1、Github项目
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 820 | 1220 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 220 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 | 20 | 25 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 360 | 620 |
| · Code Review | · 代码复审 | 80 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 180 | 180 |
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 110 |
| | 合计 | 1030|1430
3、解题思路
-
题目:
-
统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符 -
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号 -
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
-
输出的单词统一为小写格式
-
输出的格式为:
characters: number words: number lines: number <word1>: number <word2>: number ... -
-
思路
刚拿到题目的时候是有点懵逼的,一想文本里各种符号啥的,就有点害怕。后来,不断地挖掘题目,思路也就渐渐清楚起来了。我的想法是给自己分成好几步,也正是软件体系结构里所说的,对一个复杂的问题解决转化为对若干个更小问题的解决来实现。资料以网上查找,教程和博客为主。我把该问题分为以下几步:
- 解决“命令行测试程序使用”问题以及构造好项目的代码组织结构(因为之前还没有过使用c++项目和命令行测试的经验)。
- 完成CountLines和CountChars的功能:查询c++中字符串的相关用法,使用getline(istream &in, string &s)一行行获取文本,同时加入无效行的判别,实现文本中行数的计算。字符数统计则是通过每一行的字符数相加得到的,这里需注意无效行存在的换行符等也应算入字符总数,最后一行的结束符也会被统计入末行的字符数,所以算得的总字符数应减一。
- 完成CountWords和WordFrequency的功能:单词的切割问题是该题比较复杂的地方,我是通过文件流一次读取一串连续的字符(以空格、换行符为切割符)。然后通过CutWords()(代码在下面)实现单词的切割,以及去除不合法的“单词”和字符,取得一个合法字符就加入计数和保存单词到word字符串数组。通过C++ STL中的sort结合cmp()自定义函数来实现word字符串数组的排序。排序后开始统计单词的出现次数,存在wordFrequency定义的结构体数组wordFre中,再对wordFre数组使用sort结合cmp2()排序。
3、设计实现过程。
-
代码组织依题意如下:

-
它们之前的关系图如下:
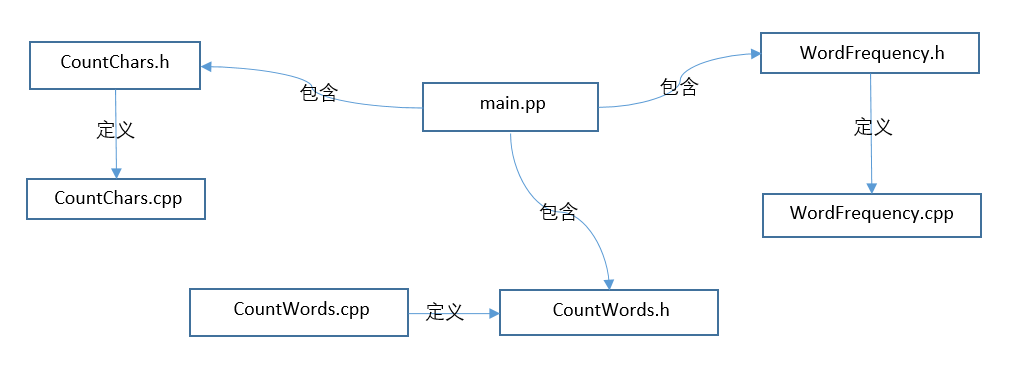
-
其中仅CutWord函数比较繁琐,流程图如下:

-
单元测试

4、改进程序方面
-
改进的思路
- 发现暴力切割单词比较繁琐,可以通过正则来实现单词的切割,但是C++的正则写起来显得有些吃力,正在努力使用正则改进中。
- 在编译原理课上又讲到有穷自动机,也看到有同学已经使用其实现单词的合法判断,统一正在努力使用DFA改进代码中。
- 在统计完单词的出现次数后使用大根堆或者优先队列维护出现次数最高的十个单词,可以有效的改善些词频统计的性能,正在努力改进中。
- 我的单词使用字符串数组储存,需事先开好字符串数组的大小,开小大文件会出现越界,开大程序运行小文件时显得非常慢,正在思考如何改善,目前综合考虑字符串数组取1000010。
