本篇介绍如何使用虚拟机搭建Hadoop集群,此例搭建1个master和2个slave,如要更多的slave,方法如此类推。
现在已经有安装了一台虚拟机,
1、查看虚拟机的虚拟网络,设置为NAT模式:
编辑——>虚拟网络编辑器
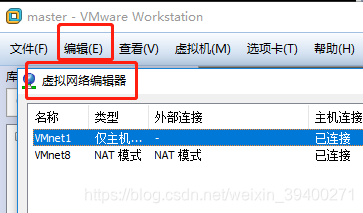
进入到虚拟网络编辑器界面后,单击VMnet8,
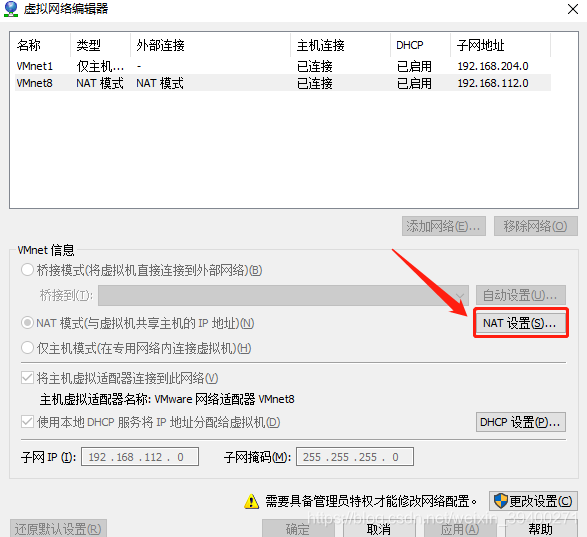
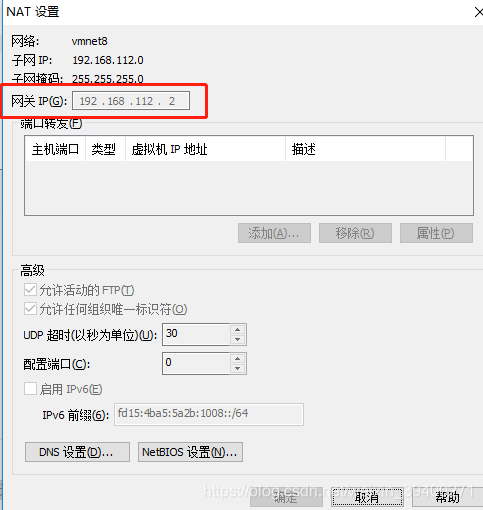
这里可以查看网关IP,默认是192.168.112.2,这个很重要,因为等下配置ifcfg-ens33文件时会用到。
2、自动获取IP功能初始化
VMWare需要用到自动获取IP的服务,所以需要对其进行初始化。而初始化是使用桥接模式:
在VMWare右下角位置,右击图标——>设置:
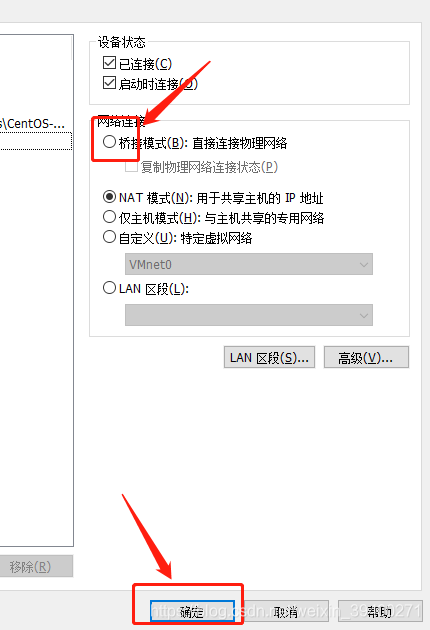
确定之后,待机器执行完成,重复同样的操作,不过要选择NAT模式,这样子,自动获取IP服务的功能已经初始化。
3、配置ifcfg-ens33文件
虚拟机上网的相关配置都在这个文件里面配置:
输入指令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
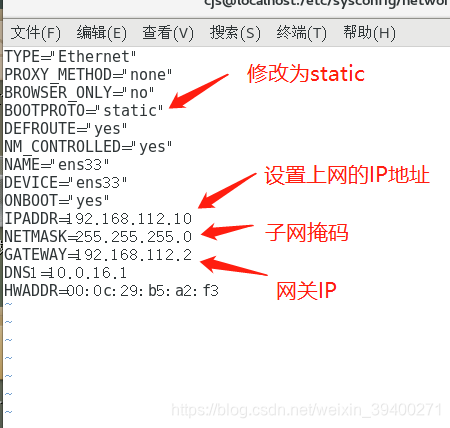
修改ifcfg-ens33文件需要root权限,可以在Linux输入命令su,然后输入密码,再次进入ifcfg-ens33文件,上网的IP地址随便设置,一般我们都会将网关IP的最后一位修改一下;网关IP就是第一步查看的那个网关IP;DNS1则是提供上网的服务地址,这个地址需要查看本机到底是连了那个网络服务地址,步骤:本机打开cmd窗口,输入ipconfig命令,下图框框所示就是提供网络服务的地址,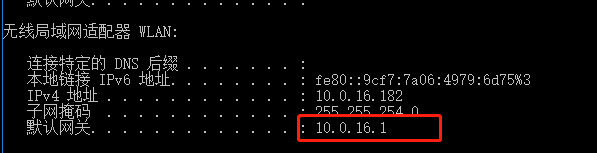
HWADDR则是网卡地址(不一定需要填写编辑),查看网卡地址则需要退出ifcfg-ens33文件进行查看,退出操作:按esc结束编辑,按shift + :,输入命令wq(wq表示保存修改并退出,q!表示不保存修改,直接退出),按enter,在Linux终端输入命令ifconfig: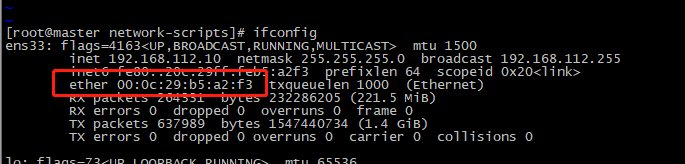
配置好之后,可以进行网络测试
4、网络测试
重启网络,输入命令:
/etc/init.d/network restart
![]()
上图所示,表示重启网络成功,但还是要测试一下是否可以上网:
输入命令:
curl www.baidu.com
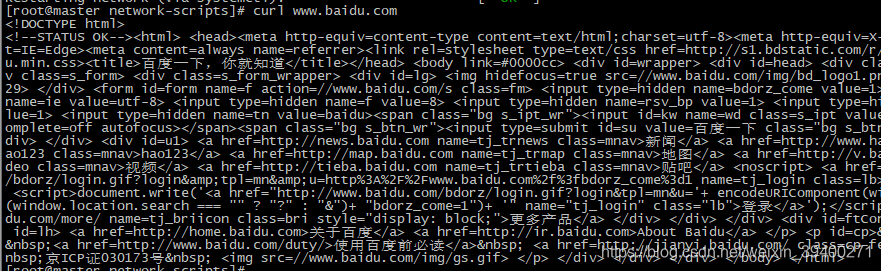
可以正常上网。那么这里,就将192.168.112.10作为本次集群的master节点。
5、创建slave节点
创建slave节点比较简单,首先关闭master节点(这个很重要),找到该节点的镜像所在的文件夹位置,对其整个镜像进行复制,粘贴。
复制、粘贴,修改文件夹名字:
新建两个虚拟机,分别为slave1和slave2,首先分别输入ifconfig查看是否显示正常,
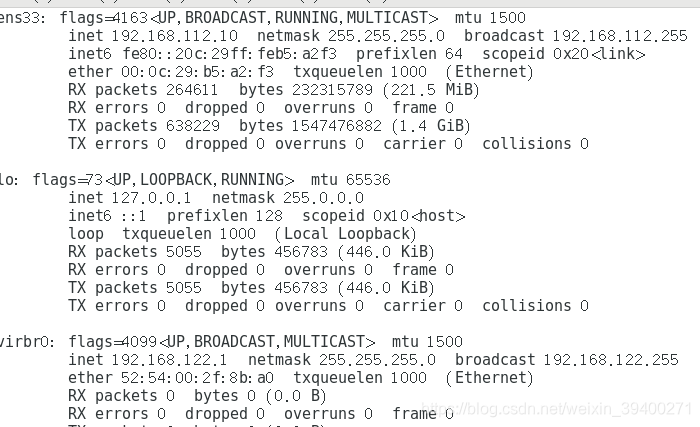
