了解网页
以中国旅游网首页(http://www.cntour.cn/)为例,抓取中国旅游网首页首条信息(标题和链接),数据以明文的形式出面在源码中。在中国旅游网首页,按快捷键【Ctrl+U】打开源码页面,如图 1 所示。
认识网页结构
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JScript(活动脚本语言)。
HTML
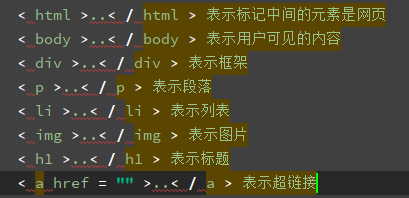
HTML 是整个网页的结构,相当于整个网站的框架。带“<”、“>”符号的都是属于 HTML 的标签,并且标签都是成对出现的。
常见的标签如下:
CSS
CSS 表示样式,图 1 中第 13 行<style type="text/css">表示下面引用一个 CSS,在 CSS 中定义了外观。
JScript
JScript 表示功能。交互的内容和各种特效都在 JScript 中,JScript 描述了网站中的各种功能。
如果用人体来比喻,HTML 是人的骨架,并且定义了人的嘴巴、眼睛、耳朵等要长在哪里。CSS 是人的外观细节,如嘴巴长什么样子,眼睛是双眼皮还是单眼皮,是大眼睛还是小眼睛,皮肤是黑色的还是白色的等。JScript 表示人的技能,例如跳舞、唱歌或者演奏乐器等。
如何查看网页是否允许爬虫
几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt 的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面数据都可以爬取。如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据;
在网址后面输入/robots.txt即可查看:https://www.baidu.com/robots.txt

表示除了上面的其余都不能爬取数据;
爬虫基本原理
使用 requests 库请求网站
安装 requests 库