-
性能分析图
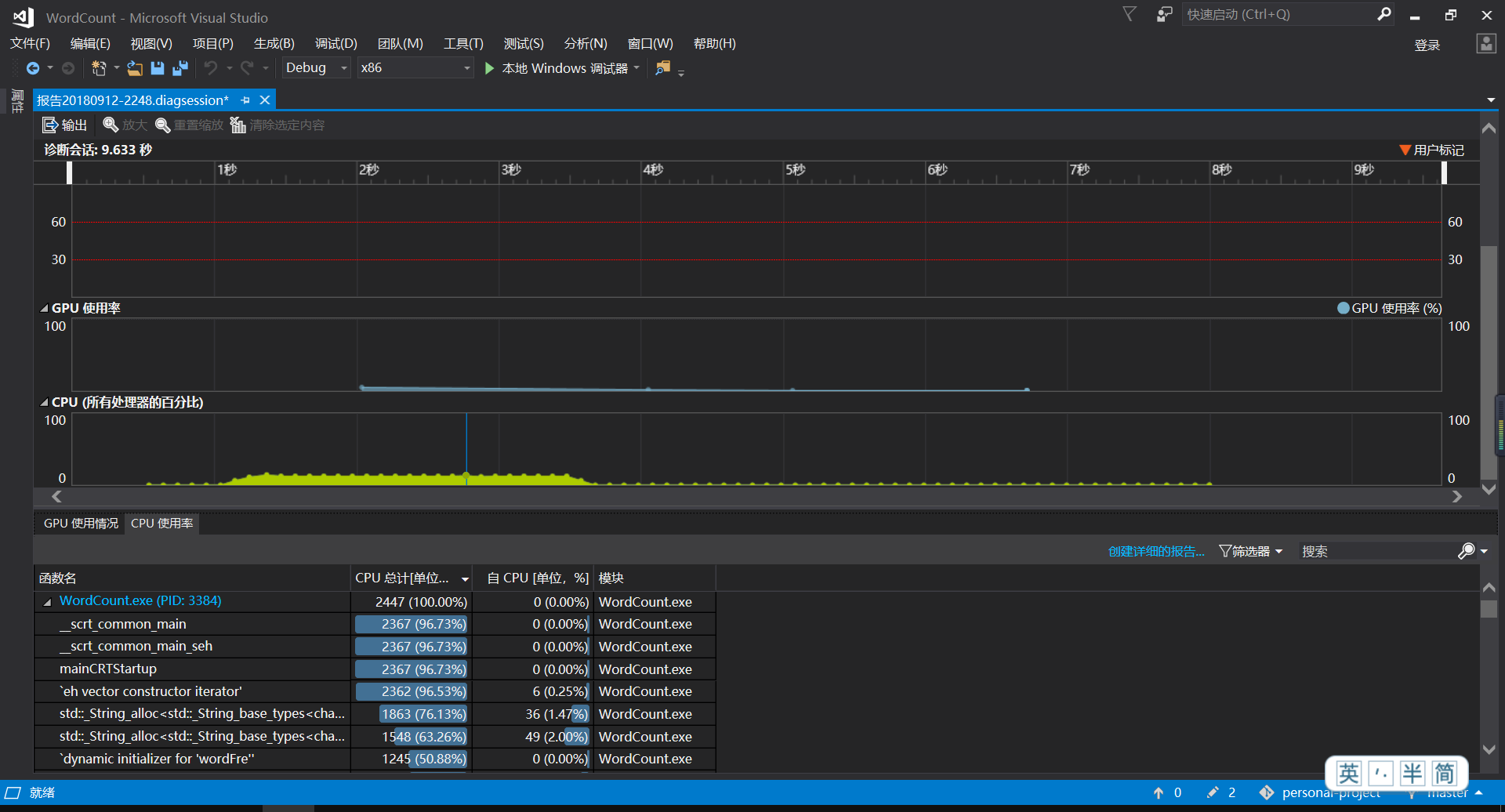
-
代码覆盖率
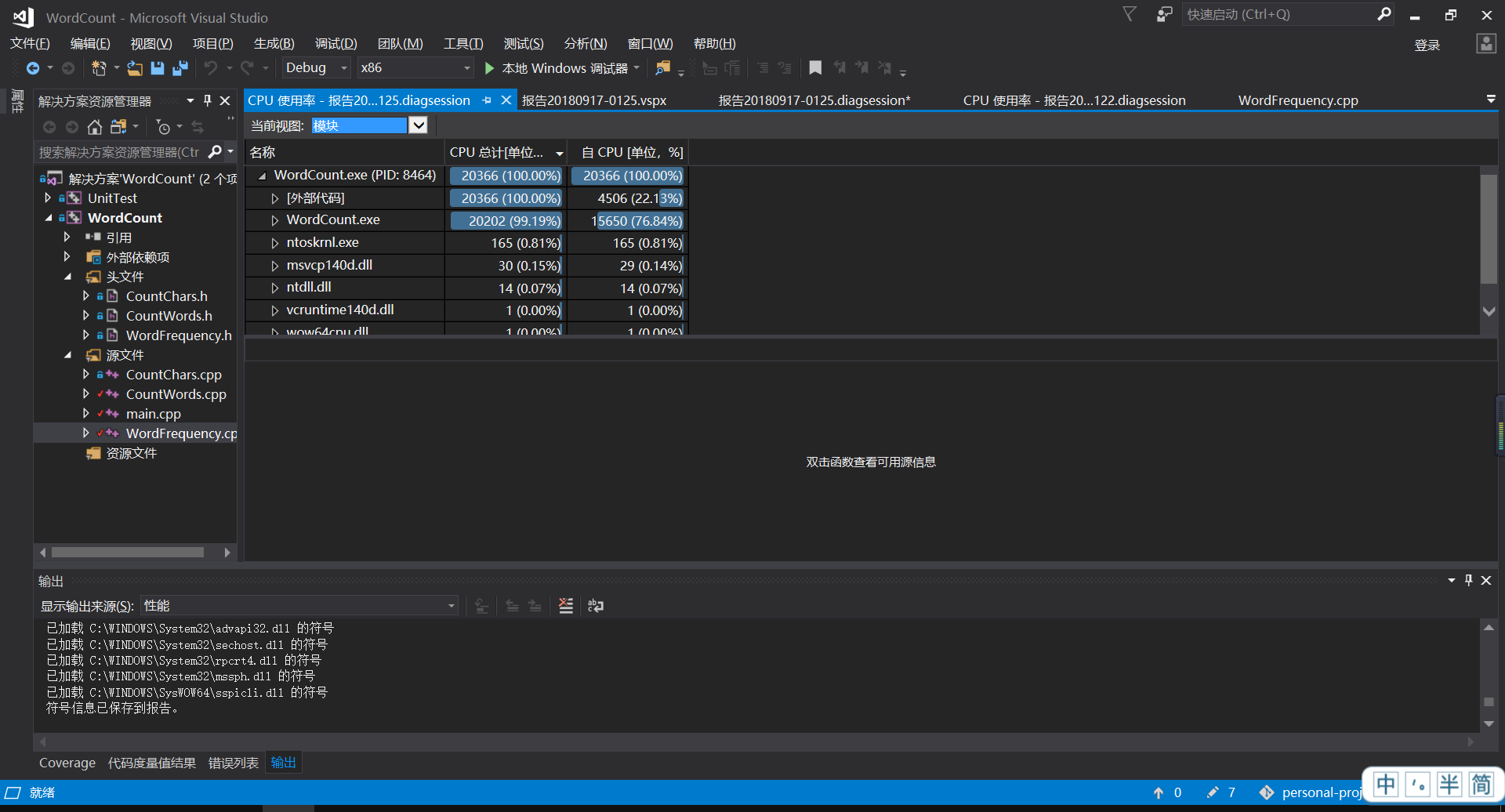
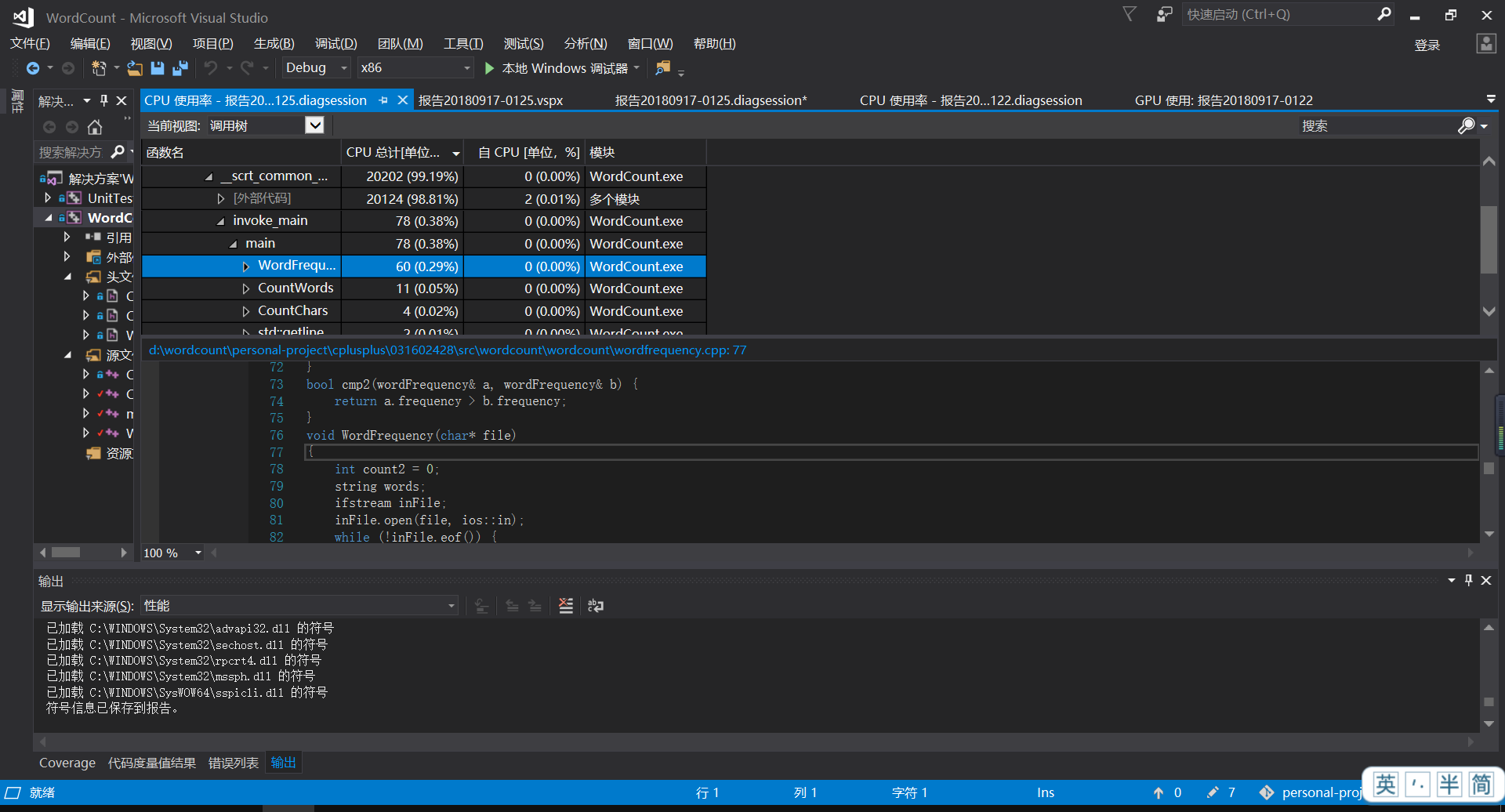
可以看出,消耗最大的函数就是WordFrequency这个接口,用于统计词频,具体代码在下面,复杂度为
N*log2(N),其中N为单词数。
5、代码说明。展示出项目关键代码,并解释思路与注释说明。
- 两个用于排序的cmp函数
bool cmp(string a, string b)
{
return a.compare(b) < 0;
}
bool cmp2(wordFrequency& a, wordFrequency& b) {
return a.frequency > b.frequency;(```)
}
- 用于CountWords中的CutWord函数
int CutWord(string words)
{
string temp;
temp.resize(words.length());
int count = 0;
int tempi = 0;
if (words.length() < 4) return 0;
for (int i = 0; i < (int)words.length(); i++)
{
if (tempi < 4 && ( ('a' <= words[i] && words[i] <= 'z') || ('A' <= words[i] && words[i] <= 'Z') ) ) {
temp[tempi++] = words[i];
if (i == words.length() - 1) count++;
}
else if (tempi >= 4) {
