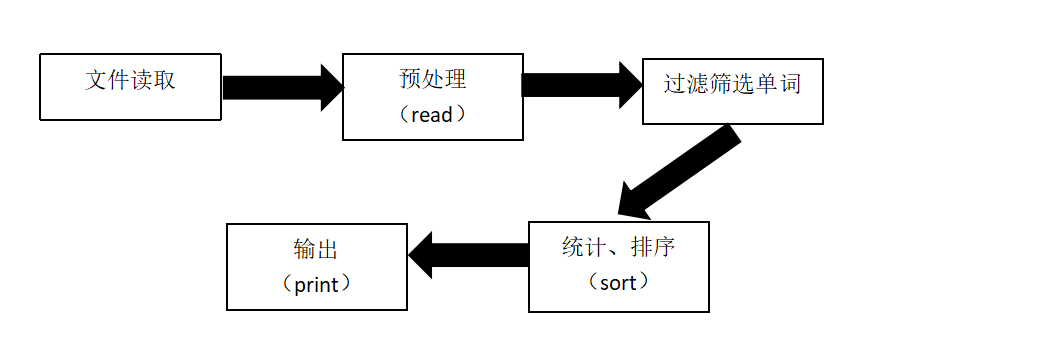
首先先读文本,利用BufferedReader,从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
因为是统计文件的字符数,又有一个重点是不区分大小写并且是输出单词统一为小写格式,所以我想到的是先对文件进行处理,先把所有的字母都转换为小写的在进行统计。所以在一开始就先对txt进行处理,处理完之后进行下一步。
单词至少是4个英文字母开头,并且例如file123都算是一个单词,但123file,不算一个单词。并且需要统计单词的词频,就想到用map来写。把单词当做key的时候不论是否有4个字母都先进行存放,最后输出top10的时候在进行判断,从而输出。在筛选单词直接用正则来过滤,例split("[^a-zA-Z0-9]") 后,再利用for循环找出以字母开头的单词,当做key放入map。
之后还有一点就是统计总的字符数,直接调用BufferedReader中的readline()方法,对每一行的字符数进行累加,最后只需要再加上行数-1就是文本中总的字符数。(总的行数,利用循环判断,readline()!=null时++)。
1.先对文本进行大小写处理
