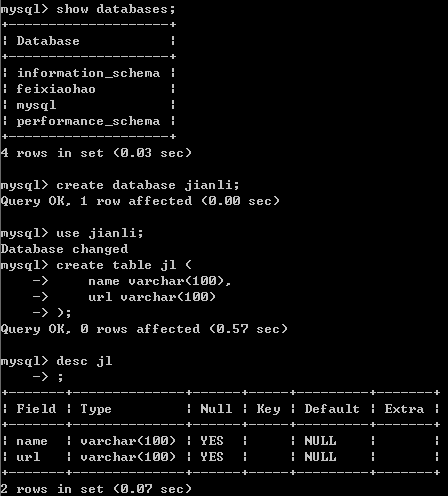
首先,MySQL创建好数据库和表
然后编写各个模块
item.py
import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() url = scrapy.Field()
pipeline.py
import pymysql #导入数据库的类 class JianliPipeline(object): conn = None cursor = None def open_spider(self,spider): print('开始爬虫') self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='jianli') #链接数据库 def process_item(self, item, spider): #编写向数据库中存储数据的相关代码 self.cursor = self.conn.cursor() #1.链接数据库 sql = 'insert into jl values("%s","%s")'%(item['name'],item['url']) #2.执行sql语句 try: #执行事务 self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self,spider): print('爬虫结束') self.cursor.close() self.conn.close()
spider
# -*- coding: utf-8 -*- import scrapy import re from lxml import etree from jianli.items import JianliItem class FxhSpider(scrapy.Spider): name = 'jl' # allowed_domains = ['feixiaohao.com'] start_urls = ['http://sc.chinaz.com/jianli/free_{}.html'.format(i) for i in range(3)] def parse(self,response): tree = etree.HTML(response.text) a_list = tree.xpath('//div[@id="container"]/div/a') for a in a_list: item = JianliItem ( name=a.xpath("./img/@alt")[0], url=a.xpath("./@href")[0] ) yield item
settings.py
#USER_AGENT headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36" } # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'jianli.pipelines.JianliPipeline': 300, }
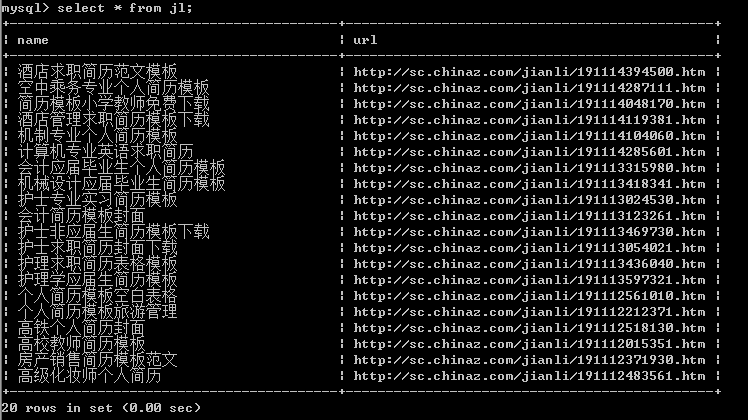
查看存储情况