有时候并没有像上图那样显示,有可能少了ens33或者某些信息,输入命令“/etc/init.d/network restart”时,出现“Failed to start LSB:Bring up/down networking”的报错,这时要确定是否关闭NetWorkManager服务,因为刚创建的slave和master容易出现NetWorkManager服务冲突,这时master和slave都要关闭NetWorkManager服务,并禁止开机启动该服务,输入命令:
service NetworkManager stop
chkconfig NetworkManager off
执行命令后,重启虚拟机,之后就可以正常使用。
6、关闭防火墙
无论系统防火墙(指Linux),还是内核防火墙都要关闭。而且Master和slave都要操作。
(1)关闭系统防火墙
#查看防火墙状态,输入命令:
firewall-cmd --state
如果出现“not running”字样,说明防火墙已经关闭,如果不是这样的字样,则以下操作:
#停止防火墙,临时关闭,输入命令:
systemctl stop firewalld.service
#禁止防火墙开机启动,永久关闭,输入命令:
systemctl disable firewall.service
(2)关闭内核防火墙
#清空系统防火墙,输入命令:
iptable -F
如果没有iptable命令,可以执行下面命令下载,如果有,就忽略:
yum -y install iptable -services
#保存防火墙配置
service iptables save
#临时关闭内核防火墙,输入命令:
setenforce 0
#永久关闭内核防火墙:
vim /etc/selinux/config
添加语句:SELINUX=disabled
7、配置slave1和slave2的ifcfg-ens33文件
参考步骤3,slave1和slave2都需要配置,需要修改的地方有IPADDR,HWADDR(按实际情况修改),根据实际情况而修改,配置好,同样的重启一下网络。
将slave1的IPADDR修改为:192.168.112.11
将slave2的IPADDR修改为:192.168.112.12
8、安装JDK
默认情况下,CentOS7会自动安装了openjdk1.7和jdk1.8,但它们并不是我们想要的,所以要卸载它们。
#查看安装的JDK版本,输入命令:
rpm -q|grep jdk

#卸载原装的Open JDK,输入命令:
yum -y remove java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
yum -y remove java-1.8.0-openjdk-headless-1.7.0.65-3.b17.el7.x86_64
#安装JDK
去到Oracle官网下载Linux版本的JDK,
将压缩包导入到虚拟机里面,导入外部文件有好多种方法,这里介绍两种:(1)没有可视化界面的虚拟机,可以通过命令:rz,然后选择相应的压缩包文件,如下图:
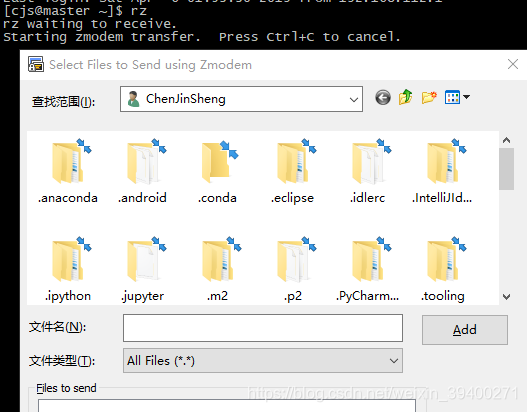
(2)有可视化界面的虚拟机,直接将压缩包文件复制粘贴到虚拟机的桌面:如下图
这里使用了第二种方法。
导入压缩文件后,进入到桌面路径下,将导入的压缩包通过命令的方式,复制到指定的路径下(目的是方便管理),
进入虚拟机桌面路径,输入命令:
cd ~
cd ./Desktop
![]()
#复制压缩包到指定路径
复制压缩包到/usr/local/src文件夹下,在当前Desktop目录下输入命令:
cp jdk-8u201-linux-x64.tar.gz /usr/local/src/