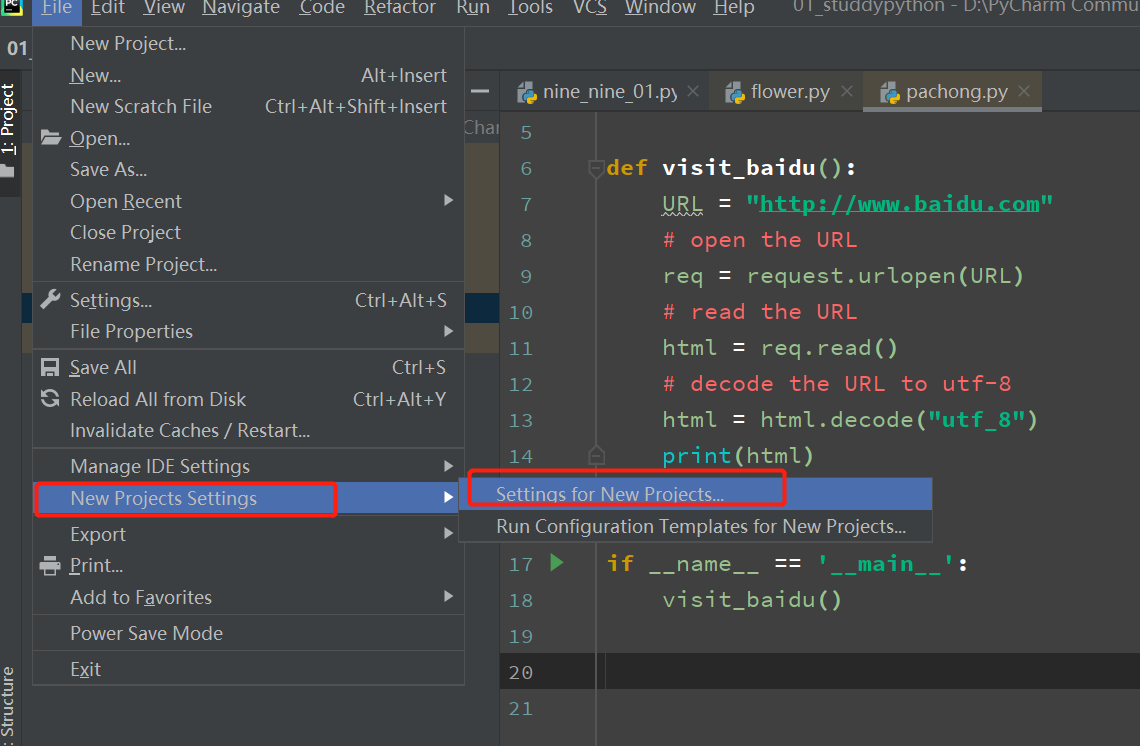
首先在 PyCharm 中安装 requests 库,为此打开 PyCharm,单击“File”(文件)菜单,选择“New Projects Setting >>Setting for New Projects...”命令,如图 4 所示。
选择“Project Interpreter”(项目编译器)命令,确认当前选择的编译器,然后单击右上角的加号,

在搜索框输入:requests(注意,一定要输入完整,不然容易出错),然后单击左下角的“Install Package”(安装库)按钮

安装完成后,会在 Install Package 上显示“Package‘requests’ installed successfully”(库的请求已成功安装)
网页请求的过程
分为两个环节:
- Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
- Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求
网页请求的方式也分为两种:
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
所以,在写爬虫前要先确定向谁(地址)发送请求,用什么方式发送。
使用 GET 方式抓取数据
请求网页源码:
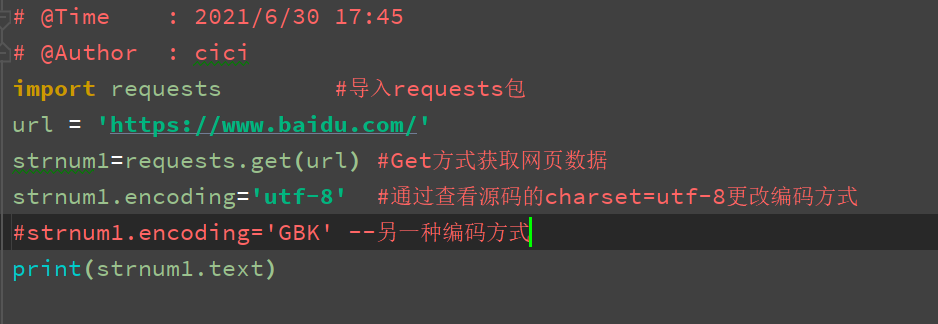
import requests #导入requests包
url = 'http://www.dangdang.com/'
strnum1=requests.get(url) #Get方式获取网页数据
print(strnum1.text)
这种执行完会提示中文乱码,解决方法是要么是utf-8编码,要么是GBK编码,需要右键查看网页源码中meta标签中charset属性值
