正则表达式简介
摘自网上的说法,正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种
逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串
的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
比较常用的基本正则字符
"^" :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。
"$" :$会匹配行或字符串的结尾。
"w":匹配字母,数字,下划线。
例如我要匹配"a2345BCD__TTz" 正则:"w+" 这里的"+"字符为一个量词指重复的次数。
"s":匹配空格。
例如字符 "a b c" 正则:"wswsw" 一个字符后跟一个空格,如有字符间有多个空格直接把"s" 写成 "s+" 让空格重复。
".":匹配除了换行符以外的任何字符。
"[abc]": 字符组,匹配包含括号内元素的字符。
"*": 重复零次或更多(贪婪模式)。
例如"aaaaaaaa" 匹配字符串中所有的a 正则:"a*" 会出到所有的字符"a"。
"+": 重复一次或更多次(懒惰模式)。
例如"aaaaaaaa" 匹配字符串中所有的a; 正则:"a+"会取到字符中所有的a字符,"a+"与"a*"不同在于"+"至少是一次而"*" 可以是0次。
"?": 重复零次或一次。
例如"aaaaaaaa" 匹配字符串中的a 正则 : "a?" 只会匹配一次,也就是结果只是单个字符a。
"{n}": 重复n次。
例如从"aaaaaaaa" 匹配字符串的a 并重复3次 正则:"a{3}" 结果就是取到3个a字符 "aaa"。
"{n,m}": 重复n到m次。
例如正则 "a{3,4}" 将a重复匹配3次或者4次;所以供匹配的字符可以是三个"aaa"也可以是四个"aaaa"正则都可以匹配到。
"{n,}": 重复n次或更多次。
与{n,m}不同之处就在于匹配的次数将没有上限,但至少要重复n次 如 正则"a{3,}" a至少要重复3次。
"*?": 重复任意次,但尽可能少重复。
如 "acbacb" 正则"a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"。
"+?": 重复1次或更多次,但尽可能少重复。
与上面一样,只是至少要重复1次。
"??": 重复0次或1次,但尽可能少重复。