#解压压缩包
进入/usr/local/src目录下,输入命令:cd /usr/local/src,解压jdk压缩包,输入命令:
tar -zxvf jdk-8u201-linux-x64.tar.gz
#配置环境变量
解压成功后,输入命令:
vim ~/.bashrc
新增以下参数,并用“wq”进行保存退出:
export JAVA_HOME= /usr/local/src/jdk1.8.0_201 export JRE_HOME=$JAVA_HOME/jre
export CALSSPATH=.$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
#生效配置文件
配置完,使文件生效,输入命令:
source ~/.bashrc
#验证
都配置好了就验证一下,看一下jdk版本,输入命令:
java -version

可以用同样的操作方法,将slave1和slave2的JDK也安装好。
9、配置SSH
#修改映射关系,输入命令:
vim /etc/hosts/
新增以下内容(slave1和slave2也要加):
192.168.112.10 master
192.168.112.11 slave1
192.168.112.12 slave2
#修改主机名字,输入命令:
vim /etc/sysconfig/network
新增以下内容:
NETWORKING=yes
HOSTNAME=master
#设置临时主机名称,输入命令:
hostname master
输入验证命令:
hostname
在slave1和slave2也要设置,各自将“master”改为各自机器名
#永久设置hostname名称为xxx(每个机器都要设置):
在master节点
vim /etc/hostname
添加内容
master
在slave1和slave2也要设置,各自将“master”改为各自机器名
#生成ssh密钥
输入命令(每个节点都要生成一次):
ssh-keygen -t rsa
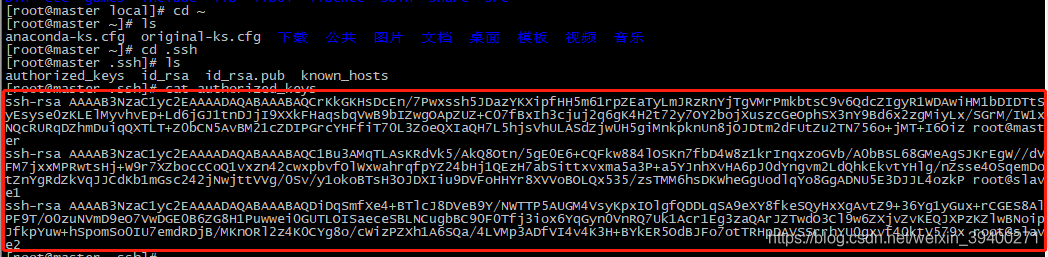
在slave1和slave2分别查看id_rsa.pub文件,并将文件内容复制到mastaer中的authorized_keys里,输入命令:
cd ~
cd .ssh
vim ./authorized_keys
复制完就是下面截图这样:
然后通过远程的方式,将authorized_keys文件覆盖到slave1和slave2中(或者用同样的方式在slave1和slave2中操作),输入命令:
scp authorized_keys root@slave1:~/.ssh/
scp authorized_keys root@slave2:~/.ssh/
#验证
最后在每台机器上分别验证,各自输入命令:
ssh slave1
ssh slave2
ssh master
拿master做例子:
首先,输入:ssh slave1,

此时机器已经转到slave1节点上,使用hostname命令验证,证明master可以访问slave1,然后再输入命令:ssh master,使得机器再次回到master节点,
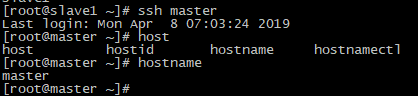
执行成功,说明slave1节点可以访问master;用同样的方法测试master->slave2:
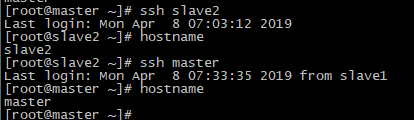
退出命令:exit
10、配置Hadoop2.6.1
#解压