会发现输出的源码内容,没有f12查看到的element中数据多,是因为打开这个网页不只是纯静态的东西,还有些是调用的外链接css或者接口请求的结果;
request 4个基本属性方法
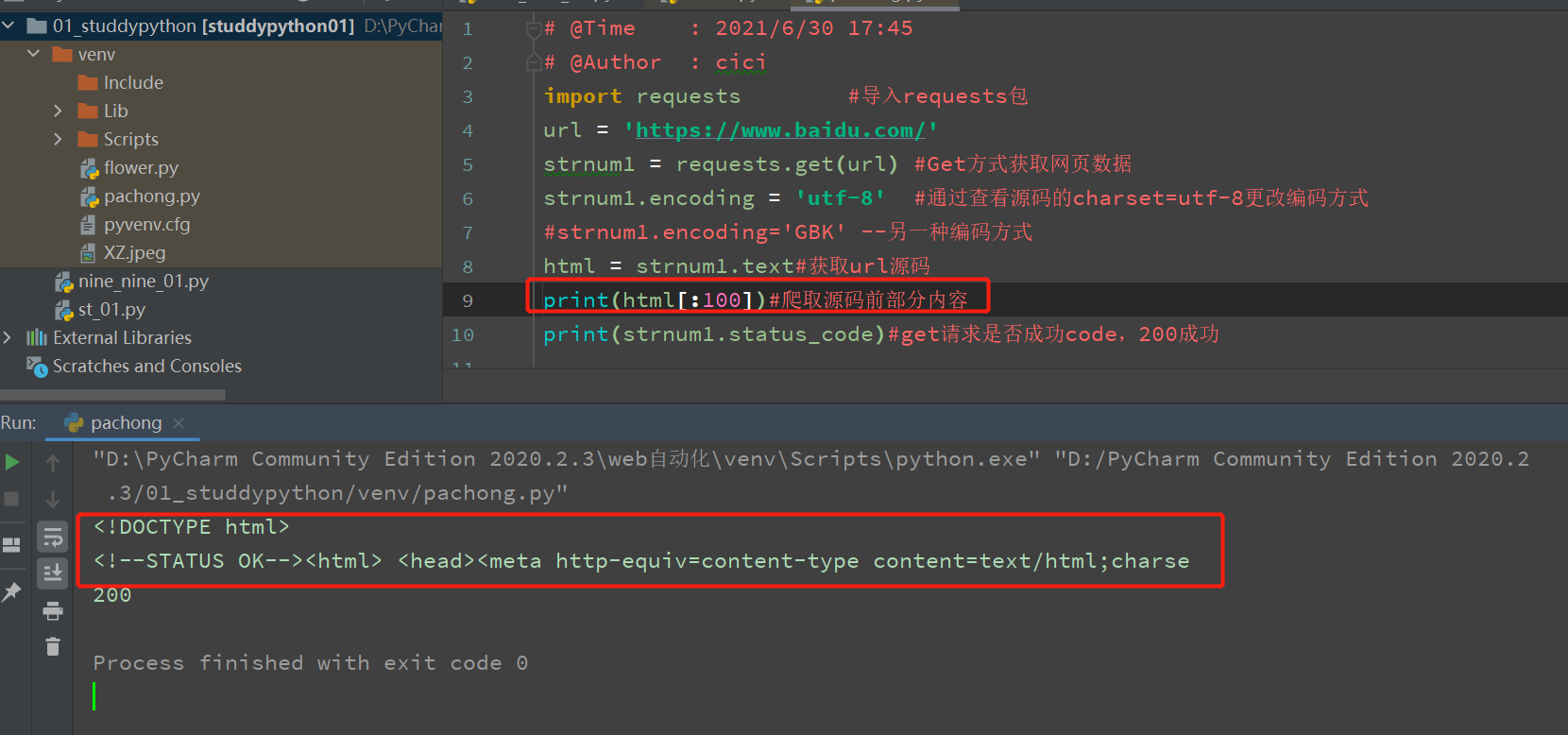
1..status_code
print(strnum1.status_code)#get请求是否成功code,200成功
2..text
html = strnum1.text#获取url源码
print(html[:100])#爬取源码前部分内容
3..enconding 方法
strnum1.encoding = 'utf-8' #通过查看源码的charset=utf-8更改编码方式
4..content
与text不同的是,是返回二进制源码格式;
转自作者:http://c.biancheng.net/view/2011.html
get请求URL传参
如图,先定义一个参数变量key,然后运用函数params,将params=变量key进行赋值即可;
Request1='http://rudder-test1.akucun.com/api/strategy/historyQuotaSurvey'
params={
"channelType": '0',
"date": '2021-07-09',
"timeUnit": '2',
"quotaType": '3'
}
get请求传header
Request1='http://rudder-test1.akucun.com/api/strategy/historyQuotaSurvey'
params={
"channelType": '0',
"date": '2021-07-09',
"timeUnit": '2',
"quotaType": '3'
}
header={
"User-Agent": 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
"Accept": 'application/json, text/javascript, */*; q=0.01',