if (('a' <= words[i] && words[i] <= 'z') || ('A' <= words[i] && words[i] <= 'Z') || ('0' <= words[i] && words[i] <= '9')) {
temp[tempi++] = words[i];
if (i == words.length() - 1) count++;
}
else {
count++;
if (i + 4 >= (int)words.length()) {
//cout << words << "1:" << count << endl;
return count;
}
tempi = 0;
}
}
else {
if (i + 4 >= (int)words.length()) {
//cout << words << "3:" << count << endl;
return count;
}
tempi = 0;
}
}
//cout << words << "2:" << count << endl;
return count;
}
其中count++的地方在WordFrequency中更改为:
temp.resize(tempi);
word[++cnt] = SwitchToLower(temp);
- 单词转化为小写
string SwitchToLower(string words)
{
int len = words.length();
for (int i = 0; i < len; i++)
{
if ('A' <= words[i] && words[i] <= 'Z')
words[i] += 32;
}
return words;
}
- 统计字符数
int CountChars(char* file)
{
int count = 0;
string temp;
ifstream inFile(file);
while (getline(inFile, temp)) {
for (int i = 0; i < (int)temp.length(); i++)
if (isascii(temp[i])) count++;
count++;
}
if (count > 1) count--;
inFile.close();
return count;
}
- 异常处理
int ExceptionJudge(int argc, char* argv[]) {
if (argc == 1) printf("It is short of filename!
");
else if (argc > 2) printf("Too many parametes!
");
else {
char* file = argv[1];
int len = strlen(file);
if (len < 4) {
printf("The file name entered is in an incorrect format!
");
return -1;
}
else if (file[len - 1] == 't' && file[len - 2] == 'x' && file[len - 3] == 't' && file[len - 4] == '.') {
fstream fs(argv[1]);
if (!fs.is_open()) printf("Fail to open file!
");
else return 0;
}
else printf("The file name entered is in an incorrect format!
");
}
return -1;
}
6、结合在构建之法中学习到的相关内容与个人项目的实践经历,撰写解决项目的心路历程与收获。
由于时间原因,此次个人项目中新学的东西太多,并没有时间开始看构建之法。在这次个人项目中新学习了git(因为之前碰过,环境乱七八糟,搞了好多个小时才完成)、github管理、Visual studio的使用、C++项目的组织和构建(之前只使用了单个程序,并没有使用过项目结构和接口封装)。真的累,花了很多时间,但是感觉项目还是有很多可以改善的地方,有时间的话还会继续完善的,收获的东西真不少。