同步骤8一样,复制hadoop压缩包到/usr/local/src/目录中,并解压。
#配置相关文件(这里给出master节点的,slave1和slave2的通过将master的相关文件远程复制过去)
进入hadoop路径,所有操作都在该文件夹路径下操作:
cd /usr/local/src/hadoop-2.6.1/etc/hadoop
(1)为hadoop配置jdk环境
vim hadoop-env.sh
添加内容:export JAVA_HOME=/usr/local/src/jdk1.8.0_201
(2)为分布式资源管理系统配置jdk环境
vim yarn-env.sh
添加内容:export JAVA_HOME=/usr/local/src/jdk1.8.0_201
(3)配置hadoop其他节点名称
vim slaves
添加内容:
slave1
slave2
(4)配置Hadoop Core
vim core-site.xml
添加内容:
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/tmp</value>
</property>
</configuration>
(5)配置Hadoop hdfs
vim hdfs-site.xml
添加内容:
<configuration>
<!--配置namenode.secondary地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/name</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/data</value>
</property>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(6)配置Hadoop mapper
注意:hadoop2.x没有mapred-site.xml,所以先拷贝并创建这个文件,输入命令:
cp mapred-site.xml.template mapred-site.xml
进入mapreduce配置文件:
vim mapred-site.xml
编辑文件:
<configuration>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(7)配置Hadoop yarn
vim yarn-site.xml
添加内容:
<configuration>
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置shuffle,因为map和reduce之间有个shuffle过程,-->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--为每个rm-id设置主机:端口用来提交作业。-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<!--调度器接口的地址。-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!--对每个rm-id设置NodeManager连接的host-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<!--对每个rm-id指定管理命令的host-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<!--对每个rm-id,指定RM webapp对应的host-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- 关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
