本文系 T-Sql技术内幕系列读后感。
用过数据库的程序猿都知道,索引可以极大的优化sql语句的执行时间,但是您要问我,怎么减少的,我只能说:"抱歉,我也不太清楚。"
带着这个疑惑,我重读了技术内幕,分享一点书上的所得。
我们先来建2个表,然后塞几条数据。
create table Customers ( CustomerID int, Cite varchar(20) ) insert into Customers(CustomerID,Cite) values (1,'Shanghai') insert into Customers(CustomerID,Cite) values (2,'Beijing') create table Orders ( CustomerID int, OrderID int ) insert into Orders(CustomerID,OrderID) values(1,11) insert into Orders(CustomerID,OrderID) values(1,12) insert into Orders(CustomerID,OrderID) values(2,13)
这2个表数据很简单:
A表有客户1,所在cite="Shanghai",客户2,所在Cite="Beijing"。
B表有客户1的OrderID=11,12两条订单数据,有客户2的OrderID=13的订单数据。
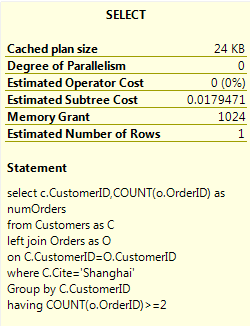
我们根据上面的数据写如下Sql语句,再看下执行计划。
select c.CustomerID,COUNT(o.OrderID) as numOrders from Customers as C left join Orders as O on C.CustomerID=O.CustomerID where C.Cite='Shanghai' Group by C.CustomerID having COUNT(o.OrderID)>=2
数据流的顺序如下图。
1.表扫描花费18%的开销,然后Sort花费63%的开销。

那我们在来看下,整个sql语句消耗多长时间。0.017s
我们给客户表和订单表建上聚集索引。
create clustered index pk_Customer on Customers(CustomerID) create clustered index pk_Customer_Order on Orders(CustomerID,OrderID)
然后再执行上面的Sql语句,得到下面的执行计划。

通过上述操作,我们发现,总时间只用0.006s了。
对于这条Sql,增加索引为我们减少了(0.017-0.006)/0.006=183%
原来增加索引,可以减少内部数据排序的时间,从来减少开销。
最后让我们看下这个结论是否正确,让我们再次回到第一个执行计划上,把鼠标放在Sort上,看他的开销。
消耗时间0.11s
