暂停爬虫项目
首先在项目目录下创建一个文件夹用来存放暂停爬虫时的待处理请求url以及其他的信息.(文件夹名称:job_info)
在启动爬虫项目时候用pycharm自带的终端启动输入下面的命令:
scrapy crawl (爬虫名) -s JOBDIR=job_info/(再让其自动的创建一个文件夹用于存放不同的爬虫重启与暂停时的信息[不同的爬虫在暂停时不能共用同一个目录来存放暂停信息,重启同理.],名称随便起[例如:001].)
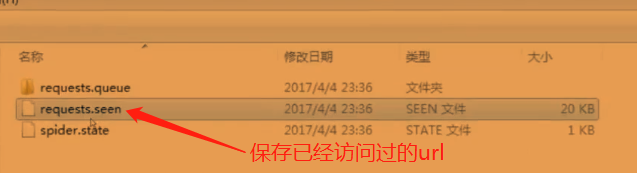
该命令运行后按下一次ctrl+c后scrapy接收到一次暂停的信号注意这里只能按一次ctrl+c如果按了两次就表示强制退出了.下图中展示了暂停时收集的信息并将生成的信息存放到预先指定的目录中去.其实目录下的文件保存的就是暂停后没有处理掉的请求url.,

存放暂停信息的目录中下的文件如图所示:
重启爬虫项目
重启爬虫项目的命令和暂停时的是一样的只是首次请求的url地址不一样了,如果想重新启动爬虫程序,在JOBDIR后面重新指定文件夹即可例如:
scrapy crawl (爬虫名) -s JOBDIR=job_info/002
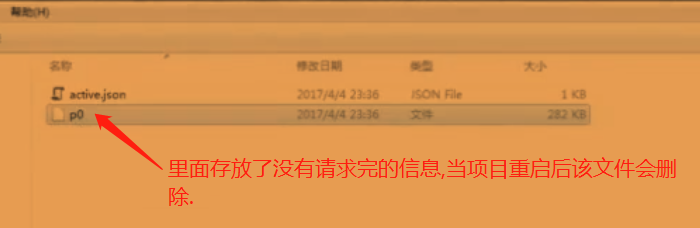
下图中展示了未请求完的信息文件.
scrapy 项目的暂停与重启用法介绍完成.