整合一下能够查到的资料,然后结合自己的理解,算是对这篇文章的一个小小的总结吧。这是CVPR2018的一篇关于小目标检测的文章,出发点是作者认为小目标的检测信息随着层数的增加而不断地丢失了,所以想利用语义分割强化浅层的特征信息(这里强化可能用得不准确,但是我是这么理解的)。整体的网络框架分为三个部分Detection Branch (这里简称DB)+ Segmentation Module (这里简称SM)+ Global Activation Module(这里简称GAM)。SM和GAM本质上都是采用的语义分割的方式增强语义信息并且随着SSD往更高层进行传递。
整体结构框图:
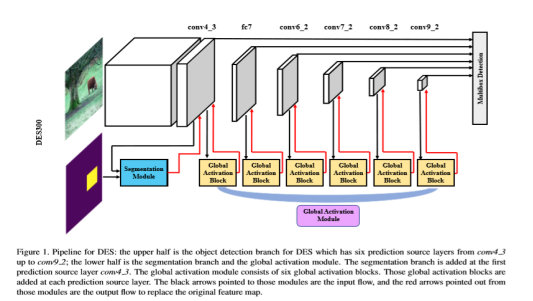
操作过程以DB为主框架:1、在浅层网络中选择SM增强low level特征的语义信息。SM模块的输入是DB主框架的con4_3输出以及用anchor定义的语义分割ground truth, 输出再返回到con4_3作为下一层的输入,这样就可以将低层的语义分割结果融合到高层特征信息中。2、高层通过GAM增强high level的特征语义信息,GAM本质上也就是attention的思想,首先计算特征权重然后根据权重来融合多尺度的特征信息。
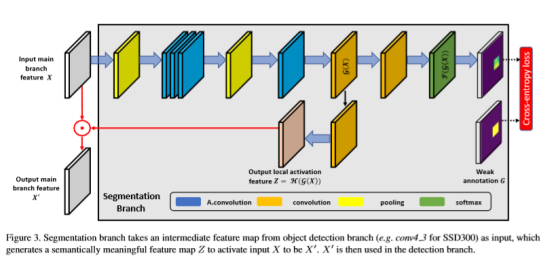
SM模块是这篇论文中重点强调的一个模块,这个部分主要有两个作用,通俗点理解就是产生增强的语义信息并且通过训练使得输出的语义信息增强效果越来越好。其中H支路是输入x在经过4个atrous convolution(既保证了特征图的尺寸不变,也能减少卷积过程中的噪声)卷积之后经过H()函数操作得到类似attention中的mask z,最后x与z做点乘得到,且以为后续检测工作的输入。F支路的作用是利用损失函数训练H支路得到的attention,和分割算法类似,分割算法是针对每个像素点做分类,在F支路中训练所用的ground truth中的每个像素点的标签为对应ground truth框的标签,如果一个像素点同时在多个ground truth框中,则该点的标签为面积最小的那个框的标签,其他情况的点标签都是背景。
网上有一大堆对于sm模块的公式分析,关于通道数以及维度之类的,个人觉得文章中提到的一大串公式里,最能体现出和语义分割关系的是公式:
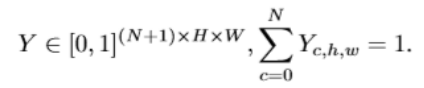
F支路最后的输出Y中每个点的通道数为N+1,这里的特征投影中每个点在所有的channel上的累加和为1,而且值最大的那个点对应的标签就是分割得到的图像中对应点的标签。

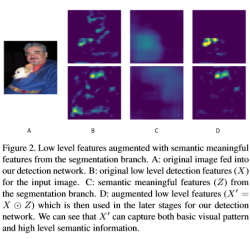
图4表示ground truth的生成方式,图像中像素的标签不需要额外再标注,图2表示segmentation module,A是输入图像,B是输出图像经过特征提取之后的feature map,C是对应的输出Z,D是B和C点乘之后的结果,也就是文章强调的需要增强的小目标的语义特征。
由GAM模块的计算公式就可以很直观的看出来和语义分割非常像,这个模块主要包含三个操作:spatial pooling相当于给输入的特征图做了归一化处理,而channel-wise learning则是利用两层激活函数突显了特征图的权重信息,最后的broadcasted multiplying将S和输入x点乘得到最后的输出,类似于attention的思想。
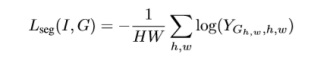
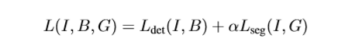
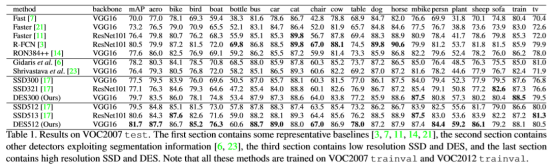
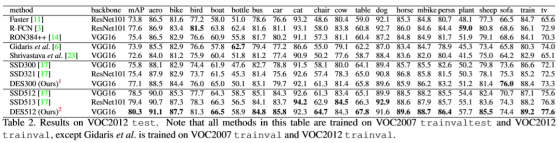
整个损失函数包括检测的损失函数和分割损失函数,分割的损失函数就是文章设计的SM模块中的训练损失函数。整体实验效果虽然比同年CVPR的另外一篇文章低一点,但是结果还是很好的。