#创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.6.1/tmp
mkdir -p /usr/local/src/hadoop-2.6.1/dfs/name
mkdir -p /usr/local/src/hadoop-2.6.1/dfs/data
#配置Hadoop的环境变量(master、slave1和slave2都要配置)
vim ~/.bashrc
添加内容:
HADOOP_HOME=/usr/local/src/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/bin
#重新启动资源文件
source ~/.bashrc
这个时候可以将上面再master节点下的hadoop文件下的配置文件copy到slave1和slave2里,输入命令:
scp -f /usr/local/src/hadoop-2.6.1/ root@slave1:usr/local/src/
scp -f /usr/local/src/hadoop-2.6.1/ root@slave2:usr/local/src/
11、启动集群
#初始化Namenode,只在master节点操作,
hadoop namenode -format
注意:该命令重复执行的话,有可能会出现异常。这时需要,删除相关文件(这个后面再讲),重新初始化hadoop
#启动集群
在master节点操作
/usr/local/src/hadoop-2.6.1/sbin/start-all.sh

启动后,分别在master、slave1和slave2节点上输入命令:jps,查看节点:
(1)master节点
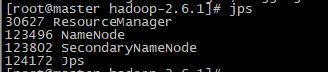
(2)slave1节点
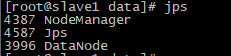
(3)slave2节点
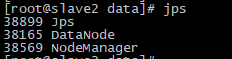
上面提及到:重复初始化hadoop会带来了异常,导致某些node无法正常启动,解决方法:
1、关闭集群,./sbin/stop-all.sh
2、删除/usr/local/src/hadoop-2.6.1/dfs/name下面的文件[每个节点都操作]
3、删除/usr/local/src/hadoop-2.6.1/dfs/data下面的文件[每个节点都操作]
4、删除/usr/local/src/hadoop-2.6.1/tmp下面的文件[每个节点都操作]
5、删除/usr/local/src/hadoop-2.6.1/logs下面的文件[每个节点都操作]
6、重新格式化hadoop,输入命令:hadoop namenode -format [只在master节点操作]
7、启动集群,./sbin/start-all.sh
#监控网页
在浏览器输入地址:192.168.112.10:8088(这个是master:8088)
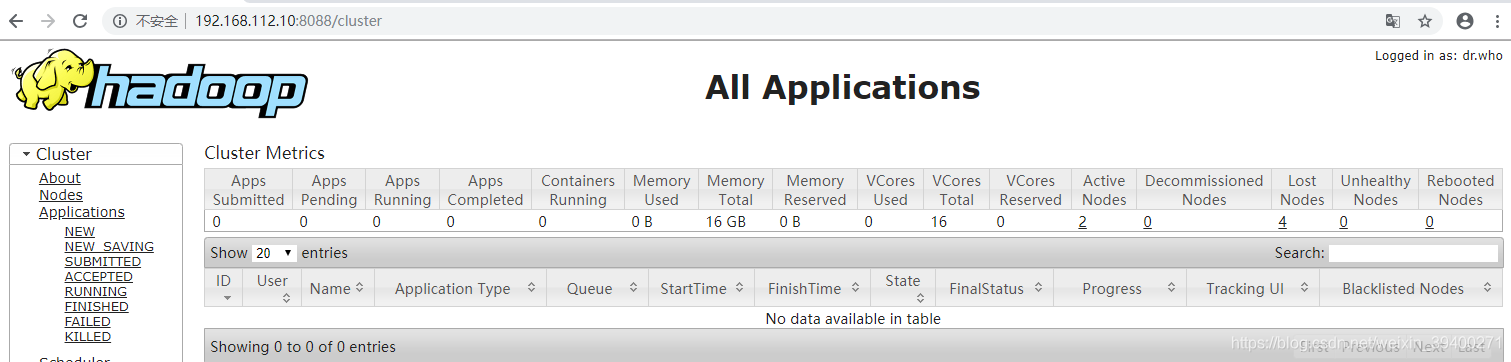
#关闭集群
/usr/local/src/hadoop-2.6.1/sbin/stop-all.sh