如 "aaacb" 正则 "a.??b"只会取到最后的三个字符"acb"。
"{n,m}?": 重复n到m次,但尽可能少重复。
如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
以上就是正则表达式中最基础的部分知识,也是比较常用的知识点,对于更加复杂部分的内容本文未涉及。其实看多了,慢慢就
知道是什么意思了,就和你一开始对Linux命令不熟悉一样,用多了自然而然就记住了。
利用正则实现关联
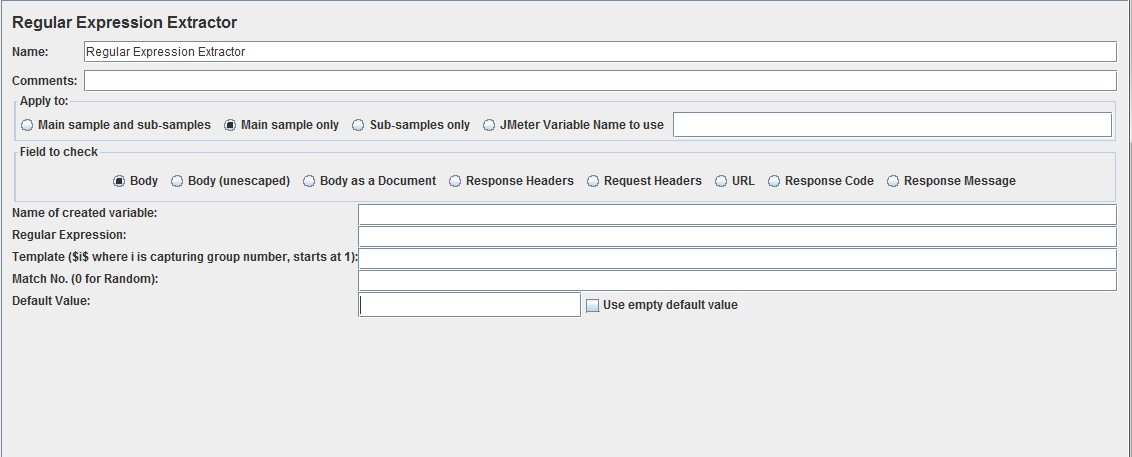
Name of created variable:引用名称,下一个请求要引用的参数名称,如填写num,则可用${num}引用它
Regular Expression:正则表达式,填写编写的正则
Template:模板,用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$,$3$等等,表示解析提取第几个值。如:$1$表示解析到的第1个值
Match No.:匹配数字,可以理解为匹配到结果所出现的次数,比如需要设置匹配数字为1,在JMeter中使用1来表示,通常情况下填0即可