"X-UserId": 'XXXXX',
"X-Mobile":'XXXX'
}
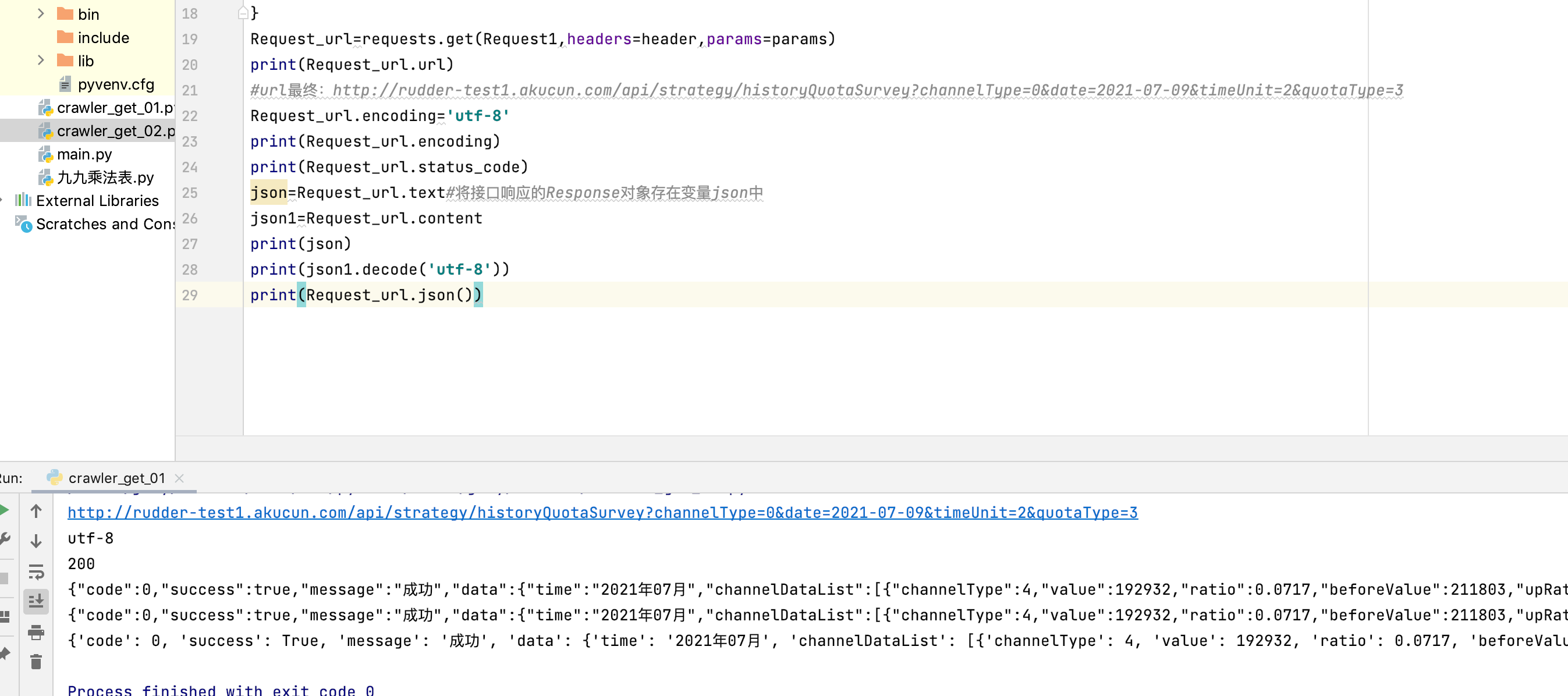
Request_url=requests.get(Request1,headers=header,params=params)
print(Request_url.url)
#url最终:http://rudder-test1.akucun.com/api/strategy/historyQuotaSurvey?channelType=0&date=2021-07-09&timeUnit=2"aType=3
equest_url.encoding='utf-8'
print(Request_url.encoding)
print(Request_url.status_code)
json=Request_url.text#将接口响应的Response对象存在变量json中
json1=Request_url.content
print(json)
print(json1.decode('utf-8'))
print(Request_url.json())
会发现输出text和context、Requests_url.json()结果输出一样了;.text是现成的字符串,.content还要编码,但是.text不是所有时候显示都正常,这是就需要用.content进行手动编码。.json()是输出json
接口response结果断言
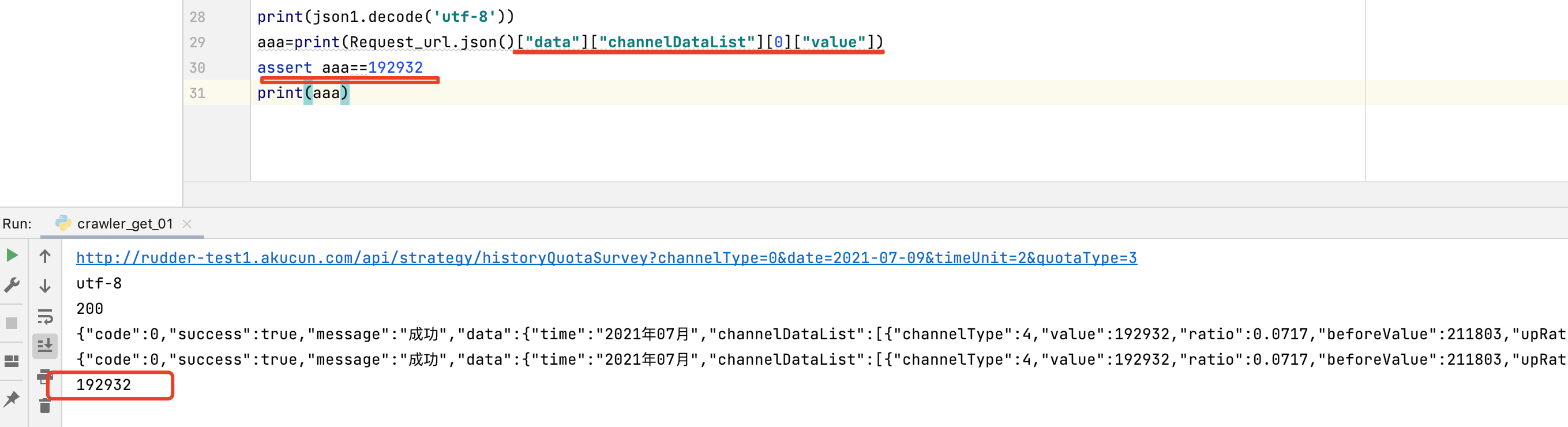
aaa=print(Request_url.json()["data"]["channelDataList"][0]["value"])#获取json字典中的数据方式
assert aaa==192932#断言 aaa是否真等于192932,如果等于继续执行下面的语句,否则抛出不等于的异常
print(aaa)