private static String Read() throws FileNotFoundException, IOException { Scanner scanner=new Scanner(System.in); String pathname=scanner.nextLine(); Reader myReader = new FileReader(pathname); Reader myBufferedReader = new BufferedReader(myReader); //先对文本处理 CharArrayWriter tempStream = new CharArrayWriter(); int i = -1; do { if(i!=-1) tempStream.write(i); i = myBufferedReader.read(); if(i >= 65 && i <= 90){ i += 32; } }while(i != -1); myBufferedReader.close(); Writer myWriter = new FileWriter(pathname); tempStream.writeTo(myWriter); tempStream.flush(); tempStream.close(); myWriter.close(); return pathname; }
2.在进行单词的过滤和存放
while((readLine = br.readLine()) != null){ wordline++; String[] wordsArr1 = readLine.split("[^a-zA-Z0-9]"); //过滤 characterscount+=readLine.length();//统计每行的字符数 最后只需再加上行数就是总字符数 for (String newword : wordsArr1) { if(newword.length() != 0){ //去除长度为0的行 //while(!(word.charAt(0)>=97&&word.charAt(0)<=122)&&(word.length()>=4))//注意异常,substring用法 //{ // word = word.substring(1); //} //重新阅读题目 , 12345word中word不能算是单词 所以去掉这部分内容 if((newword.length()>=4)&&(Character.isLetter(newword.charAt(0))&&Character.isLetter(newword.charAt(1))&&Character.isLetter(newword.charAt(2))&&Character.isLetter(newword.charAt(3)))) { wordcount++; lists.add(newword); } } } }