Default Value:缺省值,如果参数没有取到值,那默认给一个值让它取
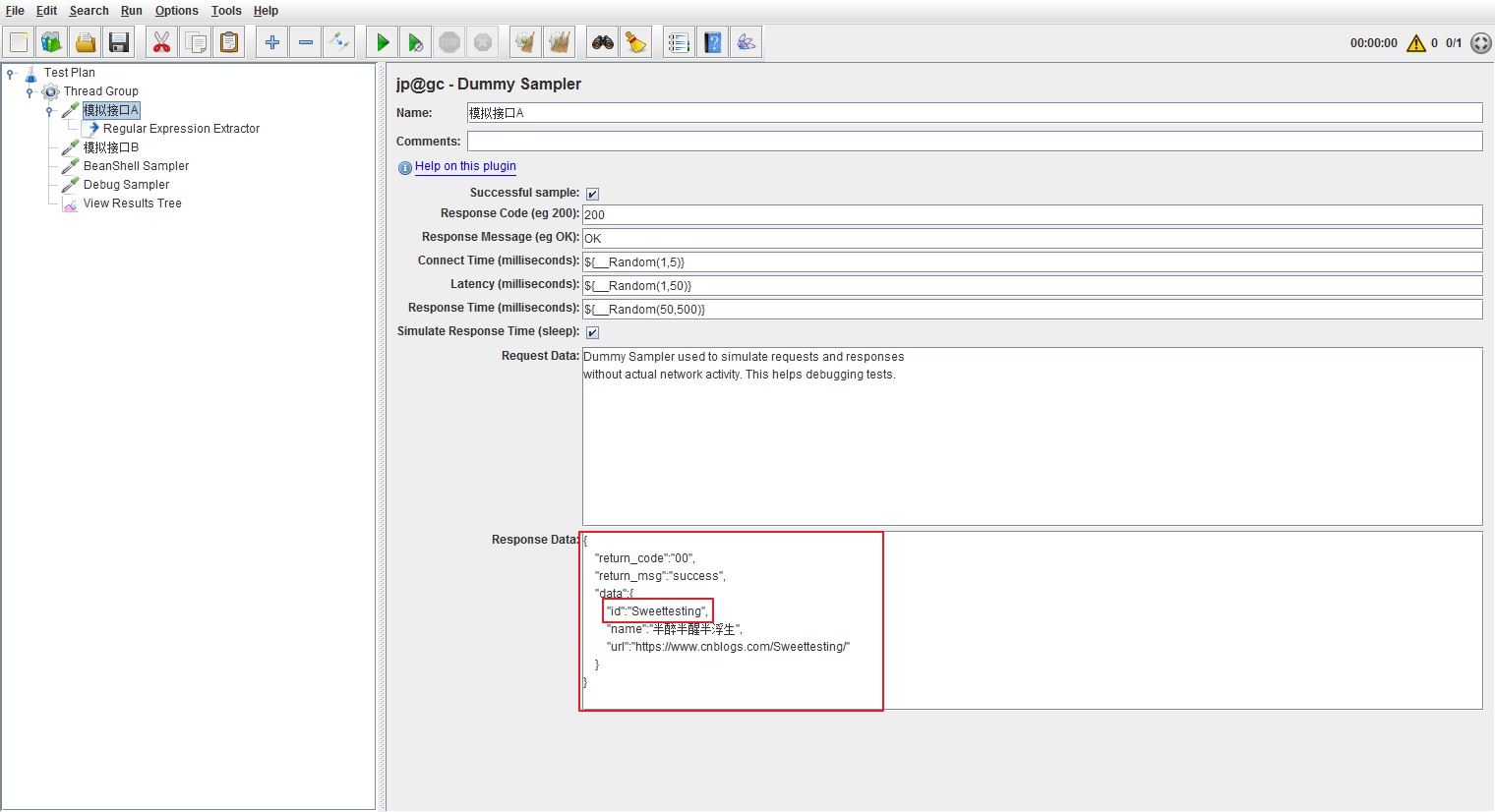
测试场景,现在有接口A、接口B两个接口,接口B需要从接口A中拿到参数“ID”作为自己的入参。此时,我们可以利用Jmeter中的
正则表达式提取器实现这一目标。
配置Jmeter脚本如下,用Dummy Sampler模拟接口A,得到返回结果。
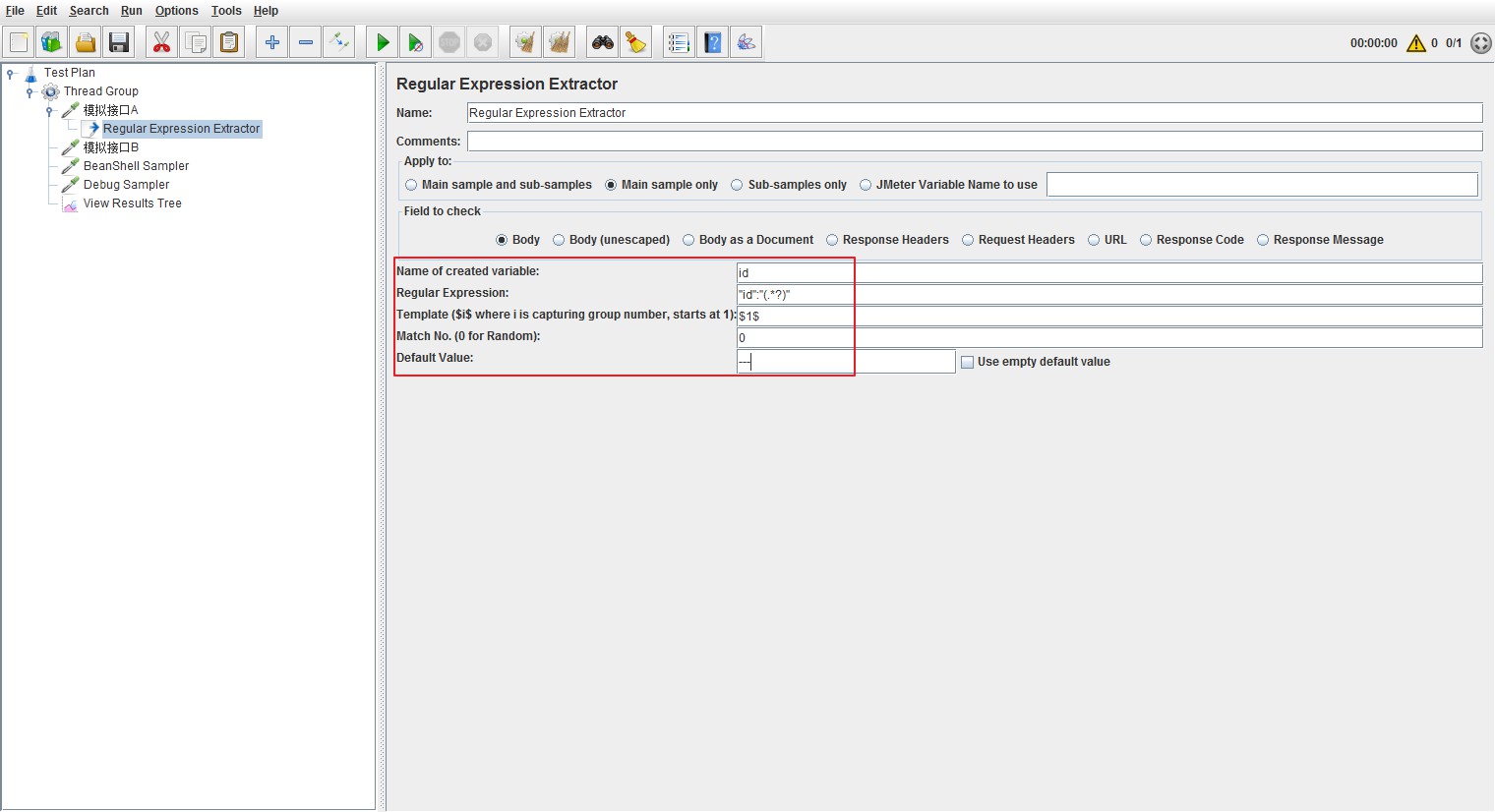
添加正则表达式提取器(Regular Expression Extractor)并做如下配置:
配置接口B,引用从接口A中提取的参数${id}

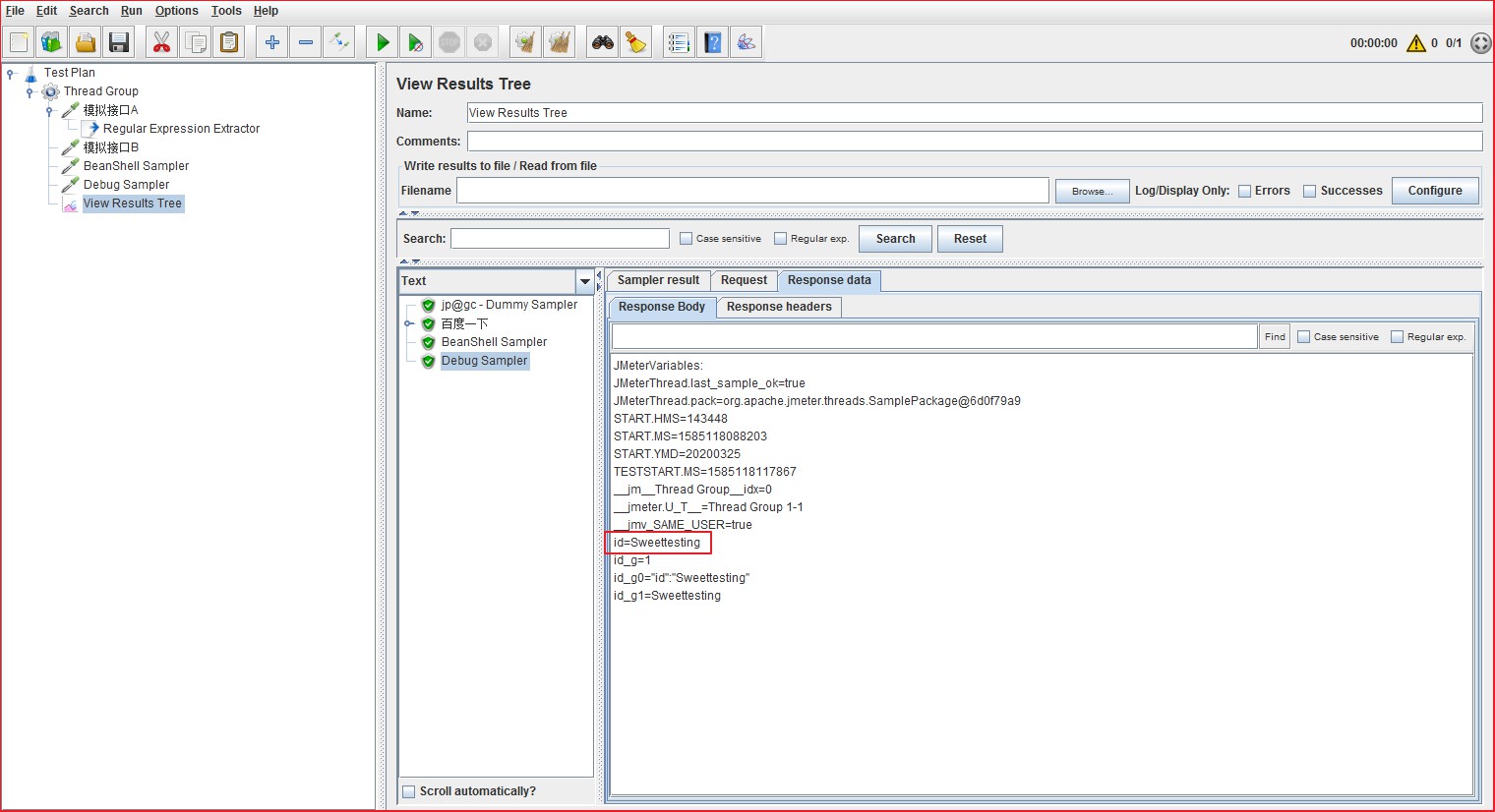
最后,执行并查看结果,可以看到接口A返回结果中的id已经成功获取,这里接口B的执行结果截图省略了。
其中会有个问题,就是我们怎么知道写的正则表达式是否正确匹配了我们要的数据呢?最好的办法当然是先验证一下,省得跑到最后
才发现写的正则有问题,这里给大家推荐一个在线验证正则的工具:http://tool.oschina.net/regex。文笔不好,有错误的地方望大家多多指正。