3.对词频统计
for (String li : lists) { if(wordsCount.get(li) != null){ wordsCount.put(li,wordsCount.get(li) + 1); }else{ wordsCount.put(li,1); } }
4.输出
测试样例:
aaa
123bbb
abc123
dddd
DDDD
Abc123
ABC123
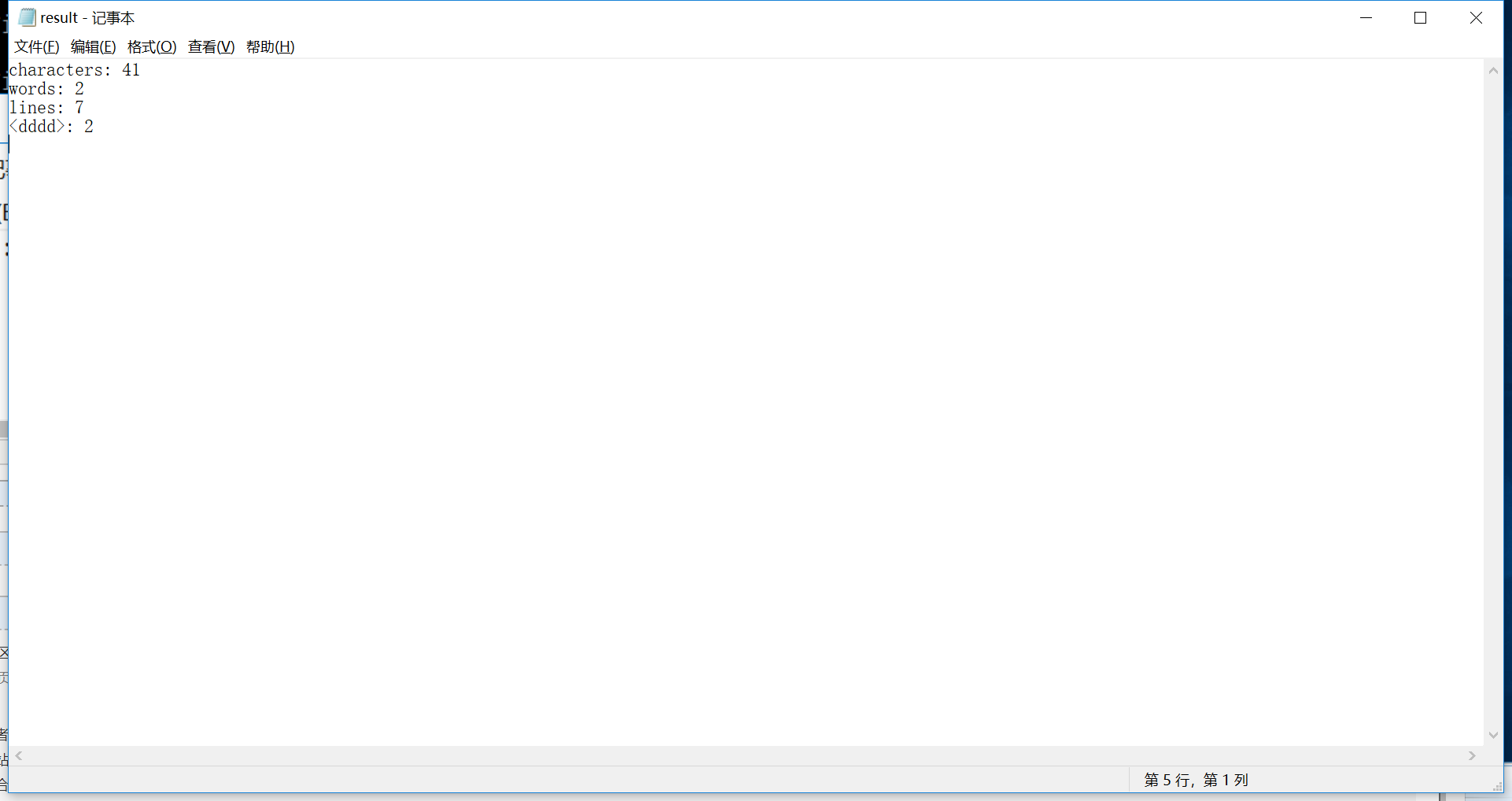
输出结果:
characters: 41
words: 2
lines: 7
<dddd>: 2
性能分析:
使用的是JProfiler的性能分析工具自动生成
反复测试几次后
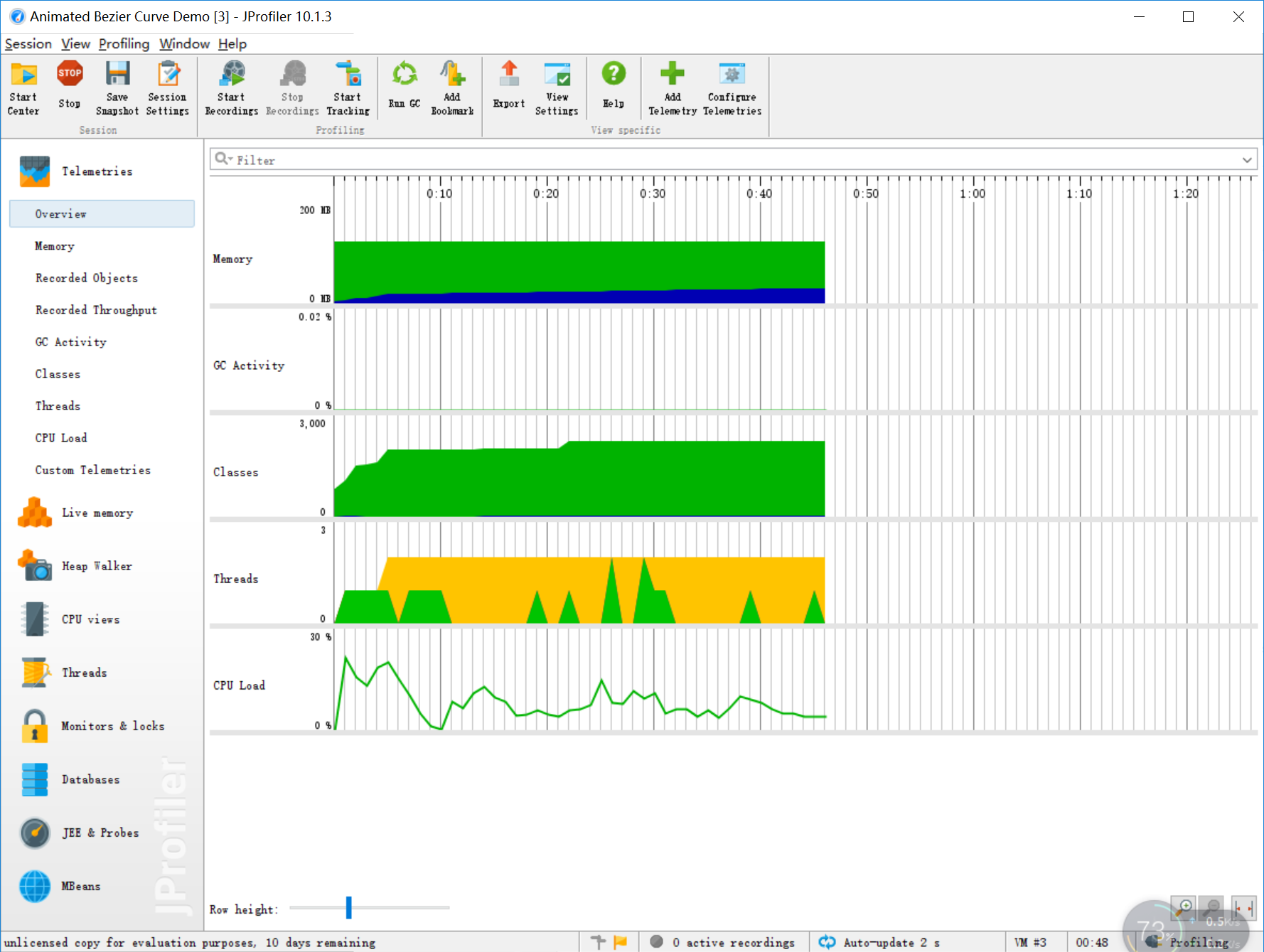
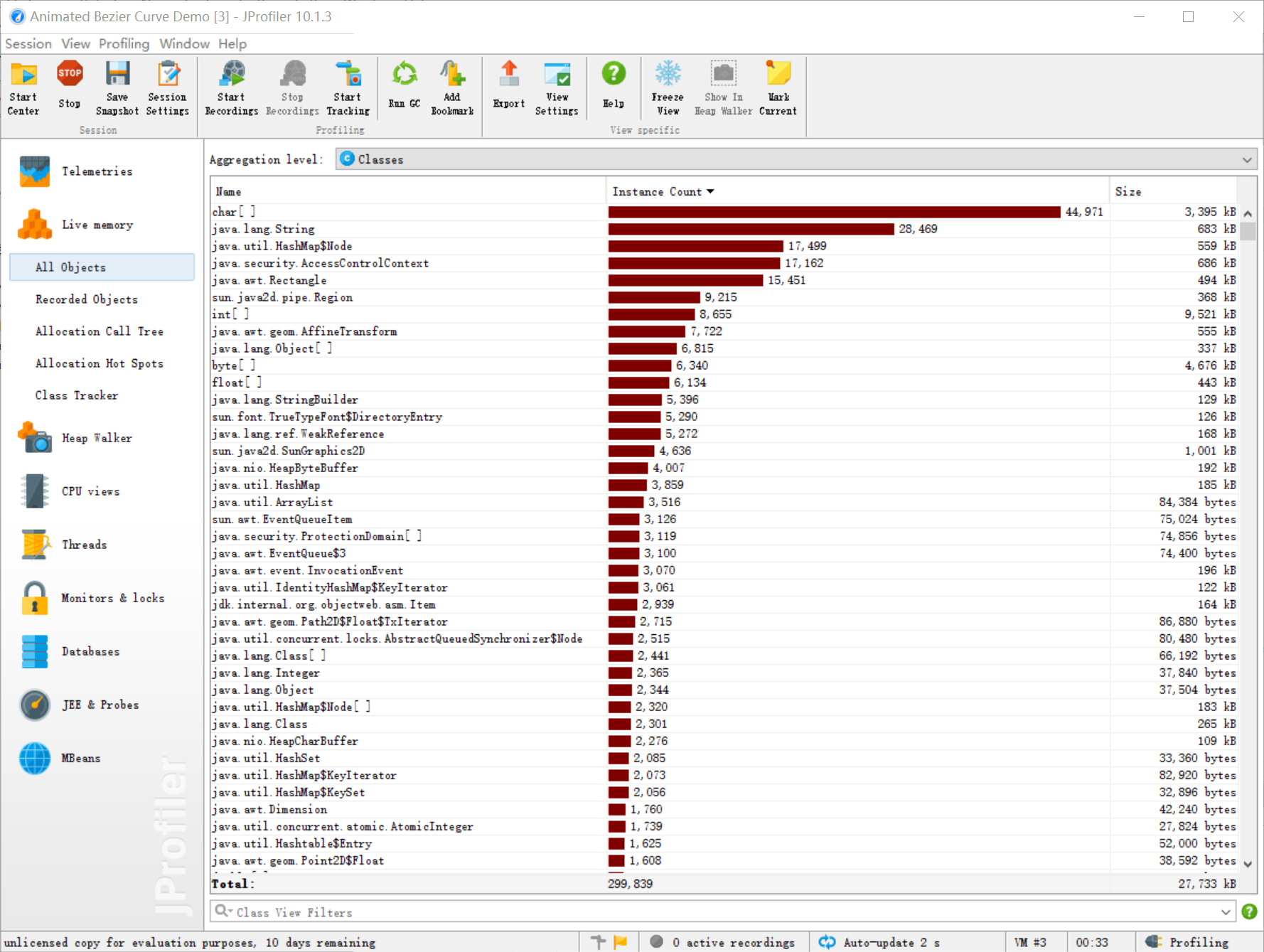
覆盖率测试:

心路历程及收获:
在得到一个题目之后,首先要做的是先对题目进行分析,圈出重要的部分。然后针对题目思考如何进行完成,可以分步进行,考虑每一部分该如何去做。在做题过程中有一些不了解和之前未涉及到的部分,查阅资料和询问他人是一个比较简便快捷的方法,弄懂了之后再继续完成该做的部分。就学到一些之前不了解的知识,一些语法,类方法调用问题,及如何使用git和使用JProfiler进行性能分析等。